三个AI Agent互相对话,然后交付了一个完整应用

开发者用 Claude 多智能体协作架构,让三个 Agent 分工协同生成完整多文件 Web 应用。从玩具实验到 Claude Code Agent Teams,多智能体编程正在从概念走向可用。
一个开发者在 Linux.do 上分享了一个实验:输入一句话需求,三个 AI Agent 自动拆解任务、分头干活、互相沟通,最后交付一个完整的多文件 Web 应用。
不是 Demo 视频,不是概念图,是一个你现在就能打开体验的线上产品。
项目叫 Builder AI,GitHub 开源,Vercel 上有部署。它做的事情不复杂但足够说明问题——用多智能体协作的方式,把「自然语言到可运行代码」这条路走通了。
一句话需求,三个 Agent 接活
Builder AI 的工作流程是这样的:用户输入一个需求描述,比如「做一个带用户认证的 Todo 应用」,系统会启动三个 Agent,各自负责不同的职责模块。一个管架构和文件结构,一个写核心业务逻辑,一个处理 UI 和样式。它们不是串行执行的流水线,而是并行工作、互相感知进度的协作体。
最终输出的不是一个单文件的代码片段,而是包含多个文件、目录结构完整、可以直接跑起来的 Web 应用。
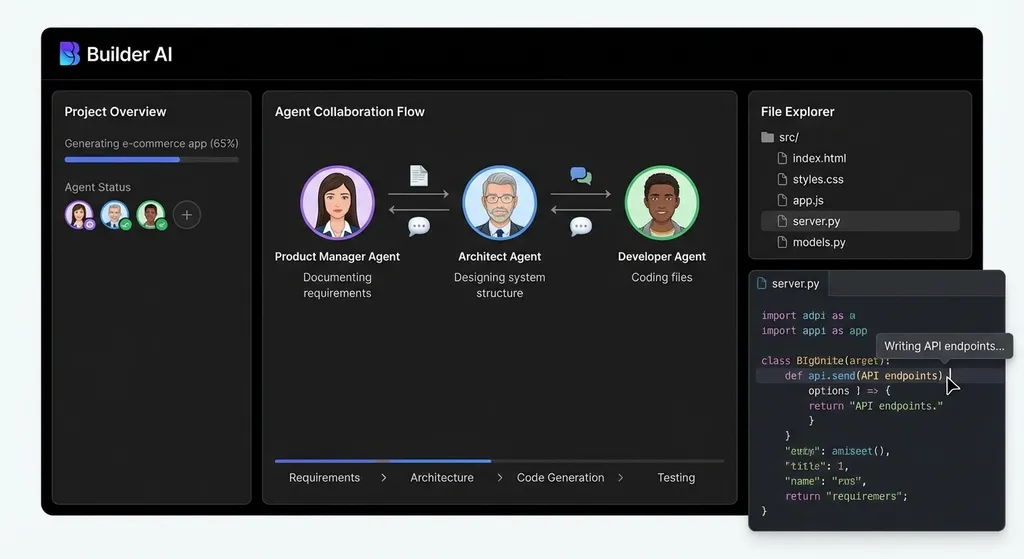
这个项目本身的技术实现并不算复杂。真正值得关注的是它背后的趋势:多智能体协作编程,正在从 Anthropic 的实验性功能,变成开发者可以自己搭建和复现的模式。
从 Subagent 到 Agent Teams:Anthropic 在推什么
要理解这个实验的意义,得先看 Claude 生态里「多智能体」这条线的演进。
最早 Claude Code 里有 Subagent 机制。主 Agent 可以派生出子 Agent 去执行特定任务,子 Agent 完成后把结果交回来。这本质上还是一个中心化的调度模型——主 Agent 是老板,Subagent 是跑腿的,所有信息都要经过老板中转。
这种模式的瓶颈很明显:主 Agent 成了通信瓶颈,上下文窗口被大量中间结果占满,而且没法让两个子任务之间直接交流。你让一个 Agent 写后端 API,另一个写前端组件,它们之间对接口的理解完全靠主 Agent 转述,效率可想而知。
Claude Code Agent Teams 就是为了解决这个问题。它引入了一个真正的团队协作机制:
- 一个 Team Lead 负责任务拆解和整体协调
- 多个 Teammate 并行工作,各自有独立的上下文
- Teammate 之间可以直接通信,不用所有消息都经过 Lead 中转
- 支持「对抗式讨论」,一个 Agent 可以质疑另一个 Agent 的方案
用一个不太严谨但很直观的类比:Subagent 像是一个人开了几个终端窗口同时干活,Agent Teams 像是一个真正的三人开发小组在协作。
两者的核心差异可以这样理解:
| 维度 | Subagent | Agent Teams | |------|----------|-------------| | 通信模式 | 星型(都经过主 Agent) | 网状(可以直接互相通信) | | 协调方式 | 主 Agent 统一管理 | Team Lead 协调 + 自组织 | | 上下文 | 共享主 Agent 上下文 | 每个 Teammate 独立上下文 | | Token 消耗 | 相对可控 | 成倍增长(N 个 Teammate ≈ N 倍消耗) | | 适用场景 | 简单并行任务 | 复杂项目、需要多角色协作 |
实际体验:能用,但别期待太多
我们来看 Builder AI 这个项目的实际表现。
从 GitHub 仓库看,它的架构比较直白:前端用 React,通过 API 调用 Claude 模型,在服务端编排三个 Agent 的工作流。每个 Agent 有自己的 system prompt 和职责定义,通过共享的任务状态来协调进度。
线上体验地址 builder-ai-v2.vercel.app 可以直接试。输入一个需求后,你能看到三个 Agent 的工作过程——谁在生成什么文件、当前进度如何、最终输出了哪些代码。
说实话,对于简单需求(比如一个静态页面、一个基础 CRUD 应用),效果还不错。生成的代码结构清晰,文件拆分合理,基本能直接跑。但如果你给一个稍微复杂的需求,比如涉及数据库设计、权限控制、多页面路由的应用,Agent 之间的协调就开始出问题了——接口定义不一致、状态管理有冲突、样式和逻辑耦合不当。
这不是 Builder AI 这个项目的问题,而是当前多智能体协作的普遍瓶颈。Agent 之间的「共识」建立,比人类团队的沟通还要脆弱。人类开发者可以通过 code review、站会、文档来对齐理解,Agent 之间的对齐目前还主要靠 prompt 工程和任务描述的精确度。
如果你想自己搭一个
这类多 Agent 编排的核心,说到底是对大模型 API 的调用和编排。如果你想自己实现类似的多智能体协作系统,关键在于几个部分:Agent 的角色定义、任务分配策略、Agent 间通信协议、以及结果合并逻辑。
以一个最简化的三 Agent 协作为例,每个 Agent 本质上就是一次带有特定 system prompt 的 API 调用:
import openai
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
def call_agent(role_prompt, task_description, context=""):
"""调用单个 Agent"""
response = client.chat.completions.create(
model="claude-sonnet-4-20250514",
messages=[
{"role": "system", "content": role_prompt},
{"role": "user", "content": f"任务:{task_description}\n\n上下文:{context}"}
],
max_tokens=4096
)
return response.choices[0].message.content
# 定义三个 Agent 的角色
architect_prompt = """你是一个软件架构师 Agent。
你的职责是:根据需求设计项目结构、定义文件目录、规划模块划分和接口契约。
输出格式:JSON,包含文件树和每个文件的职责说明。"""
backend_prompt = """你是一个后端开发 Agent。
你的职责是:根据架构设计,实现业务逻辑、API 路由和数据处理。
严格遵循架构师定义的接口契约。"""
frontend_prompt = """你是一个前端开发 Agent。
你的职责是:根据架构设计,实现 UI 组件、页面布局和交互逻辑。
严格遵循架构师定义的接口契约。"""
# 编排流程
user_requirement = "做一个支持 Markdown 的在线笔记应用"
# Step 1: 架构师先出方案
architecture = call_agent(architect_prompt, user_requirement)
print("架构设计完成")
# Step 2: 后端和前端并行开发(这里简化为顺序调用,实际应用中可以用 asyncio 并行)
backend_code = call_agent(backend_prompt, "实现后端逻辑", context=architecture)
frontend_code = call_agent(frontend_prompt, "实现前端界面", context=architecture)
print("代码生成完成")
这只是最基础的串行编排。真正的多智能体协作还需要加入几个关键机制:
- 并行执行——用 asyncio 或多线程让多个 Agent 同时工作
- 共享状态——Agent 之间需要一个共享的「黑板」来同步进度和中间产物
- 冲突解决——当两个 Agent 的输出有矛盾时,需要一个仲裁机制
- 迭代修正——第一轮输出几乎不可能完美,需要 Agent 之间互相 review 和修正
如果你用 OpenAI Hub 的 API,好处是一个 Key 就能调 Claude、GPT、Gemini 等不同模型。一个实际的优化策略是:让 Team Lead 用能力最强的模型(比如 Claude Opus),Teammate 用性价比更高的模型(比如 Claude Sonnet),在效果和成本之间找平衡。
Agent Teams 的真正门槛:不是技术,是成本
聊多智能体协作,绕不开一个现实问题:Token 消耗。
单 Agent 模式下,一次复杂的代码生成任务可能消耗几万 Token。换成 Agent Teams,三个 Teammate 各自独立运行,再加上 Team Lead 的协调开销和 Agent 间通信的 Token,总消耗轻松翻 3-5 倍。
博客园上一篇实测文章提到,一个中等复杂度的功能开发,Agent Teams 模式下的 Token 消耗大约是单 Agent 的 4 倍。如果你用的是 Claude Pro 或 Max 计划,超出额度的部分按标准 API 费率计费,这个成本不算低。
所以 Anthropic 自己也建议:团队规模控制在 2-5 个 Teammate,别动不动就开一个 10 人 Agent 团队。而且要「持续关注团队动态」,别启动之后就放着不管——长时间无人监督的 Agent 团队,很容易在错误的方向上越跑越远,白白烧 Token。
这也是为什么 Agent Teams 目前还是实验性功能。它的价值在特定场景下很明确——大型重构、多模块并行开发、需要多角度验证的架构决策——但不是所有任务都值得用这个模式。写一个工具函数、改一个 Bug、加一个小功能,单 Agent 就够了。
横向看:不只是 Claude 在做这件事
多智能体协作不是 Anthropic 的独家叙事。
微软的 AutoGen 框架、CrewAI、LangGraph 都在做类似的事情。OpenAI 自己也在 Assistants API 里逐步引入多 Agent 编排能力。Google 的 Vertex AI 平台同样有多 Agent 的实验性支持。
但 Claude Code Agent Teams 有一个独特优势:它是直接嵌入开发者日常工作流的。你不需要额外搭建一个编排框架,不需要写一堆胶水代码,在 Claude Code 的终端里就能直接启动一个 Agent 团队。Reddit 上有个评论说得挺到位:「终端分成 3 个窗格这件事最能打动人——这是多智能体协作第一次被打包成看起来像正常开发工作的东西,而不是一个研究演示。」
而 Builder AI 这个开源项目的价值在于,它把这种协作模式从 Claude Code 的封闭环境里拿了出来,变成了一个任何人都能部署和修改的 Web 应用。虽然实现上还比较粗糙,但方向是对的。
冷静看:多智能体编程的现实边界
多智能体协作编程是不是未来?大概率是。但现阶段它的局限也很明显:
第一,Agent 之间的「理解对齐」还很脆弱。人类团队可以通过反复沟通来消除歧义,Agent 之间的沟通轮次和深度都有限。一旦架构 Agent 的设计描述有模糊之处,后续的实现 Agent 很可能各自理解、各自发挥,最后合并时一堆冲突。
第二,调试成本很高。单 Agent 生成的代码出了问题,你看一个上下文就行。多 Agent 协作出了问题,你得回溯每个 Agent 的决策过程,搞清楚是谁在哪一步做了错误的判断。这个调试体验目前还很原始。
第三,对需求描述的精确度要求更高了。单 Agent 模式下,模糊的需求顶多导致生成的代码不太对,改改就行。多 Agent 模式下,模糊的需求会被放大——每个 Agent 都按自己的理解去实现,最后的分歧比单 Agent 大得多。
所以我的判断是:多智能体协作编程在 2026 年会有更多落地场景,但它不会取代单 Agent 模式,而是作为一种「重型武器」存在——用于复杂度足够高、值得付出额外成本的场景。
对于大多数日常开发任务,一个好用的单 Agent(配合好的 prompt 和工作流)仍然是性价比最高的选择。
值得关注的几个方向
如果你对多智能体编程感兴趣,有几个方向值得持续跟进:
- Claude Code Agent Teams 的正式发布节奏。目前还是实验性功能,需要手动开启 feature flag,稳定性和易用性都有提升空间。
- 混合模型编排的成熟度。用不同能力等级的模型担任不同角色,是控制成本的关键策略,但目前的实践经验还不多。
- Agent 间通信协议的标准化。现在每个框架都有自己的一套,缺乏统一标准。谁能定义出一个被广泛接受的 Agent 通信协议,谁就能在这个赛道上占据有利位置。
- 可观测性工具。多 Agent 系统的调试和监控需要专门的工具支持,这块目前几乎是空白。
Builder AI 这个项目本身可能不会成为一个大产品,但它代表的方向——让多智能体协作从实验走向可用——是 2026 年 AI 编程领域最值得关注的趋势之一。
参考来源:
- Claude AI 多 Agent 开发与编排实验 — Linux.do 社区原帖,Builder AI 项目介绍和讨论
- Builder AI GitHub 仓库 — 项目源码,三 Agent 协作生成 Web 应用
- 一文读懂 Agent Teams,Claude Code 从单体智能到自主智能体集群 — 知乎专栏,Agent Teams 架构和使用详解
