Hermes Agent 0.9.0 发布:本地 Web 管理界面上线

开源 AI Agent 框架 Hermes 升级至 0.9.0 版本,新增本地 Web Dashboard、Fast Mode 优先处理队列、iMessage 和微信集成等重磅功能,降低配置门槛的同时大幅提升多模型调用体验。
Hermes Agent 0.9.0 发布:本地 Web 管理界面上线
开源 AI Agent 框架 Hermes 刚刚发布 0.9.0 版本,最大的变化是引入了本地 Web Dashboard——一个浏览器管理界面,让你不用再手动改配置文件或敲命令行。这对很多开发者来说是个实实在在的效率提升,尤其是那些需要频繁切换模型、调整参数的场景。
这次更新不只是加了个界面这么简单。Hermes 同时推出了 Fast Mode 优先处理队列、完整的 iMessage 集成,以及微信/企业微信的原生支持。从功能布局看,Hermes 正在从一个纯粹的 Agent 框架,向「多模型统一调度 + 多渠道消息集成」的方向演进。
Web Dashboard:告别配置文件地狱
Hermes 之前的配置方式是典型的开源项目风格:YAML 文件 + 命令行参数。对熟悉 DevOps 的开发者来说不算什么,但对想快速上手的人来说,光是搞清楚各个配置项的作用就得花不少时间。
新版的 Web Dashboard 把这些操作都搬到了浏览器里:
- 配置管理:模型参数、API Key、超时设置等,都能在界面上直接修改
- 会话监控:实时查看 Agent 的运行状态、请求日志、错误信息
- 技能浏览:查看和管理 Hermes 支持的各种 Skills(工具调用能力)
- 网关管理:统一管理多个 API 网关的配置和路由规则
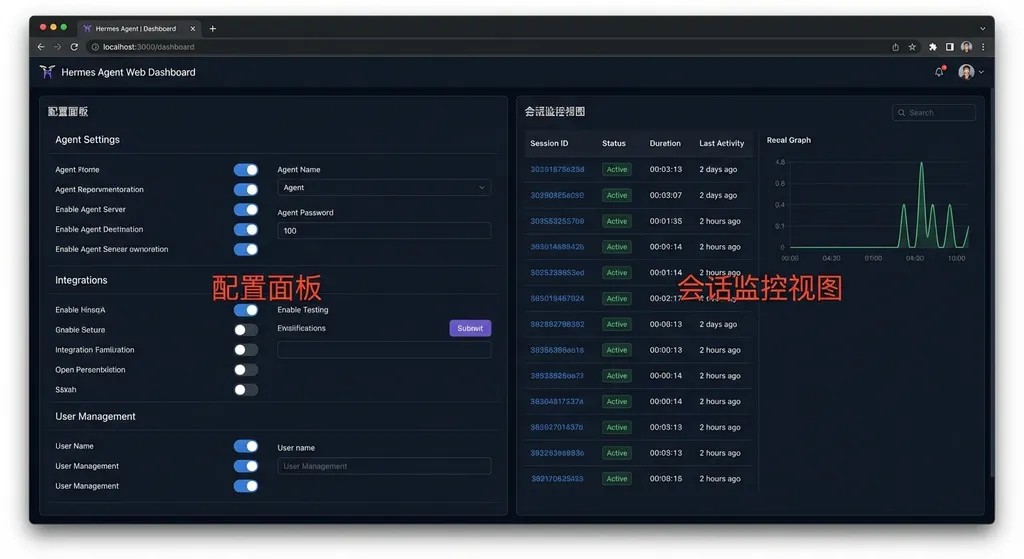
这个 Dashboard 是本地运行的,不需要额外的服务器部署。启动 Hermes 后,直接在浏览器访问 localhost:端口 就能用。对于需要在本地调试 Agent 逻辑的开发者来说,这比 SSH 进服务器改配置文件要直观得多。
从产品思路上看,这是 Hermes 在降低使用门槛。类似的趋势在很多开源项目里都能看到——Kubernetes 有 Dashboard,Prometheus 有 Grafana,开发者工具链正在从「CLI 优先」向「GUI 可选」转变。不是说命令行不好,而是不同场景需要不同的交互方式。
Fast Mode:优先队列的实际价值
Hermes 0.9.0 引入了 /fast 命令,可以让请求走优先处理队列。目前支持 OpenAI 和 Anthropic 的部分模型,包括 GPT-5.4、Codex 和 Claude 系列。
这个功能的背景是:主流 AI 服务商都有多层级的 API 服务。OpenAI 有 Priority Processing,Anthropic 有 Fast Tier,本质上都是「加钱换速度」。但问题在于,这些优先级设置通常是账户级别的,不能按请求动态调整。
Hermes 的 Fast Mode 做的事情是:在 Agent 层面提供一个开关,让你可以针对单次请求决定是否使用优先队列。实际场景里,这个能力很有用:
- 交互式对话:用户在等回复的时候,延迟敏感,可以开 Fast Mode
- 批量处理:跑数据分析、内容生成这种任务,几秒钟的延迟无所谓,走普通队列省钱
- 混合场景:同一个 Agent 同时处理实时请求和后台任务,按需切换
从成本角度看,这也是一种优化手段。OpenAI 的 Priority Processing 价格是普通 API 的 1.5-2 倍,如果所有请求都走优先队列,成本会明显上升。Hermes 让你可以精细化控制,只在需要的时候加速。
如果你在用 OpenAI Hub 这类 API 聚合平台,Fast Mode 的价值会更明显。因为聚合平台本身就支持多模型切换,再加上优先级控制,你可以根据任务类型、用户等级、成本预算等因素,动态选择「用哪个模型 + 走哪个队列」。
iMessage 和微信集成:消息渠道的扩展
Hermes 0.9.0 新增了两个消息渠道的原生支持:
iMessage via BlueBubbles
BlueBubbles 是一个开源项目,可以把 iMessage 的消息转发到其他平台。Hermes 现在直接集成了 BlueBubbles,意味着你可以把 AI Agent 接入 iMessage,通过苹果的消息生态来交互。
这个功能的实际应用场景包括:
- 个人助理:在 iMessage 里直接问 AI 问题,不用切换到其他 App
- 团队协作:把 Agent 拉进 iMessage 群组,提供实时信息查询、任务提醒等服务
- 自动化工作流:结合 iOS 的快捷指令,实现更复杂的自动化场景
Hermes 的实现包括自动 Webhook 注册、设置向导集成、崩溃恢复机制。从代码提交记录看(#6437, #6460, #6494),这个功能经过了多次迭代,说明团队在稳定性上下了功夫。
微信和企业微信
Hermes 通过 iLink Bot API 支持微信,同时为企业微信提供了 Callback Mode 适配器。这对国内开发者来说是个重要更新——微信生态的 AI Bot 需求一直很旺盛,但官方 API 的限制和审核流程让很多开发者头疼。
企业微信的 Callback Mode 是自建企业应用的标准接入方式。Hermes 的适配器支持:
- 流式响应:打字机效果的消息推送
- 媒体上传:图片、文件等多媒体内容的处理
- Markdown 渲染:在企业微信里展示格式化的 AI 回复
从技术实现上看,Hermes 没有选择第三方微信 Bot 框架(比如 Wechaty),而是直接对接官方 API。这种做法的好处是稳定性更高、功能更完整,缺点是需要企业认证和应用审核。对于正式的企业应用来说,这个路径更靠谱。
多模型调度的实际挑战
Hermes 本质上是一个 AI Agent 框架,但它的核心能力之一是「多模型统一调度」。这次更新的几个功能——Web Dashboard、Fast Mode、多渠道集成——都在强化这个能力。
实际场景里,多模型调度的复杂度比想象中高:
1. 模型能力差异
不同模型的强项不一样。GPT-4 擅长推理,Claude 擅长长文本,DeepSeek 在代码生成上有优势。一个好的 Agent 框架需要根据任务类型自动选择模型,或者让开发者可以灵活配置路由规则。
2. 成本和延迟的权衡
OpenAI 的 GPT-4 很强,但也很贵。DeepSeek 便宜,但在某些任务上效果不如 GPT-4。开发者需要在成本和效果之间找平衡,这就需要框架层面提供足够的控制粒度。
3. API 兼容性问题
虽然大部分模型都声称兼容 OpenAI 格式,但实际上各家的实现细节不一样。参数名称、错误码、流式响应的格式,都可能有差异。一个成熟的 Agent 框架需要处理这些兼容性问题。
4. 多渠道消息的格式转换
iMessage、微信、Slack、Discord,每个平台的消息格式都不一样。AI 生成的 Markdown 内容,需要转换成各个平台支持的格式。图片、文件等多媒体内容的处理也各有差异。
Hermes 的这次更新,在这几个方向上都有推进。Web Dashboard 降低了配置门槛,Fast Mode 提供了成本优化的手段,多渠道集成解决了消息格式转换的问题。
与 API 聚合平台的配合
如果你在用 OpenAI Hub 这类 API 聚合平台,Hermes 的价值会更明显。因为聚合平台本身就解决了「一个 Key 调所有模型」的问题,Hermes 在这个基础上提供了更高层的能力:
Agent 逻辑编排
API 聚合平台负责模型调用,Hermes 负责 Agent 的工作流编排。比如一个客服 Bot,可能需要先调用 Embedding 模型做知识库检索,再调用 LLM 生成回复,最后调用 TTS 模型生成语音。这些步骤的编排,就是 Agent 框架的工作。
多渠道消息路由
用户可能从微信、iMessage、Web 页面等不同渠道发起对话。Hermes 可以把这些消息统一路由到同一个 Agent 实例,保持上下文的连贯性。
成本和性能优化
结合 API 聚合平台的多模型支持和 Hermes 的 Fast Mode,你可以实现很精细的成本控制策略。比如:
- VIP 用户的请求走 GPT-4 + Fast Mode
- 普通用户的请求走 Claude 3.5 Sonnet
- 批量任务走 DeepSeek
下面是一个结合 OpenAI Hub 使用 Hermes 的示例配置:
# Hermes 配置文件示例
models:
- name: gpt-4-turbo
provider: openai-hub
api_key: ${OPENAI_HUB_KEY}
base_url: https://api.openai-hub.com/v1
priority: high
- name: claude-3-5-sonnet
provider: openai-hub
api_key: ${OPENAI_HUB_KEY}
base_url: https://api.openai-hub.com/v1
priority: medium
- name: deepseek-chat
provider: openai-hub
api_key: ${OPENAI_HUB_KEY}
base_url: https://api.openai-hub.com/v1
priority: low
routing:
- condition: user.tier == "vip"
model: gpt-4-turbo
fast_mode: true
- condition: task.type == "code_generation"
model: deepseek-chat
fast_mode: false
- default:
model: claude-3-5-sonnet
fast_mode: false
channels:
- type: imessage
bluebubbles_url: http://localhost:1234
- type: wechat
ilink_api_key: ${WECHAT_KEY}
- type: wecom
corp_id: ${WECOM_CORP_ID}
callback_token: ${WECOM_TOKEN}
如果用 Python 代码来调用,可以这样写:
import asyncio
from hermes import HermesAgent, Message
async def main():
# 初始化 Hermes Agent
agent = HermesAgent(
config_path="hermes_config.yaml",
dashboard_enabled=True,
dashboard_port=8080
)
# 发送消息到 Agent
message = Message(
content="帮我写一个 Python 快速排序的实现",
user_id="user_123",
channel="imessage",
metadata={
"user_tier": "vip",
"task_type": "code_generation"
}
)
# 使用 Fast Mode
response = await agent.send(
message,
fast_mode=True # 启用优先队列
)
print(f"模型: {response.model_used}")
print(f"延迟: {response.latency_ms}ms")
print(f"内容: {response.content}")
# 查看 Dashboard
print(f"Dashboard 地址: http://localhost:8080")
await agent.close()
if __name__ == "__main__":
asyncio.run(main())
这个例子展示了 Hermes 的几个核心能力:
- 通过配置文件定义多个模型和路由规则
- 根据用户等级和任务类型自动选择模型
- 动态控制是否使用 Fast Mode
- 支持多个消息渠道的统一接入
开源 Agent 框架的竞争格局
Hermes 不是唯一的开源 Agent 框架。类似的项目还有 LangChain、AutoGPT、AgentGPT 等。每个框架的定位和侧重点不太一样:
LangChain:更偏向于 LLM 应用开发的基础库,提供了丰富的组件和工具链,但学习曲线比较陡。
AutoGPT:强调自主性,Agent 可以自己规划任务、调用工具、迭代优化。但实际使用中,完全自主的 Agent 往往不够可控。
Hermes:定位在「多模型调度 + 多渠道集成」,更像是一个生产级的 Agent 运行时。这次更新的 Web Dashboard 和 Fast Mode,都在强化这个定位。
从产品策略上看,Hermes 选择了一个相对务实的方向:不追求 AGI 级别的自主性,而是专注于解决实际场景中的工程问题——模型切换、成本优化、消息路由、配置管理。这些问题看起来不性感,但确实是开发者在生产环境中会遇到的。
值得关注的细节
除了主要功能,Hermes 0.9.0 还有一些值得注意的细节:
1. 崩溃恢复机制
iMessage 集成的代码里专门提到了 crash resilience。对于长时间运行的 Agent 服务来说,这是个重要的工程问题。网络抖动、API 超时、内存泄漏,都可能导致进程崩溃。一个好的框架需要有自动恢复和状态保存的能力。
2. 流式响应的光标处理
微信集成支持 streaming cursor,这是个很细节的功能。流式响应的时候,如果直接把每个 token 都发送出去,用户会看到消息不断刷新,体验不好。更好的做法是累积一定数量的 token,或者遇到标点符号的时候再发送。Hermes 的实现考虑到了这个细节。
3. 多次迭代的代码提交
从 GitHub 的 PR 编号可以看出,很多功能都经过了多次迭代。比如 iMessage 集成有 #6437、#6460、#6494 三个 PR,Fast Mode 有 #6875、#6960、#7037 三个 PR。这说明团队在功能稳定性上比较谨慎,不是一次性把代码合并进去就完事。
实际应用场景
结合这次更新的功能,Hermes 比较适合以下几类场景:
企业内部 AI 助手
通过企业微信集成,可以快速搭建一个企业内部的 AI 助手。员工可以在企业微信里直接问问题,Agent 根据问题类型自动选择合适的模型。比如查询类问题用便宜的模型,复杂推理用 GPT-4。
多渠道客服 Bot
同时接入微信、iMessage、Web 页面等多个渠道,用户从任何渠道发起对话,都能保持上下文的连贯性。结合 Fast Mode,可以给 VIP 用户提供更快的响应速度。
开发者工具集成
把 Hermes 集成到 IDE 或命令行工具里,提供代码生成、Bug 分析、文档查询等功能。通过 Web Dashboard 可以方便地调整模型参数和查看运行日志。
内容生成工作流
批量生成文章、翻译、摘要等内容。通过配置不同的模型和优先级,在成本和质量之间找到平衡。比如初稿用便宜的模型,润色用 GPT-4。
总结
Hermes 0.9.0 的更新方向很明确:降低使用门槛,提升多模型调度的灵活性,扩展消息渠道的覆盖面。Web Dashboard 让配置变得更直观,Fast Mode 提供了成本优化的手段,iMessage 和微信集成拓展了应用场景。
从产品定位上看,Hermes 正在从一个纯粹的 Agent 框架,向「生产级 AI 应用运行时」的方向演进。这个方向是对的——开发者需要的不只是一个能跑起来的 Demo,而是一个能稳定运行、方便管理、成本可控的生产系统。
如果你正在构建多模型的 AI 应用,或者需要把 Agent 接入多个消息渠道,Hermes 值得一试。尤其是配合 OpenAI Hub 这类 API 聚合平台使用,可以快速搭建一个功能完整、成本可控的 AI 服务。
参考来源
- Hermes 升级到 0.9.0 讨论帖 - Linux.do - 社区用户对 Hermes 0.9.0 新功能的讨论和使用反馈
