Imagine Server 开源:一个接口统一所有AI画图模型
开源项目 Imagine Server 发布 v1.3.0,将 Gemini Imagen、Grok Imagine、OpenAI DALL·E 等多家图片生成模型统一封装为兼容 API,开发者不再需要为每个模型单独写接入逻辑。
AI 图片生成这条赛道,卷得越来越碎片化了。
Gemini 有 Imagen 4,xAI 有 Grok Imagine,OpenAI 有 DALL·E 和 GPT-4o 原生出图,Hugging Face 上还有一堆开源扩散模型。每家的 API 格式不一样,鉴权方式不一样,返回结构也不一样。对于想在产品里集成 AI 生图能力的开发者来说,光是写适配层就够喝一壶的。
最近开源的 Imagine Server 就是来解决这个问题的。项目刚发布了 v1.3.0,把市面上主流的图片生成服务统一封装成了一套 API,开发者只需要面对一个接口,后面接谁、怎么切换,全部由服务端搞定。
它到底做了什么
Imagine Server 的核心思路很简单:做一个图片生成领域的「API 网关」。
你往它发一个生图请求,它根据你指定的 provider 去调对应的上游服务,拿到结果后统一格式返回。支持的上游目前包括:
- Hugging Face Inference API
- Gitee AI
- ModelScope(魔搭)
- Google Gemini(Imagen 系列,项目里叫 Nano Banana)
- xAI Grok Imagine
- OpenAI DALL·E / GPT-Image
这个列表在 v1.3.0 里扩展了不少。之前的版本主要覆盖 Hugging Face、Gitee AI 和 ModelScope 这几个偏开源生态的平台,新版本把三大商业模型厂商的图片生成能力都接进来了。
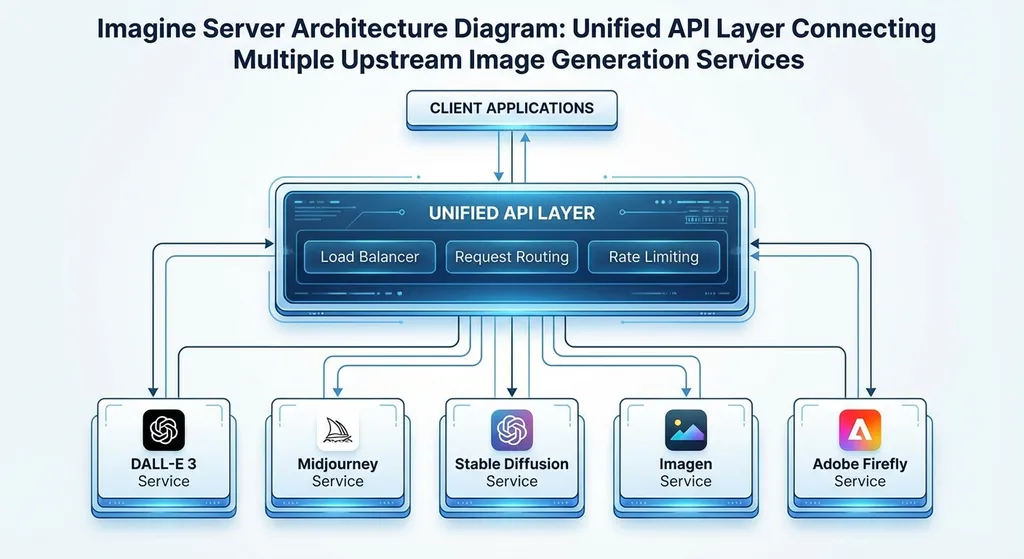
项目本身基于 Node.js 构建,用 Hono 做 HTTP 框架,TypeScript 写的,代码结构比较清晰。部署方式支持 Docker,也可以直接 Node 跑。
为什么这件事值得关注
你可能会觉得,不就是封装了几个 API 吗,有什么好说的?
但如果你真的在生产环境里对接过多家图片生成服务,就知道这里面的坑有多少。
先说格式差异。OpenAI 的 Images API 返回的是 base64 或者 URL,Gemini Imagen 走的是 generateImages 接口、返回结构完全不同,Grok Imagine 又是另一套。光是把这些响应统一成一个结构,就需要写不少胶水代码。
Imagine Server 把这层差异吃掉了。不管后面是哪家的模型,前端拿到的响应格式是一致的。这对于需要做 A/B 测试(比如同一个 prompt 分别用 Imagen 和 DALL·E 生成,让用户投票选质量更好的)的场景来说,省了很多事。
再说可用性。单一依赖某家服务是有风险的——API 限流、服务降级、区域不可用,这些都是真实会遇到的问题。有了统一网关层,做 fallback 策略就容易多了:Gemini 挂了自动切 Grok,Grok 也不行就降级到 Hugging Face 上的开源模型。
v1.3.0 还加了一个实用功能:S3 存储集成。很多图片生成 API 返回的 URL 是临时的,过一段时间就失效。Imagine Server 可以把生成的图片自动存到你自己的 S3(或兼容存储),生成稳定的访问链接。这个在生产环境里很重要,不然用户刷新一下页面图就没了。
技术细节拆一拆
看了一下项目的代码结构,几个设计决策值得聊聊。
Provider 抽象层
每个上游服务被抽象成一个 Provider,实现统一的接口。新增一个 Provider 基本就是写一个适配器,把上游的请求/响应格式映射到内部的统一结构上。这个模式不新鲜,但做得干净的话确实好维护。
比如你想调用 Gemini 的 Imagen 来生图,请求大概长这样:
curl -X POST http://localhost:3000/api/generate \
-H "Content-Type: application/json" \
-d '{
"provider": "gemini",
"prompt": "一只赛博朋克风格的猫站在霓虹灯下的东京街头",
"width": 1024,
"height": 1024
}'
换成 Grok Imagine?把 provider 字段改成 "grok" 就行,其他参数不用动。换成 OpenAI?改成 "openai"。接口的一致性就体现在这里。
和 Peinture 的关系
Imagine Server 其实是另一个开源项目 Peinture(派奇智图)的后端服务。Peinture 是一个面向终端用户的 AI 图片生成应用,前端提供交互界面,后端就是 Imagine Server。
这意味着 Imagine Server 不是一个纯粹的「技术 demo」,它是在真实产品里跑着的。这一点比较重要——很多开源的 API 封装项目写完 README 就没人维护了,有实际产品在用的项目,持续维护的动力会强很多。
S3 存储这个细节
前面提到的 S3 集成,实现上应该是在拿到上游返回的图片数据后,异步上传到配置好的 S3 bucket,然后把 S3 的 URL 返回给调用方。这个流程会增加一点延迟,但换来的是链接的持久性。
对于聊天应用、内容平台这类场景,图片链接必须是稳定的,不然消息记录里全是裂图。这个功能看着不起眼,但确实是生产环境的刚需。
横向对比:它的位置在哪
做 AI API 聚合的项目不少,但专注图片生成领域的不多。
类似的项目比如 Grok2API,也是把 Grok 的能力封装成 OpenAI 兼容格式,但它更偏向对话和单一模型的代理,图片生成只是附带功能。而 Imagine Server 是反过来的——它只做图片生成,但把这件事做得比较完整。
和商业方案比,比如直接用 OpenAI Hub 这类 API 聚合平台,Imagine Server 的优势在于完全自托管、数据不经过第三方。劣势也很明显:你得自己管理各家的 API Key、处理限流、监控可用性。如果你的场景对数据隐私要求高,或者需要深度定制路由策略,自建 Imagine Server 是合理的选择。如果只是想快速调通多家模型的图片生成能力,用 OpenAI Hub 这类平台会省心得多——一个 Key 就能调 GPT、Gemini、Grok 等模型的生图接口,不用自己折腾部署。
各家图片生成模型现在什么水平
既然 Imagine Server 把这几家都接进来了,顺便聊聊它们各自的状态。
Google 的 Imagen 4 是目前综合素质比较高的。支持标准、Ultra、Fast 三个档位,Ultra 出图质量最好但最慢,Fast 适合对延迟敏感的场景。Imagen 4 在文字渲染上的进步很大,之前 AI 生图最被吐槽的「写字像鬼画符」问题,在 Imagen 4 上基本解决了。
xAI 的 Grok Imagine 是今年才正式开放 API 的。它和 Grok 的多模态能力深度绑定,支持文生图和图编辑。风格上偏写实,对人物的处理比较自然。不过 API 的稳定性和文档完善度,跟 Google 和 OpenAI 比还有差距。Grok Imagine 还有一个有意思的方向——它开始支持基础的视频生成(grok-imagine-video),虽然目前还比较初级,但说明 xAI 在往多模态内容生成的方向走。
OpenAI 这边,DALL·E 3 仍然是很多开发者的默认选择,主要是因为生态成熟、文档完善、和 ChatGPT 的集成度高。GPT-4o 的原生图片生成能力也在逐步开放,它的优势在于可以在对话上下文中自然地生成和编辑图片,不需要单独调 Images API。
如果你用 OpenAI Hub 来调这些模型,示例代码大概是这样的:
import openai
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
# 调用 DALL·E 生图
response = client.images.generate(
model="dall-e-3",
prompt="一只赛博朋克风格的猫站在霓虹灯下的东京街头",
size="1024x1024",
n=1
)
print(response.data[0].url)
# 调用 Gemini Imagen 生图
response = client.images.generate(
model="imagen-4.0-generate-001",
prompt="一只赛博朋克风格的猫站在霓虹灯下的东京街头",
size="1024x1024",
n=1
)
print(response.data[0].url)
格式完全一致,只是换个 model 名字。这就是统一 API 格式的好处——不管是自建 Imagine Server 还是用聚合平台,核心诉求都是一样的:别让我为每个模型写一套代码。
谁适合用 Imagine Server
说实话,这个项目不是给所有人准备的。
如果你只是偶尔调一下某家的生图 API,直接用官方 SDK 就够了,没必要多加一层。
但如果你的场景是这样的,那值得认真看看:
- 产品里需要同时接入多家图片生成模型,给用户提供选择或者做质量对比
- 需要自建图片生成服务,数据不能经过第三方
- 想做 fallback 策略,某家 API 挂了自动切换到备选
- 在开发一个类似 Midjourney 的图片生成应用,需要一个统一的后端服务
部署上,Docker 一把梭就行:
git clone https://github.com/Amery2010/imagine-server.git
cd imagine-server
docker compose up -d
然后在配置文件里填上各家的 API Key,就可以开始用了。
一些不足
客观说几个问题。
第一,项目目前的文档还比较薄。README 覆盖了基本的部署和使用,但对于各个 Provider 的具体参数支持、限制、错误处理,文档里写得不够详细。对于想在生产环境用的开发者来说,可能需要直接看源码才能搞清楚一些边界情况。
第二,没有看到完善的测试覆盖。对于一个 API 网关类项目来说,各种边界情况的测试(上游超时、返回异常格式、并发请求等)是很重要的。希望后续版本能补上。
第三,目前的路由策略比较简单——你指定哪个 Provider 就用哪个。更高级的功能比如基于成本的自动路由、基于质量评分的智能选择、请求队列和限流,这些在生产环境里都是需要的,但目前还没有。
不过话说回来,这是一个 v1.3.0 的开源项目,不是商业产品,能做到现在这个完成度已经不错了。核心的「统一多模型图片生成 API」这个价值主张是成立的,剩下的是工程完善度的问题。
写在最后
AI 图片生成正在从「玩具」变成「基础设施」。越来越多的产品需要内嵌生图能力——电商要生商品图,社交要生头像和表情包,设计工具要生素材,内容平台要生配图。
当生图变成基础设施,统一的接入层就成了刚需。就像我们不会为每个数据库单独写一套连接逻辑一样,图片生成 API 也需要一个标准化的抽象层。
Imagine Server 在这个方向上迈出了一步。它不完美,但思路是对的。如果你正好有多模型图片生成的需求,值得 clone 下来跑一跑,看看能不能省掉你写适配层的时间。
参考来源:
- Imagine Server 开源项目 GitHub 仓库 — 项目源码及文档
- Imagine Server v1.3.0 发布帖(LINUX DO 社区) — 版本更新说明及社区讨论
- AI 图像生成模型迭代历史(知乎专栏) — 各家图片生成模型技术演进梳理
