Google AI Edge Gallery:手机本地跑大模型的时代到了

Google 正式推出 AI Edge Gallery 应用,支持在 Android 和 iOS 设备上本地运行 Gemma 4、DeepSeek、Qwen 等开源大模型,无需联网、无需 Token 费用,端侧 AI 进入实用阶段。
Google 上周正式发布了 AI Edge Gallery,一个可以在手机上直接跑大模型的官方应用。支持 Gemma 4、DeepSeek、Qwen 等主流开源模型,Android 和 iOS 双端可用,不需要联网,不需要付 Token 费。
这不是一个概念 Demo。它已经上架 Google Play 和 App Store,任何人都能下载。
这东西到底是什么
AI Edge Gallery 的定位很明确:做端侧开源大模型的官方入口。你可以把它理解为手机上的 Ollama——但 Google 帮你把模型适配、量化、运行时优化这些脏活全干了。
打开应用后,你能看到一个模型列表,目前支持的模型包括:
- Gemma 4 E2B(约 1.5GB)
- Gemma 4 E4B(约 3GB)
- DeepSeek 系列
- Qwen 系列
- 其他社区热门开源模型
选一个模型,点下载,等几分钟,就能开始本地对话。整个过程不需要配置环境、不需要命令行、不需要懂量化是什么。
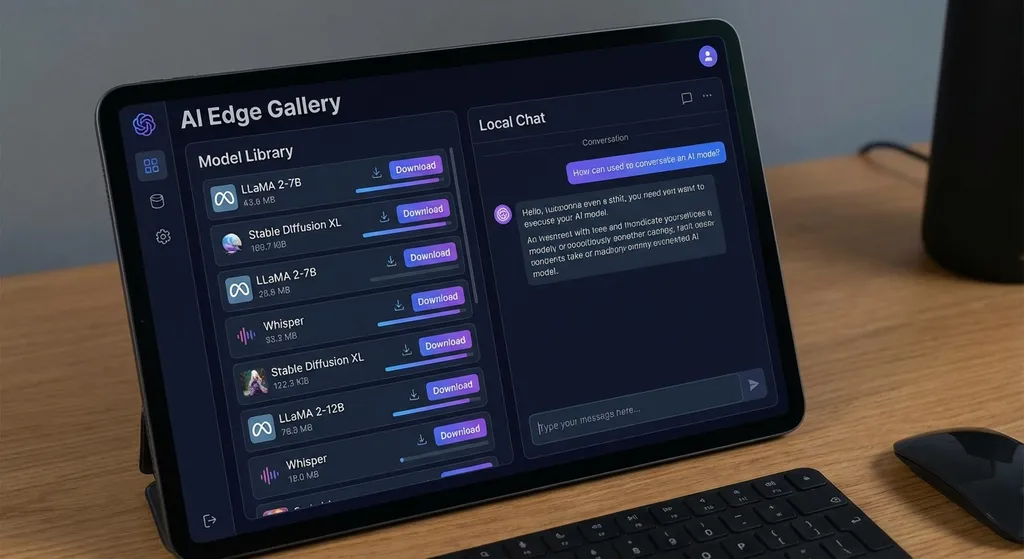
但它不只是一个聊天框。Google 给它塞了几个值得注意的能力:
- 本地聊天:纯离线对话,数据不出设备
- 音频转录:支持语音输入和音频文件转文字
- 图像识别:拍照或选图后让模型分析
- 思考模式:目前仅支持 Gemma 4 系列,类似 Chain-of-Thought 推理
换句话说,这不是一个玩具,而是一个多模态的本地 AI 工具箱。
硬件门槛:没你想的那么高,也没那么低
先说系统要求:
- Android:最低 Android 12,需要 Google 认证设备(Google Certified Device),8GB 以上内存
- iOS:8GB 以上 RAM,意味着 iPhone 15 Pro 及以上
- 搭载 M 芯片的 Mac 也能通过 App Store 安装 iOS 版本运行
国内 Android 用户大概率没有 Google Play,但 Google 在 GitHub 上提供了 APK 直接下载:
https://github.com/google-ai-edge/gallery/releases/download/1.0.11/ai-edge-gallery.apk
实际体验下来,跑 Gemma 4 E4B(Q4_K_M 量化,约 3GB)在 8GB 内存的设备上基本流畅,但有几个现实问题需要正视:
第一,首次下载模型需要联网,而且模型文件不小。E4B 量化后大约 3GB,E2B 小一些但能力也弱一些。在国内网络环境下,下载速度可能不太理想。
第二,推理速度和桌面端没法比。Gemma 4 采用自回归架构,生成长文本时速度会明显下降——计算量随 Token 数量呈平方级增长。让它写一篇千字文章,你能明显感觉到后半段越来越慢。
第三,发热和耗电是真实存在的。持续推理十几分钟,手机会明显发烫。这不是 Google 的问题,是物理定律的问题。
但话说回来,能在一台手机上跑一个 4B 参数的多模态模型,放在两年前是不可想象的事情。
Gemma 4:这次 Google 是认真的
要理解 AI Edge Gallery 的意义,得先看看 Gemma 4 本身。
Google 在 4 月 2 日以 Apache 2.0 协议开源了 Gemma 4,基于 Gemini 3 开发,推出了四个版本:
| 版本 | 参数量 | 上下文长度 | 适用场景 | |------|--------|-----------|----------| | E2B | ~2B | 128K | 手机、IoT 设备 | | E4B | ~4B | 128K | 手机、平板 | | 26B MoE | 26B | 256K | 工作站、服务器 | | 31B Dense | 31B | 256K | 服务器、云端 |
几个关键变化:
首先是授权。之前的 Gemma 版本有各种使用限制,这次直接切到了 Apache 2.0——和 Mistral、Qwen 一样,完全无限制的开源协议。这意味着你可以拿它做商业产品,不用担心法律问题。
其次是能力跃升。31B 和 26B MoE 版本在 Arena AI 文字基准测试中分别排到了开放模型的第 3 和第 6 名,超过了参数量更大的 Mistral-Large3 和 DeepSeek-v3.2。小参数量打大参数量,这在开源模型里不常见。
然后是功能完整度。Gemma 4 原生支持函数调用(Function Calling)、结构化 JSON 输出、系统指令、140+ 语言,四个版本全部支持图像和视频理解,E2B 和 E4B 还支持音频输入。这不是一个只能聊天的模型,而是一个可以构建 Agent 工作流的基座。
这些能力组合在一起,再配上 AI Edge Gallery 这个分发渠道,Google 的意图很清楚:让端侧 AI 从「能跑」变成「能用」。
对开发者意味着什么
如果你是 Android 开发者,这件事的影响比较直接。
Google 同步提供了 ML Kit Gen Prompt API,可以在 Android 应用中直接调用本地的 Gemma 4 模型。Android Studio 中也集成了 Gemma 4 的 AI 编程辅助。这意味着你可以在自己的 App 里嵌入一个完全离线的 AI 能力,不需要依赖任何云端 API。
想象几个场景:
- 一个笔记应用,离线状态下也能做内容摘要和智能搜索
- 一个翻译工具,在没有网络的环境下(比如出国旅行)依然可用
- 一个医疗或金融类应用,敏感数据完全不出设备
- 一个工业巡检工具,在没有信号的厂房里也能做图像识别
隐私和离线,是端侧 AI 最硬的两张牌。
但现实一点说,端侧模型的能力上限摆在那里。E4B 是 4B 参数,哪怕优化再好,和云端的 GPT-4o、Claude Sonnet、Gemini Pro 这些百亿甚至万亿参数的模型比,差距是客观存在的。复杂推理、长文本生成、专业领域的深度问答,端侧模型目前还扛不住。
所以更现实的架构可能是:端侧模型处理简单、高频、隐私敏感的任务,复杂任务回落到云端 API。这也是大多数开发者会面临的选型问题。
如果你的应用需要同时调用云端的 Gemma、GPT、Claude、DeepSeek 等模型,又不想为每个模型单独对接 API,可以考虑通过 OpenAI Hub 这类聚合平台统一接入,一个 Key 搞定所有模型的调用,省去多平台管理的麻烦。
比如在云端调用 Gemma 4 的大参数版本,代码大概长这样:
import openai
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="gemma-4-27b",
messages=[
{"role": "system", "content": "你是一个专业的技术助手。"},
{"role": "user", "content": "解释一下 Mixture of Experts 架构的优势"}
],
temperature=0.7
)
print(response.choices[0].message.content)
端侧跑小模型做轻量任务,云端调大模型做重活,这套组合拳可能是接下来一段时间最务实的方案。
和竞品比,Google 这步棋走得怎样
端侧大模型这条路,不是只有 Google 在走。
苹果在 iOS 18 中已经内置了端侧模型能力,但走的是封闭路线——只能通过 Apple Intelligence 的框架调用,开发者能做的事情有限,模型也不开源。
高通和联发科都在推自己的端侧 AI 方案,但更偏底层芯片和 SDK 层面,离应用开发者还有一段距离。
Meta 的 Llama 系列也支持端侧部署,社区生态很活跃,但 Meta 自己没有做一个类似 AI Edge Gallery 这样的官方分发渠道。你要在手机上跑 Llama,得自己折腾 llama.cpp 或者第三方应用。
Google 的优势在于:它同时控制了模型(Gemma 4)、运行时(LiteRT)、分发渠道(AI Edge Gallery)和开发工具(Android Studio、ML Kit)。这是一个从模型到应用的完整闭环,而且全部开源。
这步棋的战略意图也很明显。云端 AI 的竞争已经白热化,OpenAI、Anthropic、Google、Meta 打得不可开交。但端侧 AI 还是一片相对空白的战场。Google 手握 Android 这个全球最大的移动操作系统,如果能让 Gemma 成为端侧 AI 的默认选择,这个生态价值是巨大的。
当然,挑战也很明显。国内的 Android 设备大多没有 Google Play 服务,AI Edge Gallery 虽然可以通过 APK 安装,但没有 Google 认证的设备能不能正常运行,还需要实际测试。对于国内开发者来说,这可能是一个不小的障碍。
端侧 AI 的拐点到了吗
说实话,还没有。但已经能看到拐点的轮廓了。
两年前,在手机上跑大模型还是极客的玩具——模型太大、推理太慢、体验太差。一年前,量化技术和硬件进步让「能跑」变成了现实,但「好用」还差得远。
现在,Gemma 4 E4B 这样的模型,在 8GB 内存的手机上已经能提供基本可用的多模态 AI 体验。不够惊艳,但够用。
更重要的是基础设施在成熟。Google 提供了从模型训练、量化、部署到应用开发的全套工具链。开发者不需要懂模型压缩、不需要懂推理优化,下载一个 SDK 就能在自己的 App 里集成本地 AI 能力。
接下来的 12 到 18 个月会很关键。如果芯片厂商继续推高端侧 AI 算力(高通骁龙 8 Gen 4、联发科天玑 9400 都在加码 NPU),如果模型继续在小参数量上突破能力上限,如果开发工具继续降低集成门槛——端侧 AI 就有可能从「开发者尝鲜」变成「用户日常」。
Google 用 AI Edge Gallery 押了一个注:未来的 AI 不只在云端,也在你的口袋里。
这个判断对不对,时间会给答案。但至少现在,你可以打开手机试试了。
参考来源:
- Google AI Edge Gallery 预览版上线 Android — Linux.do 社区讨论帖,包含首发体验信息
- Google 公布 Gemma 4 号称最强本地端开放模型 — iThome 详细报道,涵盖 Gemma 4 全系列技术规格
- Google AI Edge Gallery GitHub 发布页 — APK 下载及版本更新记录
