Hermes:AI Agent长出了操作系统

Nous Research 的 Hermes Agent 凭借 Skill 自进化机制和三层记忆架构,两个月斩获 4.7 万 GitHub Star,正在把 Agent 框架从一次性脚本推向自管理式 AI 操作系统的新阶段。
Hermes Agent 不只是又一个 Agent 框架,它想当你的 AI 操作系统
Nous Research 的 Hermes Agent 在过去两个月拿下了 4.7 万 GitHub Star,登顶 GitHub Trending 榜首。社区里有人用了一句话总结它的本质——"相当于养成了自己的操作系统"。
这个说法并不夸张。
过去一年,Agent 框架遍地开花,从 LangChain 到 AutoGPT 再到 OpenClaw,大家解决的核心问题都是"让大模型调工具"。但 Hermes Agent 想做的事情不太一样:它不满足于当一个执行完就失忆的临时工,而是要做一个越用越聪明、能自我进化的常驻系统。
这意味着 Agent 框架的竞争,正在从"谁的工具链更丰富"转向"谁能真正形成系统级的自管理能力"。
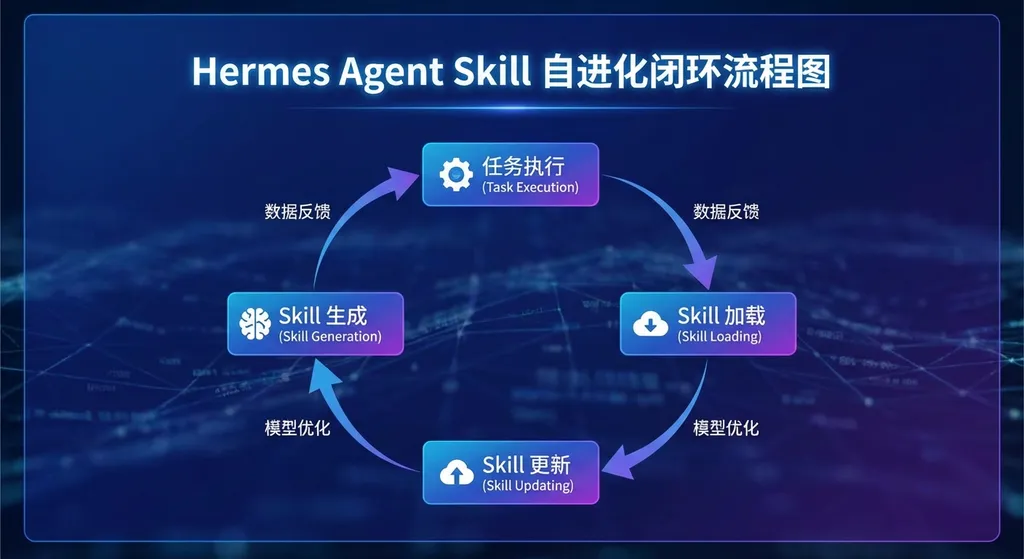
先说核心卖点:Skill 自进化闭环
大多数 Agent 框架的工作模式是这样的:接收指令 → 拆解任务 → 调用工具 → 返回结果。下次再来同样的任务,它从零开始,什么都不记得。
Hermes Agent 加了一个关键环节——经验沉淀。
当你让它完成一个复杂任务,比如"用 Docker 部署一个 PostgreSQL 集群,配置主从复制和自动备份",它不会干完就走。任务结束后,Hermes 会自动生成一份结构化的 Skill 文档(SKILL.md),里面包含任务目标、工具链选择、踩过的坑、最终方案和验证方法。
下次遇到类似任务,它直接加载这份 Skill,跳过试错阶段。
更关键的是,如果这次执行中发现了更优解——比如一个更轻量的 Docker 镜像,或者更简洁的 docker-compose 写法——Hermes 会主动更新 Skill 文档,保留版本历史。这就形成了一个完整的闭环:
创建 Skill → 使用 Skill → 发现缺口 → 更新 Skill → 再次使用
用人话说:第一次它是新手,第二次它是熟手,第三次它可能比你还熟。
实测中,有开发者让 Hermes 做 AI 资讯抓取任务,第一次它用了比较笨的方式爬取和解析,生成了初始 Skill。第二次执行同样任务时,它加载了上次的 Skill,但发现某些网站改了页面结构,于是自动调整抓取逻辑并更新 Skill。到第三次,整个流程已经非常丝滑。
这不是什么玄学,本质上是把 Agent 的执行轨迹结构化存储,然后在后续任务中做检索和复用。但 Hermes 把这件事做成了框架级的一等公民,而不是让开发者自己去拼。
三层记忆模型:从"金鱼记忆"到"老员工"
支撑 Skill 系统运转的,是 Hermes 的三层记忆架构。
第一层是工作记忆,也就是当前对话的上下文。这个每家都有,没什么特别的。
第二层是情景记忆,记录的是历史交互中的关键事件和偏好。比如你习惯用 pnpm 而不是 npm,你的项目统一用 ESLint flat config,你讨厌在代码里写 any——这些信息会被持久化,下次对话自动加载。
第三层就是前面说的 Skill 记忆,存储的是结构化的问题解决能力。
三层记忆配合起来,效果是这样的:工作记忆让它理解你当前在干什么,情景记忆让它知道你是谁、你喜欢什么,Skill 记忆让它知道这类问题该怎么解决。
打个比方:普通 Agent 像你在咖啡店随便抓了个人帮忙干活,Hermes 更像一个跟了你三年的助理——知道你的习惯,熟悉你的项目,还会主动优化工作流程。
当对话过长、接近模型上下文窗口极限时,Hermes 不会粗暴截断历史消息,而是调用 LLM 对历史对话做摘要压缩,把几十条消息浓缩成几条关键信息。既保留了上下文连贯性,又腾出了 Token 空间。这个细节看似不起眼,但在长任务场景下体验差距很大。
40+ 内置工具,但重点不是数量
Hermes Agent 内置了 40 多个工具,覆盖 MLOps、GitHub 操作、Web 浏览、终端命令、视觉理解、TTS 等场景。数量上不算惊人,真正有意思的是它的工具管理方式。
所有工具采用自注册模式(Self-registering tools)。每个工具文件在导入时主动调用 registry.register() 把自己登记到注册表。想加新工具?写个 Python 文件,实现 register() 方法,扔到 tools 目录,重启就行。不需要改核心代码。
# 自定义工具示例:注册一个简单的文本摘要工具
from hermes.tools.registry import registry
@registry.register(
name="text_summarizer",
description="对输入文本生成摘要",
toolset="nlp" # 工具集分组
)
def text_summarizer(text: str, max_length: int = 200) -> str:
# 这里可以调用任意 LLM API 来做摘要
pass
工具还支持工具集分组(Toolset Grouping),可以按运行环境启用或禁用。比如在 Telegram 上跑时,禁用 terminal 工具集——你肯定不希望有人通过聊天窗口执行 rm -rf /。在本地 CLI 模式下则可以全开。
这种设计思路很"操作系统":核心调度层保持精简,能力通过可插拔的模块扩展,权限按场景隔离。
Agent Loop:一次请求的完整生命周期
Hermes 的 Agent Loop 设计得相当精密。一次请求从进入到完成,大致经过这些阶段:
用户输入
├── 加载情景记忆 + 检索相关 Skill
├── 构建 API 请求 (model, messages, tools, reasoning config)
├── LLM 调用
│ ├── 纯文本回复 → 直接返回
│ └── 工具调用请求
│ ├── 执行工具
│ ├── 将结果注入上下文
│ └── 循环回到 LLM 调用
├── 上下文压缩(如接近 Token 上限)
└── 任务完成 → 触发后台经验提炼(Background Review)
其中有三个值得注意的机制:
Delegate Task(并行子任务):遇到可以并行处理的子任务时,Hermes 会拆分出多个子 Agent 并行执行,而不是串行等待。比如同时查三个不同 API 的文档,不需要一个一个来。
Background Review(后台经验提炼):任务完成后,Hermes 会在后台异步分析这次执行的轨迹,提炼出可复用的经验,更新到 Skill 系统。这个过程不阻塞用户交互。
上下文压缩:前面提到的摘要式压缩,在 Loop 中作为一个自动触发的环节存在,开发者不需要手动管理。
全平台会话连续:一个 Agent,到处跑
通过 hermes gateway 命令,同一个 Agent 实例可以同时接入 Telegram、Discord、Slack、WhatsApp、Signal,甚至 Home Assistant。
你在地铁上用 Telegram 发了个部署任务,到公司在 Slack 里查看进度,回家用语音助手问结果——全平台会话连续,记忆共享。
这个能力对于把 Hermes 当"个人 AI 助理"来用的场景非常关键。它不再是绑定在某个聊天窗口里的工具,而是一个跨平台的持久化服务。
开放生态:agentskills.io
Hermes 的 Skill 系统遵循 agentskills.io 开放标准。这意味着:
- 你训练出来的 Skill 可以导出、分享给其他人
- 别人的 Skill 可以直接导入你的 Hermes 实例
- 不同 Agent 框架之间,理论上可以互通 Skill
用参考资料里的类比:这就像 Docker Hub,只不过交换的不是容器镜像,而是结构化的问题解决能力。
如果这个生态真的跑起来,意味着 Agent 的能力积累不再是从零开始。你部署一个新的 Hermes 实例,从社区导入一批高质量 Skill,它立刻就是一个"有经验的员工"。
安全性:B+ 评级,还有提升空间
根据社区实测,Hermes Agent 在安全测试中拿到了 B+ 评级,10 次注入攻击拦截了 6 次,暴露了 3 个高危漏洞。
坦率说,这个成绩不算优秀。对于一个定位为"常驻 AI 操作系统"的框架来说,安全性应该是最高优先级。毕竟它有终端执行权限、有持久化记忆、还能跨平台运行——一旦被注入恶意指令,后果比普通 Agent 严重得多。
好在工具集分组机制提供了一定的防护:你可以在公开渠道(如 Telegram 群)禁用高危工具集,只在受信环境下开放全部能力。但这更多是权宜之计,框架层面的安全加固还需要持续投入。
跟竞品比,Hermes 的位置在哪?
目前 Agent 框架赛道上,几个主要玩家的定位差异已经比较清晰:
- OpenClaw:工具生态广度优先,插件市场丰富,但最近稳定性问题频发,社区里不少人在找替代品
- Claude Code:编码场景深度优先,Anthropic 自家出品,跟 Claude 模型的配合最紧密,但场景相对单一
- Hermes Agent:长期陪伴 + 自我进化优先,牺牲了一部分开箱即用的便利性,换来真正的个人化体验
Hermes 的劣势也很明显:文档还在完善中,社区规模跟前两者有差距,上手门槛偏高。但它的 Skill 自进化机制确实是目前独一份的——其他框架要么没做,要么做得不够系统化。
从更宏观的视角看,Hermes 代表的趋势是 Agent 框架从"工具调用层"向"系统层"演进。以前 Agent 框架解决的是"怎么让 LLM 调工具",现在要解决的是"怎么让 Agent 形成持久化的能力积累和自我管理"。这跟操作系统的演进逻辑是一样的:从批处理到分时系统到现代 OS,核心变化就是从"执行完就结束"到"持久运行、管理资源、积累状态"。
对开发者意味着什么
Hermes Agent 采用 MIT 许可证,完全开源免费。它的底层模型调用兼容 OpenAI API 格式,这意味着你可以灵活切换不同的 LLM 后端。
如果你想快速体验不同模型在 Hermes 中的表现差异,可以通过 OpenAI Hub 这类 API 聚合服务一个 Key 切换 GPT、Claude、Gemini、DeepSeek 等主流模型,省去逐个申请 API Key 的麻烦。配置方式很简单,改一下 base_url 就行:
import openai
client = openai.OpenAI(
api_key="你的 OpenAI Hub Key",
base_url="https://api.openai-hub.com/v1"
)
# 在 Hermes 配置中指向这个 client
# 即可无缝切换 GPT-4o、Claude 4 Sonnet、Gemini 2.5 Pro 等模型
response = client.chat.completions.create(
model="gpt-4o", # 或 claude-4-sonnet、gemini-2.5-pro、deepseek-r1 等
messages=[{"role": "user", "content": "分析这段代码的性能瓶颈"}]
)
不同模型在 Agent 场景下的表现差异很大——推理能力强的模型在任务拆解环节更靠谱,上下文窗口大的模型在长任务中更稳定,响应速度快的模型在多轮工具调用中体验更好。多试几个,找到适合你场景的组合。
写在最后
Hermes Agent 两个月 4.7 万 Star 的成绩说明社区对"自进化 Agent"这个方向是有真实需求的。大家受够了每次对话都从零开始的 Agent,想要一个真正能积累经验、越用越顺手的 AI 助手。
但 Star 数不等于成熟度。Hermes 目前仍处于快速迭代期,安全性需要加固,文档需要补全,Skill 生态需要时间培育。它更适合愿意折腾、有一定技术基础的开发者尝鲜,而不是拿来直接上生产环境。
不过方向是对的。Agent 框架从"一次性脚本"走向"自管理操作系统",这条路迟早要走。Hermes 只是第一个把这件事做得足够系统化、足够引人注目的选手。
后面的故事,取决于 Nous Research 能不能把 Skill 生态真正做起来。如果 agentskills.io 能成为 Agent 领域的 Docker Hub,那 Hermes 的护城河就不只是代码,而是网络效应。
参考来源
- Linux.do 社区讨论:hermes 挺有意思的,相当于自己的操作系统 — 社区用户对 Hermes Agent "AI 操作系统"定位的讨论
- 知乎专栏:Hermes Agent「会自我进化」的开源 AI Agent — Hermes Agent 自进化机制与 Nous Research 技术路线分析
