Swarmesh:让多个AI在终端里组队干活

开源框架 Swarmesh 基于 tmux 实现多 AI CLI 蜂群协作,近期大版本升级引入 5 阶段任务流、能力分发机制和 integrator 角色,让 Claude、Gemini、Codex 在终端里像真正的开发团队一样自主协作。
一个叫 Swarmesh 的开源项目最近在开发者社区里引起了不小的关注。它做的事情很直接:在 tmux 里同时跑多个 AI CLI(Claude Code、Gemini CLI、Codex CLI),让它们像一个蜂群一样自主分工、协作完成复杂开发任务。
不是套壳,不是简单的串行调用,是真的让多个模型各司其职、并行工作。
先说清楚它解决什么问题
现在用 AI 辅助编程的开发者越来越多,但大多数人的工作流还是「一个终端、一个模型、一次对话」。遇到复杂项目——比如要同时搞前端重构、后端 API 改造、再跑一轮集成测试——你得在不同窗口之间反复切换,手动把上下文从一个模型搬到另一个模型。
这个过程的痛点不是某个模型不够强,而是协调成本太高。你自己变成了「人肉调度器」。
Swarmesh 想干掉的就是这个角色。它在 tmux 的多窗格环境里起多个 AI CLI 实例,通过一套协调协议让它们自己分任务、自己汇总结果、自己处理冲突。你只需要描述最终目标,剩下的交给蜂群。
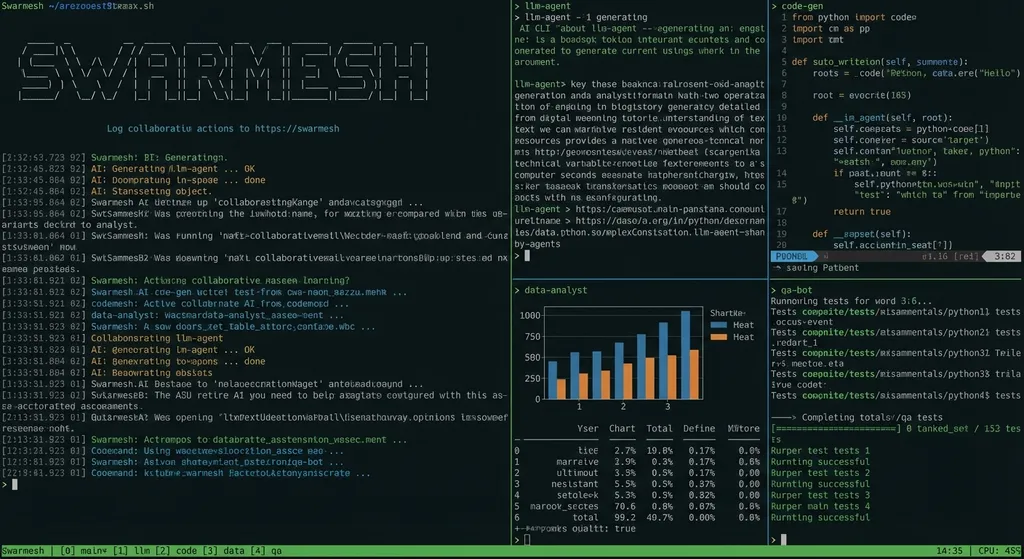
这次升级改了什么
最近这次更新的变化相当大,几乎重写了任务调度的核心逻辑。逐个拆开看:
任务流从模糊变成了 5 个明确阶段
之前的版本任务流比较粗糙,基本就是「分任务 → 干活 → 汇总」。新版本把整个流程拆成了 5 个阶段:
- 调研(Research)—— 收集信息、分析需求
- 方案(Planning)—— 制定技术方案和分工
- 实现(Implementation)—— 各角色并行编码
- 集成(Integration)—— 合并产出、解决冲突
- 验收(Verification)—— 测试、校验、确认交付
这个设计明显是从真实的软件开发流程里抽象出来的。做过团队协作的人一看就懂——它把 AI 协作从「一股脑干」变成了有节奏的工程化流程。每个阶段有明确的输入输出,上一步没做完下一步不会开始。
说实话,这比很多人类团队的流程管理都规范。
能力分发取代角色硬分配
这是这次升级里我觉得最有意思的改动。
之前的逻辑是:Claude 负责写代码,Gemini 负责做调研,Codex 负责跑测试——角色是写死的。问题很明显,如果某个任务需要的能力跟预设角色对不上,系统就卡住了。
新版本引入了「能力(capability)」的概念。每个 AI CLI 实例注册自己擅长什么(代码生成、文档撰写、测试编写、架构分析等),任务分发时按能力匹配,而不是按名字匹配。
更聪明的是,匹配不到合适角色时,系统会自动找备选方案,甚至动态补一个新角色进来。这就像一个项目经理发现团队里缺前端,临时从其他组借人一样。
这个机制带来的好处是显而易见的:
- 同一个模型可以在不同任务里扮演不同角色
- 新模型接入时不需要改调度逻辑,只需要声明能力
- 任务分配的灵活性大幅提升
对开发者来说,这意味着你可以混搭不同的模型组合。比如用 Claude 做复杂推理和代码生成,用 Gemini 做长上下文的文档分析,用 DeepSeek 做性价比更高的辅助任务。每个模型发挥自己的长处,而不是被强按在一个固定位置上。
新角色:Integrator(集成员)
多人协作最头疼的事情是什么?合代码。
三个人各写各的,最后一合并,冲突一堆、接口对不上、命名风格不统一。AI 协作也一样。之前的版本缺少一个专门负责「收敛」的角色,多个 AI 的产出经常需要人工介入才能拼到一起。
新版本加了 integrator 角色,专门干这件事:
- 收集各角色的产出
- 检查接口一致性
- 处理代码冲突
- 对齐命名和风格
- 生成最终的集成结果
这个设计很务实。它承认了一个现实:多 Agent 协作的难点不在于让每个 Agent 各自干好自己的活,而在于把所有人的活拼成一个能跑的整体。Integrator 就是那个负责「最后一公里」的角色。
结构化回执和审计追踪
之前任务派发和完成的记录比较随意,新版本把这块收紧了。现在每个任务都要求结构化记录:
- 做了什么(具体产出)
- 派给了谁(哪个 AI 实例)
- 有没有改派(如果有,为什么)
- 风险是什么(已知问题和潜在隐患)
这看起来像是在给 AI 加 KPI,但实际上解决的是可追溯性问题。当蜂群里有 5 个 AI 同时在干活,出了问题你得能快速定位是哪个环节、哪个角色出的错。没有结构化记录,debug 多 Agent 系统简直是噩梦。
Playbook 和 Capability 工具链
新版本还配套了一组工具:
- 能力校验:检查当前 AI 实例的能力声明是否合理
- 编排推荐:根据任务描述自动推荐角色组合和分工方案
- 模板审批:把验证过的协作模式保存为可复用的 playbook
这套东西的价值在于降低上手门槛。你不需要从零开始设计协作流程,直接用社区验证过的 playbook 就行。比如「全栈 Web 应用开发」「微服务重构」「文档生成+代码审查」这类常见场景,拿来就能用。
统一权限适配
Claude Code、Gemini CLI、Codex CLI 这几个工具对文件系统的权限管理各不相同。Claude Code 有自己的权限确认机制,Gemini CLI 的处理方式又不一样。之前 Swarmesh 对每个 CLI 单独做适配,维护成本高,还容易出 bug。
新版本把权限层统一了,所有 CLI 走同一套适配逻辑。这对使用者来说是透明的,但对项目的可维护性和新 CLI 的接入速度提升很大。
跟现有方案比怎么样
市面上做多 Agent 协作的框架不少——CrewAI、AutoGen、LangGraph 都在做类似的事。Swarmesh 的差异化在哪?
最大的区别是它完全基于 CLI。不需要写 Python 代码来编排 Agent,不需要搭 API 服务,不需要学新的 SDK。你本地已经装了 Claude Code 和 Gemini CLI?直接用。整个协调层跑在 tmux 里,轻量到几乎没有额外依赖。
这个选择有利有弊。
好处是门槛极低,对已经在用这些 CLI 工具的开发者来说几乎零成本接入。而且因为直接复用了各 CLI 的原生能力,模型的上下文窗口、工具调用、文件操作这些能力都是满血的,不存在框架层的能力损耗。
坏处也很明显:它强依赖 tmux,Windows 用户基本被排除在外(WSL 除外);调试体验不如有 GUI 的方案直观;而且基于终端文本的通信协议,在复杂场景下可能不如结构化 API 调用稳定。
跟 CrewAI 这类框架相比,Swarmesh 更像是「开发者的瑞士军刀」而不是「企业级解决方案」。它适合个人开发者或小团队在本地快速搭建多模型协作环境,但如果你需要生产级的监控、日志、容错机制,可能还得再等等。
不过话说回来,这次升级加入的结构化回执、任务暂停恢复、会话恢复这些能力,说明项目在往更工程化的方向走。
实际使用场景
说几个我觉得 Swarmesh 比较适合的场景:
第一个是全栈项目的并行开发。一个 Agent 写前端组件,一个写后端 API,一个写数据库迁移脚本,integrator 负责确保接口对齐。比你一个人在三个文件之间跳来跳去快得多。
第二个是代码审查+重构。一个 Agent 做代码分析找出问题,一个 Agent 写重构方案,一个 Agent 执行重构,最后一个跑测试验证。整个流程自动化,你只需要在验收阶段看一眼结果。
第三个是技术调研。让不同的 Agent 分别调研不同的技术方案,各自输出对比分析,最后由 integrator 汇总成一份完整的技术选型报告。
关于多模型调用
既然 Swarmesh 的核心是让多个模型协作,那模型的调用方式就很关键。在实际使用中,你可能会同时调用 Claude、Gemini、DeepSeek 等不同模型,每个模型的 API 格式和端点都不一样,管理多个 API Key 本身就是个麻烦事。
如果你用 OpenAI Hub(openai-hub.com)这类 API 聚合服务,一个 Key 就能调所有主流模型,而且都走 OpenAI 兼容格式,在国内也能直连,配置起来会简单不少。比如在 Swarmesh 的能力配置里,不同角色对应不同模型时,统一用一个 base URL 就行:
import openai
# 通过 OpenAI Hub 统一调用不同模型
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://openai-hub.com/v1"
)
# 调研阶段 - 用 Gemini 处理长上下文
research_response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "分析这个项目的技术架构..."}]
)
# 实现阶段 - 用 Claude 做代码生成
impl_response = client.chat.completions.create(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "根据以下方案实现用户认证模块..."}]
)
# 辅助任务 - 用 DeepSeek 控制成本
assist_response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "为以下函数编写单元测试..."}]
)
这种方式跟 Swarmesh 的能力分发机制天然契合——不同能力对应不同模型,但调用方式完全统一。
一些冷静的思考
多 Agent 协作是个很热的方向,但我觉得有几个问题值得注意。
首先是成本。多个模型并行跑,token 消耗是成倍增长的。一个复杂任务跑下来,5 个 Agent 各自消耗几万 token,加上协调通信的开销,费用不低。Swarmesh 目前没有看到明确的成本控制机制,比如 token 预算、任务复杂度评估后的动态缩减等。
其次是确定性。单个 LLM 的输出已经有不确定性了,多个 LLM 协作时这个问题会被放大。Agent A 的输出是 Agent B 的输入,如果 A 产生了一个微妙的错误,B 可能会在错误的基础上继续构建,最后 integrator 收到的是一堆看起来合理但实际有问题的代码。这种「错误传播」在多 Agent 系统里是个已知的难题。
最后是调试。当蜂群里有 5 个 Agent 同时在干活,某个环节出了问题,你怎么定位?新版本的结构化回执是个好的开始,但距离真正好用的调试体验还有距离。我期待后续能看到类似「任务执行时间线」「Agent 间通信日志可视化」这样的工具。
总结
Swarmesh 这次升级的方向是对的:从「能跑」走向「能用」。5 阶段任务流、能力分发、integrator 角色、结构化回执——这些改动都在解决多 Agent 协作中的真实痛点,而不是在堆功能。
它不会取代你现有的 AI 编程工作流,但如果你已经在用 Claude Code 或 Gemini CLI,想试试让多个模型协作完成更复杂的任务,Swarmesh 是目前门槛最低的选择之一。
基于 tmux 的方案注定了它更适合 Linux/macOS 上的硬核开发者,而不是追求开箱即用的大众用户。但对于目标用户群来说,这恰恰是它的魅力所在——没有多余的抽象层,一切都在你熟悉的终端里发生。
值得持续关注。
参考来源:
- Swarmesh 社区讨论帖(Linux.do) — 包含本次升级的详细更新日志和社区反馈
- memory_agent_hub(GitHub) — AI Agent 架构和多智能体协作相关项目汇总
