MiniMax M2.7 开源,自我进化不是说说而已

MiniMax 正式开源旗舰多模态模型 M2.7,主打「模型自我进化」路径,经 100+ 轮无人干预自主训练后性能提升 30%,幻觉率从 89% 降至 34%,单块 A30 即可部署,开源社区再添重磅选手。
MiniMax 终于把 M2.7 的权重丢到了 Hugging Face 上。
说「终于」,是因为这款模型早在 3 月 18 日就已经发布,社区喊开源喊了快一个月,官方才磨磨蹭蹭地把模型放出来。不过好饭不怕晚——M2.7 拿出来的东西,确实值得等。
先说最核心的:什么是「自我进化」
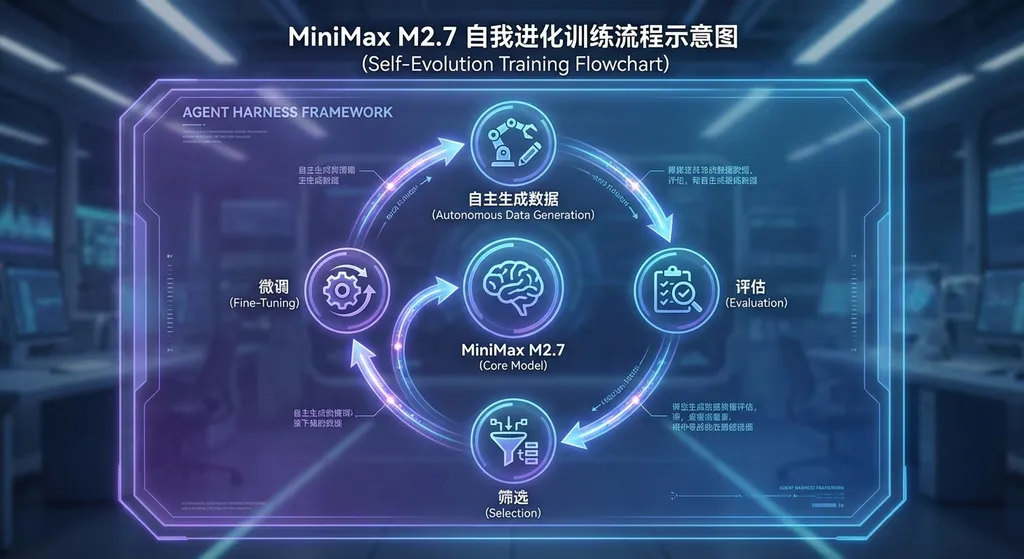
大模型圈这两年不缺新词,但 MiniMax 在 M2.7 上提的「自我进化」(Self-Evolution)不是营销话术,它背后有一套相对完整的工程实现。
简单讲,MiniMax 给 M2.7 搭了一个叫 Agent Harness 的框架。你可以把它理解成一个「模型训练自己的脚手架」——模型在这个框架里充当 Agent,自主生成训练数据、评估自身输出质量、筛选高质量样本,然后用这些样本反过来微调自己。整个过程跑了 100 多轮,期间不需要人工干预。
这跟传统的 RLHF 路线有本质区别。RLHF 依赖人类标注员给反馈,成本高、速度慢、天花板受限于标注质量。M2.7 的做法更像是让模型自己当老师和学生,形成一个闭环的自我改进循环。
听起来有点像 AlphaGo 的自我对弈?方向上确实类似,但难度不同。围棋有明确的胜负判定,语言模型的输出质量评估要模糊得多。MiniMax 的解法是让模型在具体的 Agent 任务场景中验证自己——能不能正确调用 API、能不能完成多步推理、生成的代码能不能跑通。这些都是有明确对错的,天然适合做自动化评估。
数字说话:提升到底有多大
直接看几个关键指标:
- 整体性能较上一代 M2.5 提升约 30%
- 幻觉率从 M2.5 的 89% 骤降至 34%
- 在多个编码和 Agent 基准测试中表现突出
- 部署门槛大幅降低,单块 A30 GPU 即可运行
幻觉率这个数字值得单独说。89% 到 34%,降了将近 60 个百分点,这在大模型迭代中是非常罕见的跨度。要知道,幻觉问题一直是大模型落地的最大障碍之一,很多团队花了大量精力也只能把幻觉率降个几个百分点。M2.7 能做到这个程度,大概率跟自我进化训练中大量的事实性验证环节有关——模型在 Agent 任务中反复校验自己的输出,等于在训练过程中就内置了一层 fact-checking。
不过,这里有个需要注意的地方:这些数据来自 MiniMax 官方和部分媒体报道,具体的评测基准和测试集细节还需要社区进一步验证。开源之后,相信很快会有独立的第三方评测跟上。
编码能力:开发者最关心的部分
从社区反馈来看,M2.7 在编码场景的表现是最让人惊喜的。
知乎上有开发者分享了实际使用体验,评价是「从一个强模型向工程级别的生产系统进化」。这个说法有点高,但也不是没有道理。M2.7 在以下几个编码场景中表现比较突出:
- 多文件项目的上下文理解和代码生成
- 复杂 API 调用链的编排
- 代码 Debug 和错误定位
- 从需求描述到可运行代码的端到端生成
特别是 Agent 场景下的工具调用能力,M2.7 明显比同级别的开源模型更稳定。这也好理解——它的训练过程本身就是在 Agent 框架里完成的,等于天然对工具调用做了大量的强化训练。
对于日常写代码的开发者来说,M2.7 开源意味着你多了一个可以本地部署的选择。单块 A30(24GB 显存)就能跑,这个门槛在旗舰级模型里算是相当友好了。如果你的团队有数据隐私方面的顾虑,不方便把代码发到云端 API,本地部署一个 M2.7 是个靠谱的方案。
当然,如果你不想折腾部署,直接通过 API 调用也很方便。MiniMax M2.7 已经可以通过兼容 OpenAI 格式的 API 来调用,比如 OpenAI Hub 就已经支持了这个模型,切换起来基本零成本:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="minimax-m2.7",
messages=[
{"role": "system", "content": "你是一个资深 Python 开发者。"},
{"role": "user", "content": "帮我写一个异步爬虫框架的核心调度器,要求支持并发限制和失败重试。"}
],
temperature=0.7
)
print(response.choices[0].message.content)
用的就是标准的 OpenAI SDK,改个 base_url 和 model 名字就行,已有的代码几乎不用动。
放在行业里看:M2.7 处在什么位置
2026 年的开源大模型赛道已经相当拥挤。DeepSeek、Qwen、Llama、Mistral 各有各的生态位,MiniMax 要在这个格局里找到自己的位置,光靠跑分是不够的。
M2.7 的差异化其实很清晰:Agent 能力。
目前开源模型里,真正在 Agent 场景下做过深度优化的并不多。大部分模型的 Agent 能力是「能用」的水平,但在复杂的多步任务中容易出错、丢失上下文、工具调用格式不稳定。M2.7 因为训练过程本身就深度绑定了 Agent 场景,在这方面有天然优势。
跟闭源模型比呢?部分报道提到 M2.7 在某些基准上超越了 GPT 系列,这个说法需要谨慎看待。大模型的评测基准五花八门,在特定基准上超越某个闭源模型并不罕见,关键还是看实际使用中的综合体验。不过,M2.7 作为一个开源模型能在部分维度上接近甚至超过顶级闭源模型,这本身就说明开源阵营的追赶速度在加快。
另一个值得关注的点是部署成本。单块 A30 就能跑,这意味着中小团队甚至个人开发者都有能力部署。相比之下,很多同级别的模型动辄需要多卡甚至多机,M2.7 在模型压缩和推理优化上显然下了功夫。
「自我进化」的更大意义
抛开 M2.7 这个具体产品不谈,MiniMax 提出的「自我进化」路径本身值得行业关注。
当前大模型训练面临一个越来越现实的问题:高质量人类标注数据的供给正在接近瓶颈。互联网上的公开文本已经被各家模型翻来覆去地训练了好几遍,人工标注的成本和速度也很难再大幅提升。在这个背景下,让模型参与自身的训练过程,用模型生成的数据来训练模型,几乎是一个必然的方向。
当然,这条路也有风险。模型用自己生成的数据训练自己,如果没有足够好的质量控制机制,很容易陷入「模型退化」——生成质量越来越差,形成恶性循环。MiniMax 的 Agent Harness 框架通过在具体任务中验证输出质量来规避这个问题,思路是对的,但长期效果还需要观察。
从更宏观的视角看,如果自我进化这条路走通了,大模型的迭代速度会进一步加快。以前一个模型从训练到发布可能需要半年,未来可能缩短到几周甚至更短。这对整个行业的竞争格局会产生深远影响。
开源社区的反应
从 Linux.do 论坛的讨论来看,社区对 M2.7 开源的反应是「等得花儿都谢了,但还是很高兴」。模型权重已经上传到 Hugging Face(MiniMaxAI/MiniMax-M2.7),开发者可以直接下载使用。
社区比较关注的几个问题:
- 量化版本什么时候出?原版模型虽然单卡能跑,但量化后能进一步降低显存需求,让更多人用上。
- 微调支持如何?开源模型的价值很大程度上取决于微调的便利性,社区期待官方或第三方尽快提供 LoRA 等微调方案。
- 长上下文能力如何?Agent 场景往往涉及很长的对话历史和工具调用记录,上下文窗口的实际可用长度是个关键指标。
这些问题的答案,随着社区的深入测试会逐渐明朗。开源的好处就在这里——不用等官方挤牙膏,社区自己就会把模型的能力边界摸清楚。
写在最后
MiniMax M2.7 的开源,给国产开源大模型阵营补上了一块重要拼图:一个在 Agent 场景下经过深度优化、部署门槛足够低、且有独特技术路线的旗舰模型。
它不完美。官方公布的数据还需要独立验证,「自我进化」的长期效果也有待观察,社区生态的建设更是刚刚起步。但在 2026 年这个时间点,一个国产团队能拿出这样的开源作品,本身就是一件值得关注的事。
对开发者来说,建议是:下载下来跑一跑,特别是在你自己的 Agent 和编码场景里试试。跑分是别人的,手感才是自己的。
参考来源:
- Linux.do 社区讨论:MiniMax M2.7 开源 — 社区第一时间讨论帖,包含开发者反馈
- 知乎专栏:MiniMax M2.7 工程能力实测 — 开发者实际使用体验分享
