逆向协议自动变文档,Anything Analyzer 开源了

开源工具 Anything Analyzer 能从注册机、2API 等协议分析场景中自动生成结构化文档,直接喂给 AI 编写对接代码,把过去需要手动抓包、人肉整理的苦力活压缩到几分钟内完成。
一个让逆向工程师少熬几个通宵的工具
4 月 13 日,一个名为 Anything Analyzer 的开源项目在 Linux.do 开发调优板块冒了出来。作者给它的定位很直白——"傻瓜式生成注册机/2API 协议分析文档,直接喂给 AI 写代码"。
说人话:你有一个需要逆向分析的目标(注册机、某个软件的私有 API 协议),这个工具帮你把协议细节自动整理成结构化的 Markdown 文档,然后你把文档丢给 Claude、GPT 或者 DeepSeek,让 AI 直接帮你写对接代码。
听起来像是把两件原本割裂的事——协议逆向和代码生成——用一份文档粘在了一起。
它到底解决了什么问题
做过协议逆向的人都知道,最痛苦的不是抓包本身,而是抓完之后的整理工作。
一个典型的场景:你用 Wireshark 或者 mitmproxy 截获了几十个请求,每个请求的 Header、Body、参数命名、加密方式、签名算法都不一样。你得一个个看,一个个记,最后在脑子里(或者在一个乱糟糟的笔记里)拼出完整的协议图谱。这个过程少则几小时,多则几天。
然后你开始写代码。写到一半发现某个字段的含义理解错了,回去重新看抓包记录,再改代码。循环往复。
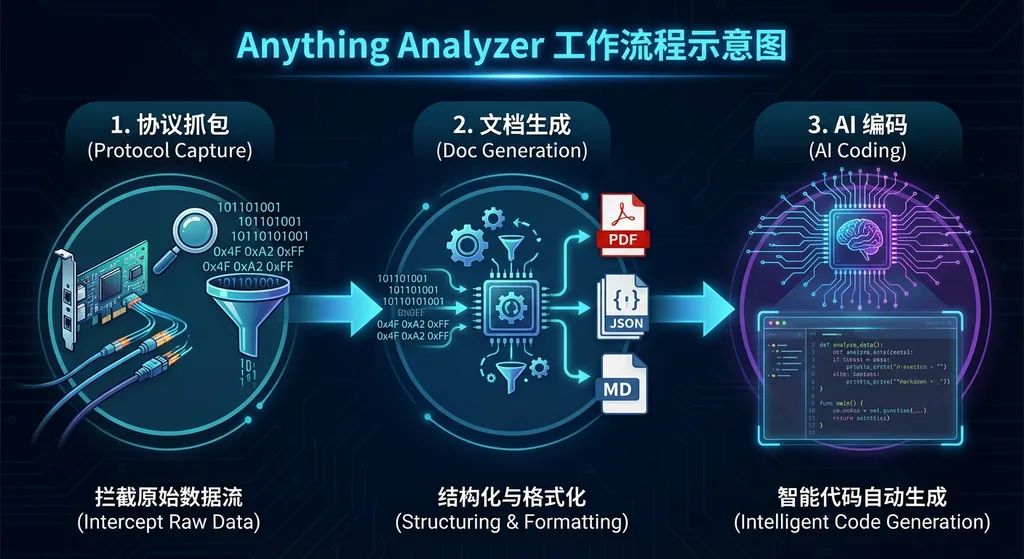
Anything Analyzer 想干掉的就是中间那个"人肉整理"的环节。它的思路是:
- 你把抓包数据、二进制样本或者协议交互记录喂给它
- 它自动分析请求/响应结构、参数类型、加密特征、调用顺序
- 输出一份格式规整的 Markdown 文档,包含端点列表、参数说明、认证流程、数据结构定义
- 这份文档的格式天然对 AI 友好——你直接复制粘贴到任何一个大模型的对话框里,它就能理解并生成对接代码
关键在第 3 步和第 4 步之间的衔接。不是随便写个文档就能让 AI 准确生成代码的。文档的结构、术语的一致性、上下文的完整性,都直接影响 AI 的输出质量。Anything Analyzer 在文档生成这一步做了针对性的优化,确保输出的格式是大模型能高效消费的。
从 CLI-Anything 的思路说起
如果你关注过最近开源社区的动态,会发现 Anything Analyzer 的设计哲学和另一个项目 CLI-Anything 有异曲同工之处。
CLI-Anything 的核心是什么?一份大约 600 行的 Markdown 文档——HARNESS.md。它本质上是一份极其精心设计的 SOP(标准操作流程),喂给 AI Agent 之后,Agent 就能按步骤分析源码、设计架构、写代码、写测试、打包发布。整个过程中,CLI-Anything 自己没写一行"引擎代码",全靠提示词驱动。
腾讯云开发者社区的一篇技术分析把这个模式总结得很到位:
一份极其精心设计的提示词(SOP)+ AI Agent 自身的编码能力 = 自动生成完整的工具
Anything Analyzer 走的是同一条路,只不过应用场景从"给开源软件生成 CLI"变成了"给私有协议生成分析文档"。两者的共同点是:把人类的经验沉淀成结构化文档,让 AI 来执行具体的脏活累活。
CLI-Anything 的 HARNESS.md 里那些规则,不是凭空想出来的,是团队在实际构建 20 多个 CLI 工具的过程中踩坑踩出来的——每踩一次,就往文档里加一条约束。Anything Analyzer 的协议分析模板大概率也是类似的演进路径:先手动分析几十个协议,总结出共性模式,再把这些模式固化成自动化流程。
技术细节:它是怎么做到的
从目前公开的信息来看,Anything Analyzer 的工作流程可以拆成几个阶段:
阶段一:数据输入
支持多种输入格式。你可以直接喂 pcap 抓包文件、HAR 文件(浏览器开发者工具导出的那种)、甚至是手动整理的请求日志。对于注册机场景,还支持直接输入二进制样本进行静态分析。
阶段二:协议识别与结构化
这一步是核心。工具会自动识别:
- 请求端点和 HTTP 方法
- 参数类型(Query、Body、Header)
- 数据编码方式(JSON、Form、Protobuf、自定义二进制格式)
- 认证和签名机制(Token、HMAC、RSA 等)
- 请求之间的依赖关系(比如先调 A 拿到 token,再用 token 调 B)
对于加密字段,它不会帮你破解(那是另一个层面的事),但会标注出"这个字段疑似 AES-CBC 加密"、"这个签名看起来是 HMAC-SHA256"之类的特征信息,给后续的人工确认和 AI 编码提供线索。
阶段三:文档生成
输出的 Markdown 文档大致长这样(简化示例):
# Target Protocol Analysis
## Authentication Flow
1. POST /api/auth/init
- Request: {\"device_id\": \"<string>\", \"timestamp\": <int>}
- Response: {\"challenge\": \"<base64>\", \"session\": \"<string>\"}
- Note: timestamp 需要是 UTC 秒级时间戳
2. POST /api/auth/verify
- Headers: {\"X-Session\": \"<session from step 1>\"}
- Request: {\"response\": \"<computed_challenge_response>\"}
- Signature: HMAC-SHA256(body, key=challenge)
- Response: {\"token\": \"<jwt>\", \"expires_in\": 3600}
## Core Endpoints
### GET /api/license/check
- Headers: {\"Authorization\": \"Bearer <token>\"}
- Query: {\"product_id\": \"<string>\", \"machine_hash\": \"<string>\"}
- Response: {\"valid\": <bool>, \"features\": [...]}
- Rate Limit: 10 req/min per token
注意这个格式。每个端点的请求、响应、签名方式、依赖关系都写得清清楚楚。你把这份文档丢给任何一个主流大模型,它都能直接生成对应的 Python/Node.js/Go 客户端代码。
阶段四:AI 编码(你来完成的部分)
拿到文档之后,你可以选择自己喜欢的方式让 AI 帮你写代码。直接粘贴到 ChatGPT 对话框是最简单的方式,但更高效的做法是通过 API 调用,把文档作为 system prompt 的一部分传进去,让模型在完整的上下文中生成代码。
比如你想用 Claude 来生成 Python 客户端代码,可以这样调:
import openai
# 通过 OpenAI Hub 调用 Claude,国内直连,兼容 OpenAI 格式
client = openai.OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://openai-hub.com/v1\"
)
# 读取 Anything Analyzer 生成的协议文档
with open(\"protocol_analysis.md\", \"r\") as f:
protocol_doc = f.read()
response = client.chat.completions.create(
model=\"claude-sonnet-4-20250514\", # 也可以换成 gpt-4o、deepseek-chat 等
messages=[
{
\"role\": \"system\",
\"content\": f\"你是一个资深后端工程师。以下是目标服务的 API 协议分析文档:\
\
{protocol_doc}\
\
请根据这份文档生成完整的 Python 客户端代码,包含认证流程、错误处理和重试逻辑。\"
},
{
\"role\": \"user\",
\"content\": \"生成一个完整的 Python SDK,使用 httpx 作为 HTTP 客户端,支持异步调用。\"
}
],
temperature=0.3,
max_tokens=8000
)
print(response.choices[0].message.content)
这里用 OpenAI Hub 的好处是你不用为每个模型单独管理 API Key 和 endpoint——同一个 Key 可以切换 GPT、Claude、Gemini、DeepSeek,哪个模型对你的协议文档理解得更好就用哪个。实际体验下来,Claude 在处理复杂协议逻辑时的表现通常比较稳,而 DeepSeek 在中文场景下的性价比很高。
社区反馈:开发者怎么看
从 Linux.do 的讨论帖来看,这个项目发布当天就收到了不少关注。帖子的互动量不算爆炸,但质量不错——来的基本都是真正做逆向或者协议对接的开发者。
有意思的是社区的协作氛围。一位开发者在帖子里说:
"这种小活我可以自己改嘛佬友,我现在改了自己先用用稳定了再 PR?佬友还是把时间用在开发核心功能上吧"
这句话透露了两个信息:一是工具确实有人在用,而且用到了需要改动的程度;二是社区已经自发形成了分工意识——有人负责核心功能,有人负责边缘优化,通过 PR 协作。对于一个刚发布的开源项目来说,这是个好信号。
截至发稿,项目在 Linux.do 上的浏览量已经过百,Star 数还在早期积累阶段。
放在更大的背景下看
2026 年的 AI 工具生态正在经历一个明显的转向:从"AI 直接帮你做事"到"AI 需要更好的输入才能帮你做好事"。
过去两年,大家的注意力都在模型能力上——GPT-4 能不能写代码、Claude 能不能做推理、DeepSeek 能不能搞数学。但到了 2026 年,模型能力的天花板已经很高了,瓶颈反而出现在了输入端:你怎么把问题描述清楚,怎么把上下文组织好,怎么让模型拿到它需要的全部信息。
Anything Analyzer 就是这个趋势下的产物。它解决的不是"AI 能不能写代码"的问题(当然能),而是"AI 写代码之前需要什么信息"的问题。协议文档就是那个关键的中间层——把人类的逆向分析经验翻译成 AI 能高效消费的格式。
类似的思路在其他领域也在发生。CLI-Anything 用 HARNESS.md 驱动 Agent 生成 CLI 工具;EverythingAgent 用结构化的任务描述驱动 Windows 桌面自动化;AutoGPT 用任务分解机制把复杂目标拆成可执行的子任务链。底层逻辑都一样:与其让 AI 猜你要什么,不如把需求结构化地喂给它。
它的局限性
说完好的,也得说说不足。
首先,协议逆向本身是一个高度依赖经验的领域。Anything Analyzer 能自动化的是"整理和格式化"这一步,但前置的抓包、解密、定位关键请求,仍然需要人来做。它不是一个端到端的逆向工具,更像是逆向工作流中的一个加速器。
其次,对于复杂的自定义二进制协议(比如游戏客户端的私有通信协议),自动识别的准确率还有待验证。这类协议往往没有明显的结构特征,字段边界需要靠经验判断。工具能给出初步的分析结果,但大概率需要人工校正。
第三,生成的文档质量直接决定了 AI 编码的质量。如果输入的抓包数据不完整(比如漏掉了某个关键的认证步骤),文档里就会有缺失,AI 生成的代码自然也会有问题。垃圾进,垃圾出——这个基本原则不会因为多了一层自动化就失效。
最后,合规性问题。协议逆向在不同法律体系下的合法性边界不同。工具本身是中性的,但使用者需要自己判断具体场景是否合规。这一点作者在项目说明里也有提及。
跟现有方案比怎么样
在 Anything Analyzer 之前,开发者做协议分析主要靠这几种方式:
- 纯手工:Wireshark + 记事本,最灵活但最慢
- mitmproxy 脚本:写 Python 脚本自动解析特定格式的请求,但每个目标都要重新写
- Postman/Insomnia 导入:能整理 HTTP 请求,但不做协议分析,也不生成 AI 友好的文档
- 各种逆向框架(Frida、xposed 等):侧重于运行时 Hook,不侧重文档生成
Anything Analyzer 的差异化在于"文档生成"这个环节。它不试图替代 Wireshark 或 Frida,而是接在它们后面,把分析结果转化成 AI 能直接使用的格式。这个定位很聪明——不跟成熟工具抢地盘,而是补上工作流中缺失的一环。
如果非要类比的话,它有点像 Swagger/OpenAPI 之于 REST API 的关系。Swagger 不帮你设计 API,但它把 API 的描述标准化了,于是代码生成、文档渲染、测试工具都能基于这个标准来做。Anything Analyzer 想做的是类似的事——只不过面向的不是你自己设计的 API,而是别人的、需要逆向分析的协议。
对开发者的实际价值
说到底,这个工具值不值得关注?
如果你的日常工作涉及协议对接、接口逆向、或者需要频繁分析第三方服务的 API 行为,那值得试试。它不会让你从零变成逆向高手,但能让已经会逆向的人效率翻倍——尤其是在"分析完了要写代码"这个阶段。
如果你只是偶尔需要对接一两个公开 API,那大概率用不上。公开 API 通常自带文档,不需要逆向。
一个比较实际的使用场景:你在做一个聚合类产品,需要对接十几个没有公开 API 文档的第三方服务。以前你可能需要一个个抓包、一个个整理、一个个写对接代码,每个服务花两三天。现在你可以用 Anything Analyzer 把整理环节压缩到半小时以内,然后让 AI 批量生成对接代码的初稿,你只需要 review 和调整。十几个服务的对接周期可能从一个月缩短到一周。
这就是工具的价值——不是替代你,而是把你从重复劳动中解放出来,让你把时间花在真正需要判断力的地方。
写在最后
2026 年的开源社区越来越务实了。大家不再追求"造一个大而全的平台",而是聚焦在工作流中的某个具体痛点,用最小的代价解决它。Anything Analyzer 就是这种思路的典型代表——它不试图做一个完整的逆向工具链,只做"协议分析 → 结构化文档"这一件事,然后把后续的编码工作交给 AI。
项目刚发布,还在早期阶段。功能完善度和社区生态都需要时间来验证。但方向是对的——在 AI 编码能力越来越强的今天,谁能更好地组织输入信息,谁就能更高效地利用 AI。
感兴趣的开发者可以去 Linux.do 的原帖看看,顺手 Star 一下。开源项目的早期,每一个真实用户的反馈都比一百个 Star 更有价值。
参考来源
- Anything Analyzer 原帖 — Linux.do 开发调优板块 — 项目发布帖及社区讨论
- Linux.do 开发调优分类 — 项目所在的社区板块,含相关技术讨论
