百度伐谋2.0二度登顶MLE-Bench,5月正式发布

百度伐谋Agent 2.0再次刷新OpenAI主导的MLE-Bench基准SOTA成绩,这是继2025年10月后第二次登顶。正式版将于5月Create 2026大会发布,标志着国内AI工程化能力进入新阶段。
百度伐谋Agent 2.0又拿下MLE-Bench全球第一了。
这已经是第二次。上一次是2025年10月,百度智能云的这个企业级算法自主优化智能体首次登顶该榜单。时隔半年,2.0版本卷土重来,再次刷新SOTA成绩。正式版本定档今年5月的Create 2026百度AI开发者大会。
消息本身不算意外,但值得认真聊聊——因为MLE-Bench这个榜单的含金量,以及它背后折射出的AI行业竞争焦点转移。
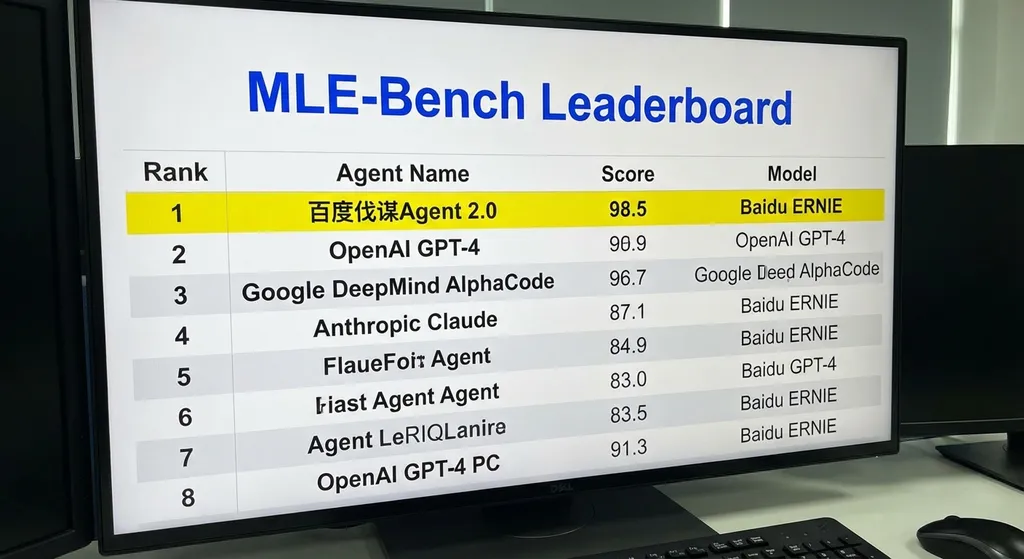
MLE-Bench到底在考什么
先说榜单本身。MLE-Bench由OpenAI主导设立,不是那种刷分就能上去的学术排行榜。它包含75个来自Kaggle竞赛的真实机器学习工程难题,覆盖数据预处理、特征工程、模型选择、超参调优、训练部署等完整ML pipeline。
换句话说,这不是考你模型能不能写出一段漂亮的代码,而是考你的AI Agent能不能像一个资深ML工程师一样,拿到一个真实的Kaggle赛题,从头到尾独立完成整个解题过程——读数据、分析问题、选方案、写代码、调参数、提交结果,全程自主决策。
这跟我们平时聊的"大模型能力"是两回事。大模型的benchmark(MMLU、HumanEval之类)更多测的是模型本身的知识储备和推理能力,相当于笔试。MLE-Bench测的是Agent的工程实操能力,相当于实操考试——你不光要知道怎么做,还得真的做出来,而且做得好。
75道题,每道都是真实Kaggle竞赛,有真实的评分标准。Agent需要在限定时间和资源内,自主完成从数据探索到模型提交的全流程。最终成绩按照能达到Kaggle铜牌水平的题目比例来算。
这个设定很刁钻。Kaggle竞赛的铜牌线通常意味着你的方案至少要超过大部分人类参赛者。对一个AI Agent来说,这要求它不仅能写代码,还得具备工程直觉——什么时候该用什么模型、数据长什么样该怎么处理、哪些特征值得花时间去构造。
两次登顶,含义不同
2025年10月第一次登顶的时候,行业的反应更多是"哦,百度也能做Agent"。坦率说,当时大家的注意力都在大模型本身的参数竞赛上,Agent还没有成为主流叙事。
但这次2.0版本再度登顶,语境完全不同了。
过去半年,AI行业的风向发生了明显转变。从去年底开始,几乎所有头部厂商都在讲Agent、讲工程化、讲落地。原因很简单:大模型的能力提升曲线在放缓,光靠堆参数和训练数据已经很难拉开差距。真正的竞争壁垒,正在从"模型能力"转向"工程能力"——也就是怎么把模型能力转化为实际可用的生产力工具。
MLE-Bench恰好卡在这个关键位置上。它测的不是模型聪不聪明,而是Agent能不能干活。百度伐谋能在这个榜单上两次拿第一,说明至少在ML工程这个垂直领域,它的自主决策和执行能力确实是全球顶尖的。
而且要注意一个细节:MLE-Bench是OpenAI主导设立的。在对手的主场拿冠军,这个含金量不用多解释。
伐谋Agent到底是什么
百度伐谋的定位是"企业级算法自主优化智能体"。这个名字有点拗口,拆开来说就是:它是一个面向企业客户的AI Agent,专门用来自动化机器学习工程中的算法优化工作。
传统的ML开发流程是这样的:数据科学家拿到业务需求,手动做数据分析、特征工程、模型选型、训练调参、效果评估,反复迭代。一个中等复杂度的ML项目,从启动到上线,少则几周,多则几个月。其中大量时间花在重复性的调参和实验上。
伐谋Agent要做的,就是把这个过程中的大部分环节自动化。你给它一个数据集和业务目标,它自己去探索数据、设计特征、选择模型、调优参数,最终输出一个可用的解决方案。
这不是什么新概念。AutoML领域已经发展了好几年,Google的AutoML、Auto-sklearn、H2O等工具都在做类似的事。但伐谋的不同之处在于,它是基于大模型的Agent架构,而不是传统的搜索/优化算法。
传统AutoML更像是一个暴力搜索器——在预定义的搜索空间里,用贝叶斯优化或进化算法去找最优组合。它的上限受限于搜索空间的设计,而且对计算资源的消耗很大。
基于大模型的Agent则不同。它可以像人类工程师一样,先看数据长什么样,再决定用什么方法。它的决策过程是基于理解和推理的,而不是穷举的。这意味着它可以处理更开放、更复杂的问题,而且效率更高。
从MLE-Bench的成绩来看,这条路线是走得通的。
技术上值得关注的几个点
虽然百度没有公开伐谋2.0的完整技术细节,但从公开信息和MLE-Bench的任务特点来看,有几个方向值得关注:
第一是多步推理和规划能力。MLE-Bench的题目不是一步就能解决的,Agent需要制定一个多步骤的解题计划,并在执行过程中根据中间结果动态调整。这要求Agent具备较强的长程规划能力,而不只是单轮对话的问答能力。
第二是代码生成和执行的闭环。Agent不仅要生成代码,还要能执行代码、观察结果、诊断问题、修复bug。这个"写-跑-看-改"的循环,是工程能力的核心。很多Agent在代码生成环节表现不错,但在执行和调试环节就拉胯了。
第三是领域知识的运用。Kaggle竞赛涵盖图像分类、NLP、表格数据、时间序列等多种任务类型。Agent需要根据不同的任务类型,调用不同的领域知识和工程经验。比如处理表格数据时知道该用LightGBM而不是ResNet,处理文本分类时知道该怎么做数据增强。
第四是资源管理。在有限的时间和计算资源下,Agent需要合理分配资源——哪些题值得花更多时间,哪些题快速出一个baseline就行。这种"元策略"层面的决策能力,往往是区分顶尖Agent和普通Agent的关键。
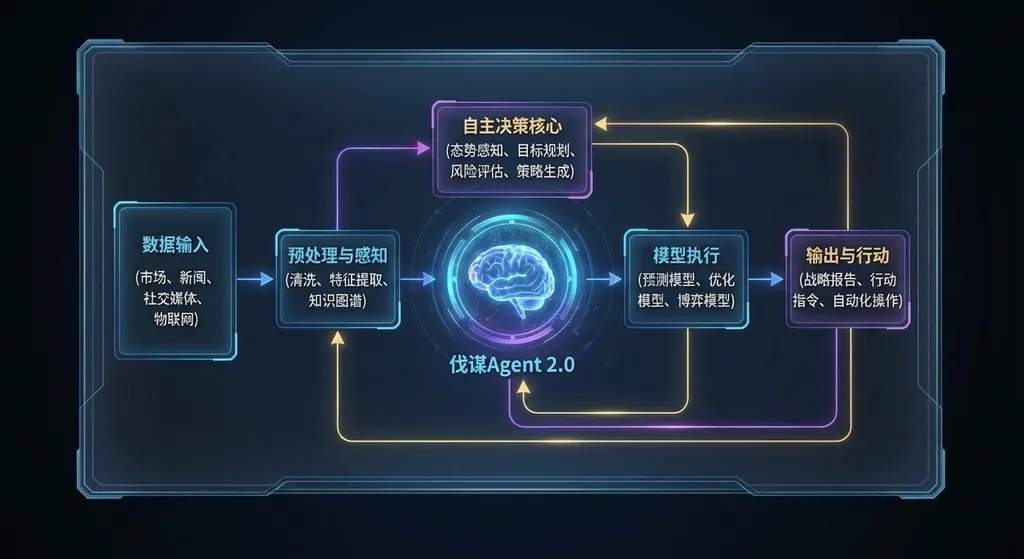
对开发者意味着什么
如果你是做ML工程的开发者,伐谋这类工具的成熟意味着你的工作方式可能要变了。
不是说ML工程师会被替代——至少短期内不会。但那些重复性的调参、特征工程实验、baseline搭建等工作,确实可以交给Agent来做。工程师的角色会更偏向问题定义、方案评审和业务对接。
更现实的影响是:企业做ML项目的门槛会降低。以前你需要一个3-5人的数据科学团队花几个月做的事,未来可能一个工程师配合Agent几天就能搞定初版。这对中小企业来说是个好消息。
当然,前提是这些Agent真的能在生产环境中稳定运行,而不只是在benchmark上刷分。5月Create大会上发布的正式版,才是真正的考验。
放在行业里看
目前在AI Agent领域,各家的侧重点不太一样:
- OpenAI的重心在通用Agent(比如ChatGPT的插件生态和Operator),走的是平台化路线
- Anthropic的Claude更强调安全性和可控性,Agent能力在逐步增强但相对保守
- Google DeepMind在科研Agent方向投入很大,AlphaCode、AlphaFold系列都是典型
- 国内方面,百度伐谋聚焦ML工程,阿里、字节也在各自的优势领域布局Agent
百度选择ML工程这个切入点是聪明的。这个领域足够垂直、需求足够明确、效果足够可量化。不像通用Agent那样难以评估,ML工程的好坏直接看模型指标就行。MLE-Bench的成绩就是最好的证明。
但也要看到,benchmark成绩和实际产品体验之间往往存在gap。75道Kaggle题目毕竟是标准化的竞赛环境,真实的企业ML项目要复杂得多——数据质量参差不齐、业务约束千奇百怪、部署环境各不相同。伐谋2.0能不能在这些真实场景中保持同样的水准,还需要正式版发布后才能验证。
关于API调用
对于想要在自己的应用中集成各类AI模型能力的开发者来说,现在的选择越来越多。无论是百度的文心系列、OpenAI的GPT系列、Anthropic的Claude,还是Google的Gemini,都提供了API接入方式。
如果你不想为每个模型厂商单独管理API Key和接入方式,可以通过OpenAI Hub这类聚合平台来统一调用。一个Key就能访问主流模型,接口格式兼容OpenAI标准,国内网络直连,省去不少折腾。
比如调用不同模型做对比测试,代码可以这样写:
from openai import OpenAI
client = OpenAI(
api_key=\"你的OpenAI Hub API Key\",
base_url=\"https://api.openai-hub.com/v1\"
)
# 同样的接口格式,切换不同模型只需改 model 参数
models = [\"gpt-4o\", \"claude-sonnet-4\", \"gemini-2.5-pro\", \"deepseek-chat\"]
for model in models:
response = client.chat.completions.create(
model=model,
messages=[
{\"role\": \"user\", \"content\": \"用Python写一个简单的特征工程pipeline\"}
],
max_tokens=1024
)
print(f\"--- {model} ---\")
print(response.choices[0].message.content)
这在做模型能力对比、选型评估的时候特别方便。
接下来看什么
5月的Create 2026百度AI开发者大会是关键节点。届时伐谋2.0正式版发布,我们能看到:
- 具体的产品形态和定价策略
- 面向企业客户的实际案例和效果数据
- 与百度智能云其他产品(比如千帆平台)的整合方式
- 是否开放API供开发者直接调用
对于关注AI工程化落地的开发者来说,这是一个值得跟进的产品。不是因为它刷了榜单,而是因为它代表的方向——用Agent来自动化ML工程——确实是行业的大趋势。
至于它最终能不能从benchmark冠军变成真正好用的生产力工具,一个月后见分晓。
参考来源:
- 百度伐谋Agent 2.0再次登顶MLE-Bench - 36氪:首发快讯,包含MLE-Bench榜单刷新SOTA及Create 2026发布计划等核心信息
