CMU 开源 Motus:多模型编排让 Agent 成本减半

卡内基梅隆团队开源 Agent 框架 Motus,通过自动路由任务到最优模型,在 SWE-bench 上达到 79% 准确率,成本不到单用 Claude Opus 的一半。
CMU 开源 Motus:多模型编排让 Agent 成本减半,SWE-bench 跑到 79%
卡内基梅隆大学计算机科学系教授 Dimitrios Skarlatos 和 Zhihao Jia 创办的 Lithos AI 刚开源了 Agent 服务框架 Motus,Apache 2.0 许可证。这个框架解决的问题很实在:当前 Agent 部署后配置是静态的,提示词、模型选择、上下文策略全都写死,而 Motus 会从每次运行中学习,自动把不同子任务路由到最合适的模型。
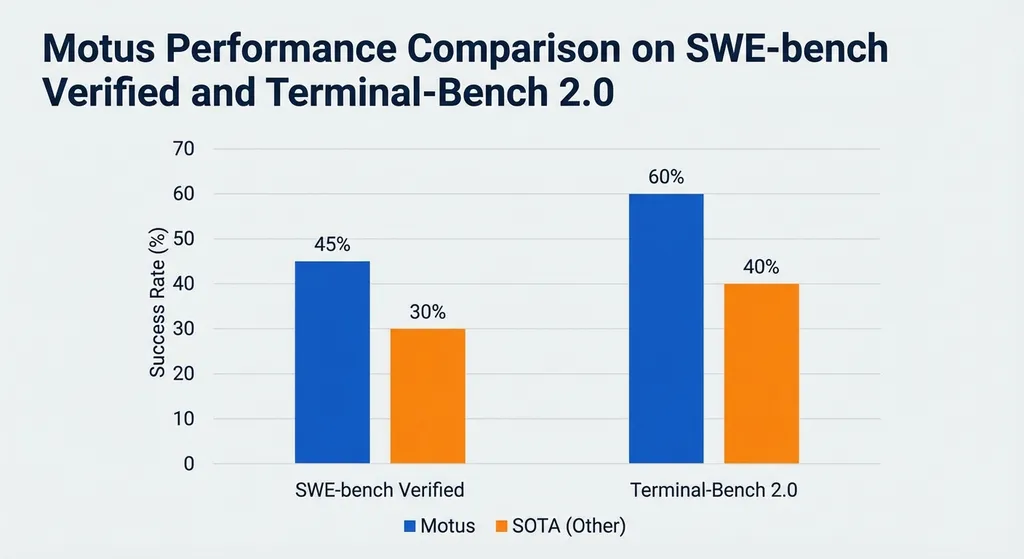
数据很直接:在 SWE-bench Verified 上,Motus 多模型编排达到 79% 准确率,高于 Claude Opus 4.6 的 75.8% 和 GPT-5.3-Codex 的 72.6%,成本不到单用 Opus 的一半。Terminal-Bench 2.0 上准确率从 64% 提到 80.1%,成本同样减半。
为什么需要动态路由
现在主流的 Agent 框架,无论是 LangChain 还是 AutoGPT,部署后基本就是一套固定配置跑到底。你选了 Claude Opus,那所有步骤都用 Opus;你设了 32K 上下文窗口,每次调用都带这么多 token。这种静态配置在开发阶段还好说,但到了生产环境就会发现问题:
- 简单的文件读取任务用 Opus 是浪费,GPT-4o-mini 就够了
- 复杂的架构设计需要 Opus 的推理能力,但你已经把预算花在前面的简单任务上了
- 有些步骤其实可以并行执行,但框架按顺序一个个跑,延迟拉得很长
Motus 的思路是:别在部署前就把所有决策定死,让系统从实际运行中学习。每次 Agent 执行任务,Motus 都会记录哪个模型在哪种子任务上表现好、成本多少、延迟如何,然后用这些数据持续优化路由策略。
团队背景值得一提。Dimitrios Skarlatos 和 Zhihao Jia 都是 CMU 计算机系教授,团队成员来自 CMU 和斯坦福,有 AWS、谷歌、Meta 和英伟达的生产基础设施经验。这不是学术项目,是奔着解决生产环境问题去的。
核心机制:从轨迹中学习
Motus 的核心是一套轨迹分析系统。当 Agent 执行一个编程任务,比如修复 GitHub issue,Motus 会把整个过程拆解成多个子任务:
- 理解 issue 描述
- 定位相关代码文件
- 分析现有实现
- 生成修复方案
- 编写测试用例
- 验证修复效果
每个子任务都会记录:
- 使用的模型和参数配置
- 任务是否成功完成
- 消耗的 token 数和成本
- 执行延迟
- 输出质量评分
系统会发现,理解 issue 和定位文件这种任务,GPT-4o 就能做得很好,没必要上 Opus。但到了生成修复方案这一步,Opus 的成功率明显更高。Motus 就会学到这个模式,下次遇到类似任务时自动做出更优的模型选择。
这套机制跟当前流行的多 Agent 框架有本质区别。CrewAI、MetaGPT 这些框架推广的是「角色扮演」模式:让不同 Agent 扮演产品经理、架构师、测试工程师,像公司部门一样传文档、跑流水线。但翻遍 Anthropic、OpenAI、谷歌的工程文档,没有一家这么干。
Anthropic 的做法更接近 Motus 的思路:把每个新会话比作「轮班工程师」,用 progress.txt 当交班记录,第一个会话由专门的 Initializer Agent 搭环境、写操作手册,后续会话读取后接着干。多 Agent 采用 orchestrator-worker 模式,一个主 Agent 拆任务,多个子 Agent 并行探索不同方向,结果回流汇总,不是流水线接力。
上下文管理的动态优化
Motus 另一个关键优化点是上下文窗口管理。当前大部分 Agent 框架要么全量保留历史对话,要么用固定的滑动窗口策略。全量保留成本高,滑动窗口又可能丢失关键信息。
Motus 会根据具体工作负载调整策略。如果是需要频繁引用早期决策的长期项目,系统会保留更多历史上下文;如果是相对独立的短任务,就只保留最近几轮对话。这个决策同样是从轨迹数据中学来的:系统会分析哪些历史信息在后续步骤中被实际使用了,哪些只是占用 token 但没起作用。
举个例子,在 SWE-bench 的任务中,Agent 需要先理解代码库结构,然后定位 bug,最后生成修复。Motus 发现,代码库结构的信息在整个过程中都会被引用,所以会一直保留在上下文中。但中间某些探索性的尝试,如果最终没有采用,就会被从上下文中移除,给后续步骤腾出 token 空间。
并行执行检测
延迟优化是 Motus 的另一个亮点。传统 Agent 框架基本是串行执行,一个步骤完成才开始下一个。但很多任务其实可以并行:比如同时分析多个可能相关的代码文件,或者并行生成多个候选方案然后选最优的。
Motus 会自动检测哪些步骤之间没有依赖关系,可以并行执行。这个检测不是靠人工标注,而是从轨迹数据中推断:如果两个步骤在历史执行中从未互相引用对方的输出,那它们很可能可以并行。
在 Terminal-Bench 2.0 的测试中,这个优化带来了明显的延迟降低。Terminal-Bench 模拟的是命令行操作任务,需要 Agent 理解用户意图、规划命令序列、执行并验证结果。Motus 发现,规划阶段可以并行生成多个候选方案,然后用一个轻量级模型快速筛选,最后只把最优方案交给重模型做最终验证。这样既保证了质量,又大幅降低了端到端延迟。
实际效果:不只是 benchmark 数字
SWE-bench 和 Terminal-Bench 的数字很亮眼,但更值得关注的是 Motus 在实际场景中的表现。Lithos AI 团队在博客中分享了几个案例:
案例一:大规模代码重构
一个客户需要把遗留系统从 Python 2 迁移到 Python 3,涉及上百个文件。用单一模型跑,要么选便宜的模型但错误率高,要么选贵的模型但成本爆炸。Motus 的策略是:
- 用 GPT-4o 做初步扫描,识别需要修改的文件和模式
- 对于简单的语法替换(比如 print 语句改成函数调用),用 GPT-4o-mini 批量处理
- 对于复杂的逻辑变更(比如字符串编码处理),用 Claude Opus 仔细分析
- 最后用 GPT-4o 做全局一致性检查
结果是准确率跟全程用 Opus 差不多,但成本降到了 40%。
案例二:API 文档生成
另一个客户需要为内部服务生成 API 文档。这个任务的特点是:理解代码逻辑需要强推理能力,但生成文档本身是相对机械的工作。Motus 的路由策略:
- 用 Claude Opus 分析每个 API 端点的功能、参数、返回值
- 用 GPT-4o 生成标准格式的文档文本
- 用 GPT-4o-mini 做格式校验和链接检查
这个组合既保证了文档质量,又把成本控制在合理范围。
与 OpenAI Hub 的集成
Motus 的多模型路由能力,跟 OpenAI Hub 这类 API 聚合平台是天然互补的。OpenAI Hub 提供统一接口调用多家模型,Motus 负责决策什么时候用哪个模型。
如果你在用 OpenAI Hub,集成 Motus 很直接。Motus 支持标准的 OpenAI API 格式,只需要在配置中指定 base_url 和可用的模型列表:
from motus import Agent, ModelRouter
# 配置 OpenAI Hub 作为模型提供方
router = ModelRouter(
base_url="https://api.openai-hub.com/v1",
api_key="your-openai-hub-key",
available_models=[
"gpt-4o",
"gpt-4o-mini",
"claude-opus-4-6",
"claude-sonnet-4",
"deepseek-chat"
]
)
# 创建 Agent,让 Motus 自动选择模型
agent = Agent(
router=router,
task_type="code_generation",
optimize_for="cost" # 或 "latency" 或 "quality"
)
# 执行任务,Motus 会根据子任务自动路由
result = agent.run(
"Fix the bug in user_service.py where login fails for users with special characters in username"
)
Motus 会在执行过程中动态选择模型。比如理解 bug 描述时用 GPT-4o,定位代码时用 Claude Sonnet,生成修复方案时用 Claude Opus,写测试用例时用 GPT-4o-mini。你不需要手动指定,系统会从历史轨迹中学习最优策略。
如果你想更细粒度地控制,也可以设置约束条件:
router = ModelRouter(
base_url="https://api.openai-hub.com/v1",
api_key="your-openai-hub-key",
available_models=["gpt-4o", "claude-opus-4-6", "deepseek-chat"],
constraints={
"max_cost_per_task": 0.50, # 单任务最高成本 50 美分
"max_latency": 30.0, # 最大延迟 30 秒
"min_quality_score": 0.85 # 最低质量分 0.85
}
)
Motus 会在满足约束的前提下优化路由策略。如果成本预算紧张,就多用 DeepSeek 和 GPT-4o-mini;如果对延迟敏感,就优先选择响应快的模型并增加并行度。
开源意味着什么
Motus 选择 Apache 2.0 许可证开源,这意味着你可以自由使用、修改、商用,不需要开源你的改动。对比之下,很多学术项目用 GPL 或者自定义限制性许可证,商业使用会有法律风险。
开源也意味着你可以看到 Motus 到底是怎么做路由决策的。这对生产环境很重要:你需要知道为什么系统在某个关键任务上选了某个模型,如果出了问题能追溯原因。Motus 提供了详细的决策日志和可视化工具,你可以看到每个路由决策的依据、备选方案、预期成本和实际效果。
从代码质量看,Motus 的实现相当工程化。核心路由逻辑只有几千行 Python,依赖项很少,没有引入重量级框架。这让它很容易集成到现有系统中,也方便根据自己的需求做定制。
比如你可能想加入自己的模型评估指标,或者对特定类型的任务使用自己训练的路由策略。Motus 的架构是模块化的,你可以替换掉默认的轨迹分析器或路由器,插入自己的实现:
from motus import Agent, TrajectoryAnalyzer, ModelRouter
class CustomAnalyzer(TrajectoryAnalyzer):
def analyze(self, trajectory):
# 你的自定义分析逻辑
# 比如加入领域特定的质量指标
pass
class CustomRouter(ModelRouter):
def route(self, task, context):
# 你的自定义路由逻辑
# 比如优先使用内部部署的模型
pass
agent = Agent(
analyzer=CustomAnalyzer(),
router=CustomRouter()
)
局限性和未来方向
Motus 目前主要针对代码相关任务优化,在 SWE-bench 和 Terminal-Bench 上效果最好。对于其他类型的任务,比如长文本写作、多模态内容生成,路由策略可能需要重新学习。团队在 GitHub 上提到,他们正在收集更多领域的轨迹数据,未来会支持更广泛的任务类型。
另一个限制是冷启动问题。Motus 需要从实际运行中学习,这意味着刚开始使用时,路由策略可能不够优化。团队提供了一些预训练的路由策略,基于他们在 SWE-bench 等 benchmark 上的数据,但如果你的任务分布跟 benchmark 差异很大,可能需要一段时间的学习期。
成本预测也不是完全准确。Motus 会根据历史数据估算每个路由决策的成本,但实际成本会受到输入长度、输出长度、模型负载等因素影响。团队建议在生产环境中设置成本上限和告警,避免意外超支。
从更大的视角看,Motus 代表了 Agent 框架的一个重要方向:从静态配置转向动态优化。当前大部分框架还停留在「搭积木」阶段,开发者需要手动设计 Agent 的工作流程、选择模型、调整参数。Motus 的思路是让系统从数据中学习这些决策,把开发者从繁琐的调优工作中解放出来。
这个方向跟大模型本身的演进是一致的。早期我们需要精心设计 prompt,现在模型的指令遵循能力强了,很多时候直接说需求就行。Agent 框架也在经历类似的演进:从手工编排到自动优化。
对开发者的实际意义
如果你正在构建基于 LLM 的应用,Motus 值得一试,尤其是在这几种场景:
- 成本敏感的生产环境:你需要在质量和成本之间找平衡,不能无限制地用最贵的模型
- 复杂的多步骤任务:任务可以拆解成多个子任务,不同子任务对模型能力的要求不同
- 需要持续优化:你的应用会长期运行,希望系统能从实际使用中学习并改进
对于简单的单次调用场景,比如一个聊天机器人或者文本分类 API,Motus 可能是过度设计。但如果你在做代码生成、自动化测试、文档处理这类复杂任务,Motus 的多模型编排能力会带来实实在在的收益。
从团队背景和开源策略看,Motus 不太可能是昙花一现的项目。CMU 的学术背景保证了技术深度,团队成员的工业界经验保证了工程质量,Apache 2.0 许可证保证了商业友好。这个项目值得持续关注。
参考来源
- CMU教授开源Agent框架Motus - Linux.do 社区讨论 - 包含 Motus 的核心设计思路和性能数据
- Motus GitHub 仓库 - 开源代码和技术文档
