Opus 4.6 蒸馏本地跑,省钱才是硬道理
有人把 Claude Opus 4.6 蒸馏进 Qwen3.5-27B 并在 M5 Max 上本地部署,实测用 Go 写爬虫 API 只要 10 分钟,还解决了 Claude Code 原生缓存兼容问题。本文拆解完整调优链路。
一天烧 300 块的人,开始自己蒸馏了
用 Claude Code 搞开发的人都知道那个账单有多刺激——Opus 4.6 一天跑下来,300 到 500 块人民币是常态。最近社区里一位开发者 son0ma 干了件事:把 Opus 4.6 的能力蒸馏进 Qwen3.5-27B,做出了一个叫 Qwopus3.5-27B-v3 的模型,然后在 M5 Max MacBook 上本地跑起来,还把 Claude Code 的原生缓存机制给接通了。
这不是玩具。他用这个本地模型写了一套完整的 Go 爬虫 API,从零到跑通测试,总共花了大约 10 分钟。
这篇文章拆解他的完整调优路径,顺便聊聊蒸馏模型本地部署这条路,到底走到哪一步了。
为什么是蒸馏,为什么是 Qwen3.5
先说背景。所谓"蒸馏",简单讲就是让一个小模型去模仿大模型的输出行为。Opus 4.6 是 Anthropic 目前最强的模型,百万 token 上下文、ARC-AGI-2 跑到 68.8%、SWE-Bench Verified 80.8%,代理编码能力一骑绝尘。但它的问题也很直接:贵,而且只能走云端 API。
Qwen3.5-27B 是通义千问系列的开源模型,参数量适中,社区生态活跃,关键是——它能在消费级硬件上跑。v3 版本的蒸馏重点放在了 Opus 4.6 的工具调用(tool use)逻辑上,这意味着它不只是学会了"怎么回答问题",还学会了"怎么调工具、怎么跟 Claude Code 配合"。
这个区别很重要。之前的蒸馏版本在对话质量上还行,但一接 Claude Code 就各种不兼容——工具调用格式对不上、缓存机制接不住。v3 专门针对这些问题做了优化。
部署调优:每一步都有坑
第一步:扔掉 LM Studio,换 OMLX
很多人本地跑模型的第一反应是 LM Studio,但在 Mac 上这不是最优解。son0ma 的建议是直接用 OMLX(https://omlx.ai/),原因很简单:它底层直接走 Apple 的 MLX 框架,对 Apple Silicon 的优化是原生级别的。
MLX 是苹果 2026 年主推的机器学习框架,跟 PyTorch 的关系类似于 Metal 跟 OpenGL 的关系——专门为自家芯片写的,内存管理、计算调度都是针对统一内存架构来的。实际体验上最明显的差异是首字延迟(Time to First Token),用 MLX 跑模型不会出现那种"罚站"式的长时间等待。
第二步:模型选对格式
这里有个容易踩的坑:Mac 用户必须选 MLX 格式的模型文件,不是 GGUF,不是 safetensors,是 MLX。
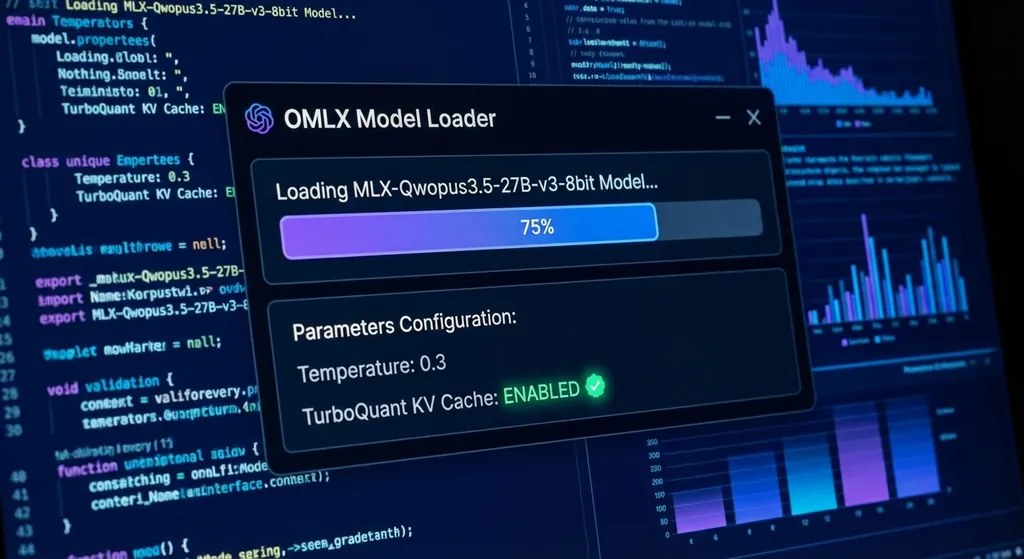
具体型号:MLX-Qwopus3.5-27B-v3-8bit
8bit 量化在 27B 参数量下是个合理的平衡点——模型大小控制在 15GB 左右,M5 Max 的统一内存完全吃得下,精度损失在开发场景下几乎感知不到。
第三步:参数微调
两个关键设置:
- Temperature 设 0.3:做开发不是写小说,你需要的是确定性和一致性,不是创造力。0.3 够低,让模型输出稳定,但又不至于像 0 那样完全贪心解码、丧失灵活性。
- 必开 TurboQuant KV Cache:这是 M5 系列芯片的杀手级特性。KV Cache 是 Transformer 推理时缓存历史 key-value 对的机制,开了之后模型不用每次都重新计算完整上下文。M5 Max 更狠的一点是——KV Cache 可以溢出到 SSD。这意味着即使上下文窗口很长,内存不够了也不会直接崩,而是优雅降级到 SSD 缓存。
第四步:接入 Claude Code
这是整个方案最精彩的部分。
既然 Qwopus3.5 蒸馏的就是 Opus 的工具调用逻辑,那最佳搭档自然是 Claude Code(cc)。OMLX 在首页直接提供了 Claude Code 的快捷启动命令,不需要额外装 cc-switch 之类的工具来切换后端。
启动后,Claude Code 会把本地 OMLX 暴露的 API 端点当作后端,所有的工具调用、文件读写、命令执行都走本地模型推理。
但真正的难点在缓存。Claude Code 原生有一套 prompt caching 机制——它会把系统提示词(system prompt)缓存起来,后续对话不用重复发送,既省 token 又降延迟。之前的蒸馏版本接 Claude Code 时,这个缓存机制是废的,每次对话都要重新发完整的系统提示词。
v3 版本解决了这个问题。实测下来,缓存命中率已经达到了"每次都能把 cc 的系统提示词缓存进去"的水平。这不是小事——Claude Code 的系统提示词本身就很长,缓存住了意味着每轮对话能省掉大量重复计算。
实战:用 Go 写一套邮箱 API
son0ma 选了一个很实际的测试场景:给 outlook.tw 这个临时邮箱服务写一套 Go API 封装,包括生成邮箱和查询邮件两个接口。
整个过程分几个阶段:
第一轮:基础代码生成(约 4 分钟)
让模型直接写 Go 代码实现邮箱生成和邮件查询的 API 封装。没给响应示例,让它自己判断接口返回格式。第一次跑失败了——模型对响应结构的猜测不对。
第二轮:自我修正(约 6 分钟)
把实际的输出内容喂回去,模型自己打印输出、分析响应结构、修正解析逻辑。这个过程很像一个真人开发者 debug 的思路:先看实际返回了什么,再调代码。
到这里,邮箱生成功能已经跑通了。
第三轮:口头微调 + 自测(约 1.5 分钟)
用自然语言告诉模型调整一些细节,然后模型进入 Claude Code 的自测模式——自己跑测试、验证结果。son0ma 要求测试在 35 秒内完成,模型照做了。
第四轮:端到端验证
用刚生成的邮箱给自己发一封邮件,然后调查询接口验证能不能收到。跑通。
总耗时大约 10 分钟。son0ma 自己的评价是:"如果我自己用古法编程的话,用 Go 实现刚刚的逻辑,至少也得 20 到 30 分钟。"
这个方案的边界在哪
说完优点,得聊聊局限性。
27B 参数量的蒸馏模型,再怎么优化也不是 Opus 4.6 本体。在以下场景中,差距会比较明显:
- 复杂架构设计:涉及多模块协调、大规模重构的任务,本地模型的规划能力和上下文理解深度还是不够。这类任务老老实实用 Opus。
- 超长上下文:Opus 4.6 有百万 token 的上下文窗口,蒸馏模型的有效上下文要短得多。大型代码库的全局分析,本地模型力不从心。
- 多语言混合项目:蒸馏过程中的训练数据分布决定了模型在不同语言上的表现不均匀,Go 和 Python 表现不错,但一些小众语言可能会翻车。
son0ma 自己的策略也很清楚:重度规划用 Opus,日常轻量开发和分析任务交给本地模型。这是一个混合方案,不是替代方案。
如果你不想折腾本地部署
不是每个人都有 M5 Max,也不是每个人都愿意花时间调参数。如果你的需求是"用最低成本调到最好的模型",那走 API 聚合平台是更务实的选择。
比如通过 OpenAI Hub 这类平台,一个 API Key 就能调 Opus、GPT、Gemini、DeepSeek 等主流模型,接口兼容 OpenAI 格式,国内直连。对于那些"日常用 Sonnet 省钱、关键时刻切 Opus"的开发者来说,这种灵活切换的能力比本地部署更实际。
下面是一个通过 OpenAI Hub 调用 Claude 模型的示例,接口格式完全兼容 OpenAI SDK:
from openai import OpenAI
client = OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://api.openai-hub.com/v1\"
)
response = client.chat.completions.create(
model=\"claude-opus-4-6\",
messages=[
{\"role\": \"system\", \"content\": \"你是一个 Go 语言开发助手。\"},
{\"role\": \"user\", \"content\": \"帮我写一个 HTTP 客户端,封装 outlook.tw 的邮箱生成 API。\"}
],
temperature=0.3
)
print(response.choices[0].message.content)
// Node.js / TypeScript 示例
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'your-openai-hub-key',
baseURL: 'https://api.openai-hub.com/v1',
});
const response = await client.chat.completions.create({
model: 'claude-opus-4-6',
messages: [
{ role: 'system', content: '你是一个 Go 语言开发助手。' },
{ role: 'user', content: '帮我写一个 HTTP 客户端,封装 outlook.tw 的邮箱生成 API。' },
],
temperature: 0.3,
});
console.log(response.choices[0].message.content);
把 model 参数换成 claude-sonnet-4 或者 gpt-5.3-codex 就能无缝切换模型,代码一行不用改。
蒸馏这条路,走到哪了
退一步看,Qwopus3.5 这个项目代表的趋势比它本身更值得关注。
2026 年初,社区里的蒸馏实践已经从"能跑就行"进化到了"能用来干活"。几个关键变化:
-
蒸馏目标从对话质量转向工具调用能力。v3 版本专门蒸馏 Opus 的 tool use 逻辑,这说明社区已经意识到,对于开发者来说,模型会不会调工具比会不会聊天重要得多。
-
硬件生态在快速补齐。MLX 框架的成熟、M5 系列芯片的 KV Cache SSD 溢出能力、OMLX 这类专门为 Mac 优化的推理工具——这些拼图正在一块块到位。一年前在 Mac 上跑 27B 模型还是勉强能用,现在已经是"舒服地用"了。
-
与专业工具链的兼容性在提升。Claude Code 缓存兼容这个问题的解决,意味着蒸馏模型不再是一个孤立的玩具,而是可以嵌入到真实的开发工作流里。
当然,这条路的天花板也很清楚。蒸馏模型的能力上限取决于教师模型和蒸馏方法,27B 参数量能承载的知识密度有限。它不会取代 Opus 4.6,就像本地编译不会取代 CI/CD 一样——但它能覆盖你 60% 到 70% 的日常开发场景,而这部分场景原来每天要烧掉你 300 块。
动手指南:最小可行路径
如果你手上有一台 M4 Pro 及以上的 Mac,想复现这个方案,最短路径如下:
- 安装 OMLX:https://omlx.ai/
- 下载模型:在 OMLX 内搜索
MLX-Qwopus3.5-27B-v3-8bit - 配置参数:Temperature 0.3,开启 TurboQuant KV Cache
- 启动 Claude Code 对接:使用 OMLX 首页提供的快捷命令
- 开始干活
如果你是 Linux + NVIDIA 用户,走 llama.cpp 或 vLLM 也能跑,但需要自己处理模型格式转换和 Claude Code 的对接配置,折腾程度会高不少。社区里有人在单卡 4090 上用 llama.cpp 跑通了 27B 的 GGUF 版本,性能也还行,但 KV Cache 的优化不如 MLX 方案优雅。
最后一个建议:不管你选本地部署还是 API 调用,都别把鸡蛋放一个篮子里。本地模型处理日常任务,云端 API 兜底复杂场景,这个组合在 2026 年的性价比是最高的。
参考来源
- Opus 4.6 蒸馏 Qwen3.5 实测与 Claude Code 缓存兼容方案(linux.do 原帖) — 原作者 son0ma 的首发实测帖,包含完整部署过程和爬虫测试截图
- 接上次 Opus 4.6 蒸馏 Qwen3.5 27B 本地部署优化方案(linux.do 后续) — 从 LM Studio 迁移到 OMLX 的优化细节和参数调优记录
- Claude Opus 蒸馏 Qwen3.5 V3 来了(知乎专栏) — V3 版本发布说明,包含环境搭建指引和基准测试工具
- Claude-Opus-4.6 蒸馏 Qwen3.5 V2 来了(知乎专栏) — V2 版本的实测数据,含单卡 4090 + llama.cpp 方案
- 实测 Claude-Opus-4.6 蒸馏版 Qwen3.5 9B(知乎专栏) — 9B 小模型版本的测试,LM Studio 图形界面部署方案
