AI CLI 密钥泄露,终于有人管了
开源工具 ai-cli-scanner 可扫描 Claude Code、Codex、Gemini CLI 等工具的命令执行日志,检测 SSH 密钥、GitHub Token 等敏感凭证是否在 AI 辅助编程过程中被意外暴露。在 AI Agent 安全事件频发的当下,这个工具切中了一个被严重忽视的风险盲区。
当你让 Claude Code 帮你配 SSH、让 Codex 跑部署脚本、让 Gemini CLI 调试环境变量的时候,有没有想过一个问题:这些 AI 工具执行的每一条命令,都留下了日志。而日志里,可能躺着你的 SSH 私钥、GitHub Token、AWS 凭证。
最近,一个叫 ai-cli-scanner 的开源工具在 LINUX DO 社区冒了出来。它做的事情很简单——扫描 AI CLI 工具的命令执行记录,检查里面有没有敏感凭证泄露。支持 Claude Code、Codex、Gemini CLI,基于内置规则做模式匹配,输出文本和 JSON 两种格式的报告。
听起来不复杂,但它戳中的问题很真实。
一个被集体忽视的攻击面
过去一年,AI CLI 工具的渗透速度远超所有人预期。Claude Code、Codex CLI、Gemini CLI 已经成了不少开发者的日常工具,飞书和企业微信在今年 3 月底也各自开源了命令行工具,让 AI Agent 能直接操作办公平台。工具越来越强,权限越给越大,但安全这根弦,大多数人还没绷起来。
问题出在哪?AI CLI 工具的工作方式决定了它天然会接触敏感信息。你让它帮你配置 Git,它可能需要读取 ~/.ssh/ 目录;你让它部署服务,它可能会接触到环境变量里的 API Key;你让它调试一个认证问题,它可能会把 Token 打印到终端。这些操作都会被记录在 CLI 的执行日志里。
而这些日志,往往就静静地躺在你的本地磁盘上,没有加密,没有脱敏,没有任何保护。
更麻烦的是「中转站注入」的风险。ai-cli-scanner 的作者在帖子里提到,开发这个工具的直接动机就是看到有中转站被曝出注入恶意代码的案例。如果你通过第三方 API 中转服务调用模型,而中转站在响应中夹带了恶意指令,AI Agent 可能会在你不知情的情况下执行一些你没有授权的操作——比如读取并上传你的密钥文件。这时候,事后审计就变得至关重要。
这不是理论推演。今年 3 月,安全内参披露了 OpenClaw 的一系列安全事件:27 万个实例暴露在公网,ClawHub 市场上每八个插件就有一个是恶意的,CVE-2026-25253 允许攻击者通过一个链接实现一键远程代码执行。其中一个关键攻击向量就是「日志污染」——攻击者在日志文件中植入恶意指令,当 Agent 读取日志进行故障排除时,指令就会被执行。
Claude Code 自己其实也意识到了这个问题。今年早些时候泄露的 Claude Code 源码(超过 51 万行 TypeScript 代码被意外发布到 npm)显示,Anthropic 在客户端内置了凭证扫描功能,能检测包括 AWS Token、GCP API 密钥、Stripe 密钥、RSA 私钥在内的 20 多种凭证模式。逻辑很清楚:开发者经常在终端粘贴敏感信息,客户端需要先扫描、先拦截。
但问题是,这只是 Claude Code 自己的防护。Codex CLI 呢?Gemini CLI 呢?那些用 OpenCode 或其他开源 CLI 工具的开发者呢?每个工具各管各的,没有一个统一的、跨工具的事后审计方案。
ai-cli-scanner 试图填的就是这个空白。
它具体怎么工作
用法非常直接,四行命令搞定:
git clone https://github.com/qiye45/ai-cli-scanner
cd ai-cli-scanner
pip install -e .
ai-scan
运行后,它会做两件事:
- 把各个 AI CLI 工具的执行命令记录提取出来,统一保存到 JSONL 文件
- 基于内置规则对这些记录做模式匹配扫描,找出疑似密钥泄露的条目
默认输出到 scan_output/ 目录,包含三个文件:
execution_log.jsonl:提取的原始执行记录scan_report.txt:人类可读的文本报告scan_report.json:结构化的 JSON 报告,方便程序化处理
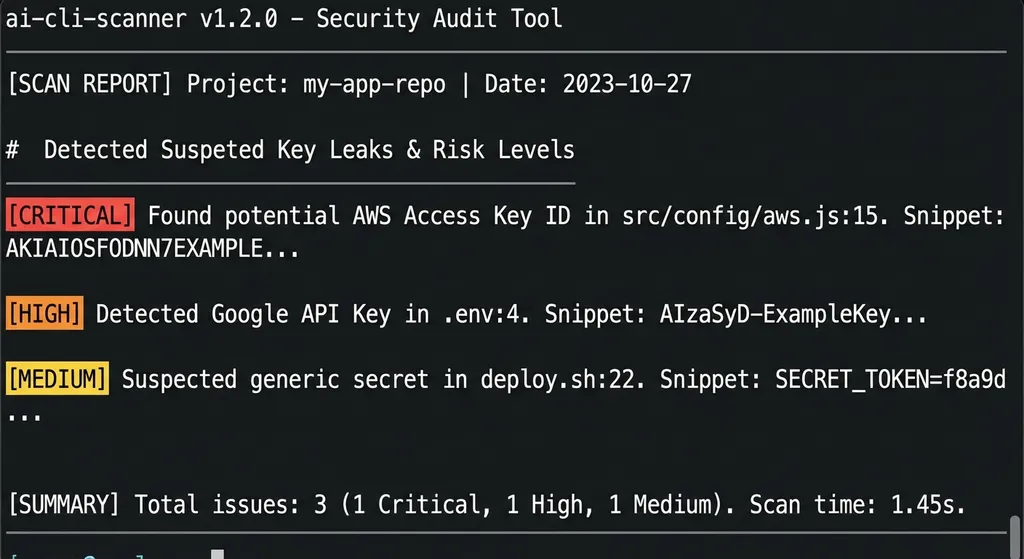
从设计上看,这是一个纯本地工具。扫描过程不联网,不上传任何数据,所有分析都在本地完成。对于一个处理敏感凭证信息的安全工具来说,这是正确的选择。
目前支持的 CLI 工具包括 Claude Code、Codex CLI 和 Gemini CLI。社区里已经有人在问是否支持 OpenCode,说明需求确实存在。作者表示内置规则还在持续完善中,欢迎提 Issue 和 PR。
坦率地说,这个工具现阶段还比较早期。内置规则的覆盖面、误报率、对不同 CLI 工具日志格式的兼容性,都还需要社区的实际使用来打磨。但方向是对的,而且切入点选得很准——不是试图在 Agent 执行过程中做实时拦截(那是各家 CLI 工具自己该做的事),而是提供一个事后审计的能力。就像你不能阻止所有交通事故,但你可以装行车记录仪。
更大的图景:AI Agent 安全正在成为刚需
把 ai-cli-scanner 放到更大的背景下看,它其实是 AI Agent 安全工具链中一个很小但很必要的环节。
过去半年,AI Agent 的安全问题正在从「理论讨论」快速转变为「现实威胁」。Google DeepMind 在 4 月初发表论文,提出了首个针对 AI Agent 网络攻击的系统性分类框架,把攻击方式分成了六大类。Anthropic 的新模型 Mythos 预览版展示了大规模自主发现零日漏洞的能力,直接挑战了传统的补丁防御模式。
在工具层面,Google 在去年 9 月开源了 Gemini CLI Security Extension,用 AI 来做代码安全审查。GitHub 的 Copilot 也在持续强化其密钥检测能力。但这些都是「大厂自己的方案」,覆盖的是自家生态。
对于那些同时使用多个 AI CLI 工具的开发者来说——这在实际工作中非常普遍,你可能用 Claude Code 写代码、用 Codex 做 review、用 Gemini CLI 查文档——需要的是一个跨工具的、统一的安全审计方案。ai-cli-scanner 虽然还很初级,但它指向的方向是对的。
开发者现在应该做什么
不管你用不用 ai-cli-scanner,有几件事值得现在就做:
第一,检查你的 AI CLI 工具的日志目录。Claude Code 的日志通常在 ~/.claude/ 下,Codex 的在 ~/.codex/ 下。打开看看,你可能会被里面记录的信息量吓一跳。
第二,永远不要在 AI CLI 工具中直接粘贴或输入真实的密钥、Token、密码。如果 AI 需要访问某个服务,通过环境变量传递,而不是在对话中明文输入。
第三,如果你通过第三方 API 中转服务调用模型,选择可信赖的平台。像 OpenAI Hub 这类聚合平台,一个 Key 就能调用 GPT、Claude、Gemini、DeepSeek 等主流模型,兼容 OpenAI 格式,国内直连,省去了自己维护多个 API Key 的麻烦,也减少了密钥分散暴露的风险面。
第四,定期轮换你的密钥。GitHub Token、SSH Key、各种 API Key,设置一个提醒,至少每季度换一次。如果你怀疑有泄露,立即轮换。
第五,关注 AI CLI 工具的权限设置。Claude Code 有 --dangerously-skip-permissions 这样的标志位,Codex 有沙箱模式。了解你用的工具提供了哪些安全控制,并且实际启用它们。
如果你想用 AI 来辅助安全审计
ai-cli-scanner 目前主要依赖内置规则做模式匹配。但如果你想更进一步,可以把扫描出的可疑条目交给大模型做二次判断——模式匹配容易误报,LLM 在理解上下文语义方面有天然优势。
比如,你可以把 scan_report.json 中的可疑条目发给模型,让它判断这到底是真正的密钥泄露,还是一个看起来像密钥但实际上是示例代码的误报。通过 OpenAI Hub 兼容的 API 格式,调用方式很简单:
import openai
import json
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
# 读取 ai-cli-scanner 的扫描报告
with open("scan_output/scan_report.json", "r") as f:
scan_results = json.load(f)
# 提取可疑条目
suspicious_items = [item for item in scan_results if item.get("risk_level") in ["high", "critical"]]
response = client.chat.completions.create(
model="claude-sonnet-4-20250514", # 也可以换成 gpt-4o、gemini-2.5-pro 等
messages=[
{
"role": "system",
"content": "你是一个安全审计专家。分析以下 AI CLI 工具的命令执行记录,判断是否存在真实的密钥泄露风险。对每条记录给出判断:true_positive(确认泄露)、false_positive(误报)、needs_review(需人工复核),并说明理由。"
},
{
"role": "user",
"content": json.dumps(suspicious_items, ensure_ascii=False, indent=2)
}
],
temperature=0.1 # 安全审计场景用低温度,减少幻觉
)
print(response.choices[0].message.content)
这种「规则扫描 + LLM 研判」的两阶段方案,在实际使用中效果会比纯规则匹配好不少。规则负责高召回率的初筛,LLM 负责降低误报率的精筛。而且通过 OpenAI Hub 的聚合能力,你可以方便地在不同模型之间切换——比如用 Claude 做安全分析、用 GPT-4o 做报告生成、用 DeepSeek 做中文场景的补充判断——不需要管理多套 API Key。
写在最后
ai-cli-scanner 不是什么革命性的工具,它做的事情甚至可以说很朴素:读日志、跑正则、出报告。但在 AI Agent 安全问题日益严峻的今天,它提醒了我们一个容易被忽略的事实——你给 AI 的权限越大,你需要的审计能力就越强。
当 AI 能帮你写代码、跑命令、操作文件系统的时候,「信任但验证」不再是一句口号,而是一个工程实践。ai-cli-scanner 是这个实践的一个起点,虽然粗糙,但方向正确。
如果你每天都在用 AI CLI 工具写代码,花五分钟跑一次扫描,可能比你花五天处理一次密钥泄露事故要划算得多。
参考来源:
- ai-cli-scanner GitHub 仓库 — 项目源码及使用文档
- LINUX DO 社区讨论帖 — 作者发布的项目介绍及社区反馈
- 一周 AI 速递:CLI 工具开源潮、源码泄露风波与三大模型齐发 - 掘金 — Claude Code 源码泄露事件及 AI CLI 工具生态动态
