英伟达开源双塔语言模型 TwoTower:扩散架构加速 LLM Token 生成

英伟达昨日开源 Nemotron-Labs-TwoTower 扩散语言模型,采用双塔架构将上下文理解与去噪生成分离,在保留 98.7% 质量的前提下实现 2.42 倍吞吐量提升,为大规模文本生成场景提供新的性能优化路径。
英伟达开源双塔语言模型 TwoTower:扩散架构加速 LLM Token 生成
英伟达昨日(7 月 2 日)正式开源了 Nemotron-Labs-TwoTower,这是一个基于预训练自回归骨干网络的离散扩散语言模型。在各家厂商卷模型能力的当下,英伟达这次选择了一个不太一样的切入点:不追求更高的 benchmark 分数,而是直接瞄准 Token 生成速度这个大模型推理的核心瓶颈。
从实测数据看,效果确实明显。在 2×H100 GPU 环境下,TwoTower 保留了基线模型 98.7% 的质量表现,但实际运行时吞吐量提升了 2.42 倍。对于需要批量生产合成数据、做大规模文本生成的团队来说,这个提升幅度已经足够有吸引力——同样的硬件成本,产出翻倍。
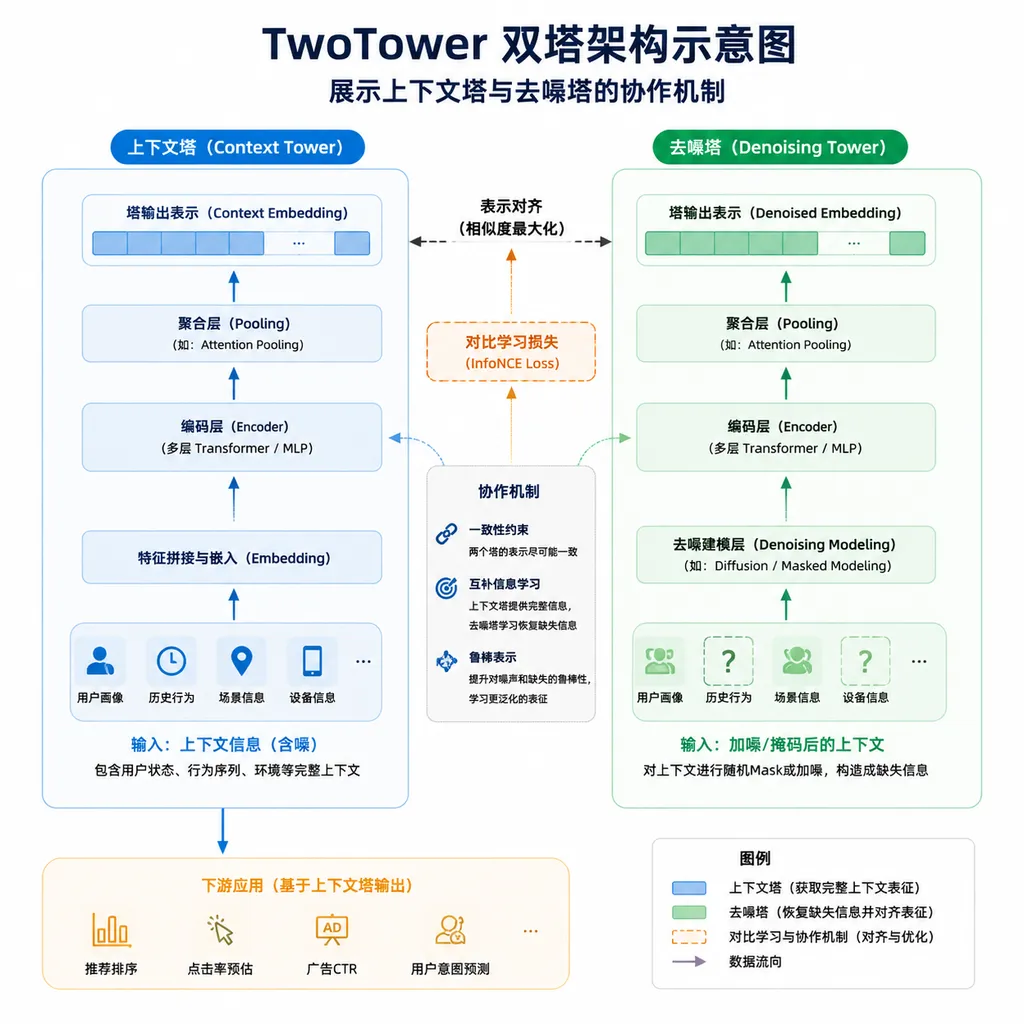
双塔架构:把上下文理解和去噪生成拆开做
TwoTower 最核心的创新在于架构设计。传统自回归模型生成文本时,必须逐个 Token 串行解码,每一步都要重新计算完整的上下文表示。这在处理长文本或大批量任务时,串行解码成为明显的性能天花板。
英伟达的解法是把任务拆成两个独立的神经网络"塔":
-
上下文塔(Context Tower):保持冻结状态,专注于处理输入提示词并维护文本的自回归上下文。这个塔实际上就是原始的 30B 自回归模型,参数不动,保留了原有的语言理解能力。
-
去噪塔(Denoiser Tower):经过专门训练,负责对噪声块进行并行去噪。这个塔同样是 30B 参数规模,但采用了 MoE(混合专家)架构,128 个可路由专家中每次只激活 3B 参数。
两个塔通过逐层交叉注意力(cross-attention)连接协作。上下文塔提供稳定的语义表示,去噪塔在这个基础上并行生成多个 Token 块,而不是一个一个蹦。这种设计让模型能够在保持质量的前提下,大幅提升并行度。
60B 总参数,但每次只激活 3B
TwoTower 的总参数规模是 60B——两个 30B 的塔加起来。但实际推理时,由于采用了 MoE 架构,每个塔只激活 3B 参数。这意味着虽然模型容量大,但实际计算开销并没有想象中那么夸张。
这种设计在显存和算力之间找到了一个平衡点。一方面,60B 的总参数量保证了模型的表达能力;另一方面,3B 的激活参数让推理速度保持在可接受范围内。根据英伟达的说法,这个模型可以在 RTX 4090 这样的消费级显卡上跑起来,虽然对显存有一定要求,但并非只能在数据中心级硬件上才能用。
模型支持三种解码方式,灵活性很高:
- 扩散模式:完整的块级并行去噪,性能最优但质量略有损失
- 模拟 AR 模式:双塔协作但保持自回归生成,质量接近原始基线
- 标准 AR 模式:纯自回归解码,作为性能基准参考
开发者可以根据具体任务在质量和速度之间做权衡。默认工作点是"置信度解掩码",设置阈值 γ = 0.8、块大小 S = 16,这个配置下质量保留 98.7%,吞吐量提升 2.42 倍。如果降低置信度阈值,会进一步提升速度,但质量会相应下降。
性能表现:大部分任务接近基线,代码和数学略弱
从 benchmark 数据看,TwoTower 在大部分通用任务上的表现都很接近自回归基线。MMLU、ARC-Challenge、WinoGrande、RACE 等任务的准确率基本持平,有的甚至还略有提升。
但在代码生成(HumanEval)和数学推理(MATH-500)这两个任务上,性能有轻微回落。HumanEval 从 79.27% 降到 75.58%,MATH-500 从 84.40% 降到 80.60%。这个下降幅度不算大,但对于需要高精度推理的场景来说,可能还是会倾向于用传统自回归模型。
| 任务 | AR 基线 | TwoTower 扩散 | |------|---------|---------------| | MMLU (5-shot) | 78.56 | 78.24 | | MMLU-Pro (5-shot CoT) | 62.59 | 60.93 | | ARC-Challenge (25-shot) | 91.72 | 92.66 | | WinoGrande (5-shot) | 76.09 | 76.09 | | RACE (0-shot) | 88.90 | 88.90 | | HumanEval (0-shot) | 79.27 | 75.58 | | MBPP-Sanitized (3-shot) | 74.71 | 74.28 | | GSM8K (8-shot) | 92.49 | 90.14 | | MATH-500 (4-shot) | 84.40 | 80.60 | | 质量保留率 | 100% | 98.7% | | 生成吞吐量 | 1.0× | 2.42× |
这个结果其实挺符合预期的。扩散模型本质上是在做概率分布的采样,对于需要严格逻辑推理的任务,确实不如逐步推导的自回归模型稳定。但对于大部分文本生成场景——比如内容创作、数据合成、对话生成——这点质量损失完全可以接受,速度提升带来的收益更大。
训练策略:只训练去噪塔,上下文塔保持冻结
TwoTower 的训练方式也值得说一下。模型是基于英伟达自家的 Nemotron-3-Nano-30B-A3B 骨干网络构建的,这个基线模型本身就是在约 2.1 万亿 Token 上预训练的。
在 TwoTower 的训练过程中,上下文塔(也就是原始的自回归模型)保持冻结,只训练去噪塔。这种设计有几个好处:
- 训练成本低:不需要重新训练整个 60B 参数模型,只训练新增的去噪塔部分
- 保留原有能力:上下文塔的语言理解能力完全继承自基线模型,不会因为新任务训练而产生灾难性遗忘
- 灵活性高:理论上可以把任何自回归模型的上下文塔换进来,快速适配成双塔架构
英伟达提到,上下文塔"可选为可训练",但在这次开源版本中选择保持冻结。这可能是出于简化训练流程的考虑,也可能是为了让社区能够更容易地在不同基线模型上做实验。
去噪塔的训练数据来源与基线模型相同,都是从 Nemotron 的两阶段混合数据中抽取的子集。具体的数据配比和清洗策略英伟达没有公开,但从结果看,训练出来的去噪塔在大部分任务上都能很好地配合上下文塔工作。
开源协议和使用门槛
TwoTower 以开源权重形式在 Hugging Face 平台发布,授权协议是 NVIDIA Nemotron Open Model License。这个协议允许商业使用,但有一些限制条款——比如不能用于训练竞品模型、需要在衍生作品中注明来源等。整体上比 Apache 2.0 要严格一些,但对于大部分应用场景来说不是问题。
使用门槛方面,模型本身对硬件有一定要求。虽然每次只激活 3B 参数,但 60B 的权重还是要全部加载到显存里。根据社区反馈,如果用 BF16 精度跑,至少需要 80GB 显存(比如 A100 或 H100)。如果做 FP8 或 INT4 量化,可以降到 40GB 左右,这样 RTX 4090(24GB)配合 CPU offloading 也能跑起来,只是速度会打折扣。
英伟达提供了简单的代码示例,可以快速上手:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = \"nvidia/Nemotron-TwoTower-30B-A3B-Base-BF16\"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 把两个塔分别放到不同 GPU 上
model.place_towers_on_devices(\"cuda:0\", \"cuda:1\")
prompt = \"Once upon a time\"
inputs = tokenizer(prompt, return_tensors=\"pt\").to(\"cuda:0\")
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0][inputs[\"input_ids\"].shape[1]:], skip_special_tokens=True))
这个 API 基本和标准的 Hugging Face Transformers 兼容,唯一的新增方法是 place_towers_on_devices(),用于手动控制两个塔的设备分配。如果显存够大,也可以全部放在一块 GPU 上。
扩散模型在 LLM 领域的新探索
TwoTower 并不是第一个把扩散模型用在语言生成上的尝试,但它是目前开源方案中工程化程度最高的之一。
扩散模型在图像生成领域已经证明了自己的价值——Stable Diffusion、DALL-E 等模型都是基于扩散架构。这类模型的核心优势是可以并行生成,而不是像 GAN 那样需要复杂的对抗训练,也不像自回归模型那样只能串行输出。
但在语言生成上,扩散模型一直没有大规模商用。主要原因是离散 Token 的去噪比连续像素的去噪要难得多,而且文本生成对逻辑一致性的要求比图像高。早期的扩散语言模型(比如 Diffusion-LM)在质量上明显不如自回归模型,速度优势也不明显。
英伟达这次的双塔设计算是找到了一个比较好的折中方案:用冻结的自回归模型来保证上下文的连贯性,用训练的扩散模型来加速生成。这样既保留了自回归模型的质量,又获得了扩散模型的并行性。
谷歌前段时间也开源了一个类似的扩散语言模型,260 亿参数的 MoE 架构,号称在 GPU 上生成速度可以达到自回归模型的 4 倍。但那个模型是完全从头训练的扩散架构,没有保留自回归骨干,所以在某些任务上质量损失比较明显。相比之下,TwoTower 的双塔设计在质量和速度之间找到了更好的平衡点。
适用场景:数据合成和批量生成
TwoTower 最适合的场景是需要大规模批量生成文本的任务,比如:
- 合成训练数据:用模型生成大量标注数据来训练下游任务,速度提升直接降低数据生产成本
- 内容创作辅助:批量生成文章大纲、产品描述、营销文案等,人工筛选后再精修
- 对话系统:多轮对话中快速生成候选回复,然后用排序模型选择最佳输出
- 代码注释生成:给大规模代码库批量添加文档注释,质量要求不需要特别高
对于需要高精度推理的场景——比如竞赛级数学题、复杂代码生成、法律文档分析——传统自回归模型可能还是更稳妥的选择。但对于大部分应用来说,98.7% 的质量保留率已经足够,速度翻倍带来的成本优势更实际。
另一个值得关注的点是,TwoTower 的训练成本相对较低。如果你已经有一个训练好的自回归基线模型,可以直接在上面加一个去噪塔,只训练新增部分。这对于想要优化自家模型推理性能的团队来说,是一个性价比很高的方案。
OpenAI Hub 已支持主流模型
对于开发者来说,直接部署和调优 60B 参数模型的门槛还是不低。如果只是想快速验证扩散架构在自己业务场景下的效果,可以考虑使用 API 聚合平台。OpenAI Hub 这类服务提供了统一的 API 接口,一个 Key 就能调用包括 GPT、Claude、Gemini、DeepSeek 等主流模型,国内直连,兼容 OpenAI 格式。虽然目前 TwoTower 还没上线商业 API,但随着扩散语言模型逐渐成熟,未来应该会有更多类似架构的模型提供云服务。
写在最后
英伟达这次开源 TwoTower,算是给大模型推理优化提供了一个新的思路。不是简单地堆硬件、加显存,而是从算法架构层面做创新,用双塔设计把质量和速度的平衡做到了一个新的水平。
98.7% 的质量保留率配合 2.42 倍的吞吐量提升,对于成本敏感的应用场景来说,这个性价比已经很有吸引力了。虽然在代码和数学推理上还有提升空间,但对于大部分文本生成任务来说,这个权衡是值得的。
更重要的是,开源意味着社区可以在这个基础上继续迭代。可以预见,接下来会有人尝试把 TwoTower 的架构移植到更大规模的模型上,或者在去噪塔上做更激进的优化。扩散模型在语言生成领域的探索才刚刚开始,TwoTower 只是一个开头。
参考来源
- 英伟达开源 TwoTower AI 模型:保留 98.7% 质量,Token 生成提速 2.42 倍 - IT之家 —— 英伟达官方博文的中文报道,包含详细的性能测试数据和架构说明


