OpenAI Agents SDK 更新:企业级安全与能力双提升

OpenAI 今天更新 Agents SDK,新增企业级安全控制和能力扩展机制,通过渐进式披露优化上下文管理,与 MCP 形成互补生态。
OpenAI Agents SDK 更新:企业级安全与能力双提升
OpenAI 今天(4月15日)更新了 Agents SDK,重点强化企业级安全控制和 Agent 能力扩展机制。这次更新不是简单的功能堆砌,而是针对 Agent 落地过程中两个核心痛点的系统性解决方案:如何让 Agent 既强大又可控,如何在不炸上下文的前提下扩展能力。
核心更新:Agent Skills 机制
这次更新的重头戏是 Agent Skills——一套基于渐进式披露(Progressive Disclosure)的能力扩展机制。简单说,就是让 Agent 先看到能力的"目录",需要时再加载完整内容,而不是一股脑把所有文档塞进上下文窗口。
传统做法是把所有工具文档、API 说明、使用示例全部前置加载到 System Prompt 里。一个稍微复杂点的企业场景,光是工具文档就能占掉几万 token。Agent Skills 把这个过程拆成三层:
第一层:元数据(Metadata)
只包含技能名称、简短描述、适用场景。Agent 扫一眼就知道有哪些能力可用,大概什么时候该用。这一层通常只占几百 token。
第二层:核心指令(Instructions)
当 Agent 决定使用某个技能时,才加载这部分内容。包含具体的使用方法、参数说明、注意事项。这是真正的"使用手册"。
第三层:附加资源(Scripts & References)
代码示例、配置模板、详细文档。只在 Agent 明确需要时才加载,比如遇到错误需要查看完整示例。
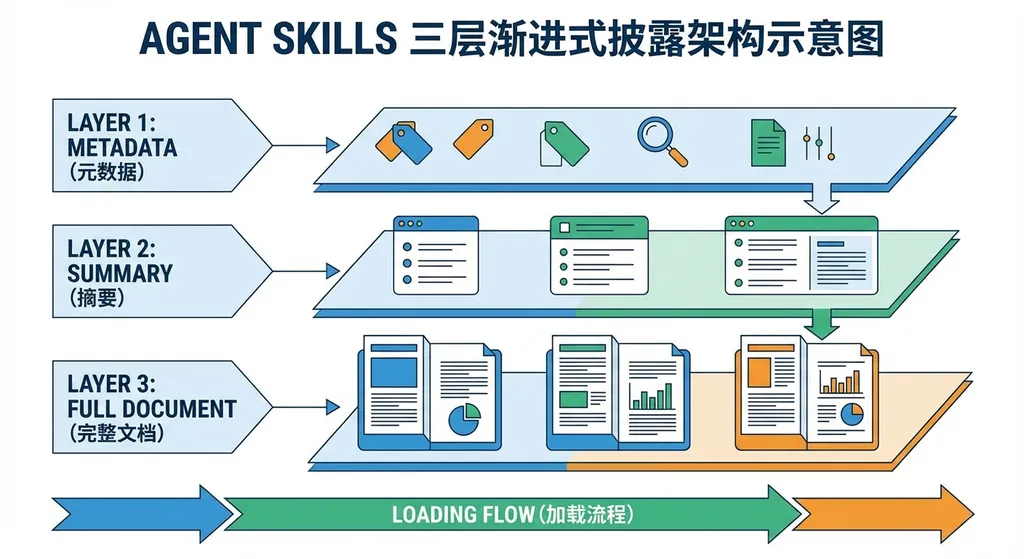
这套机制的效果很明显。OpenAI 给出的数据是,同样的能力集合,传统方式需要 16K token 的上下文,用 Skills 机制只需要 500 token 左右。对于需要集成十几个甚至几十个工具的企业 Agent 来说,这不是优化,是救命。
企业级安全控制升级
除了能力扩展,这次更新还强化了安全控制能力。OpenAI 在 SDK 层面内置了几个关键的安全护栏:
确定性优先原则
Agent Skills 的设计哲学是"确定性优先"。每个技能都要明确定义触发条件、执行边界、失败处理。不像某些 Agent 框架那样,给 LLM 一堆工具让它自己琢磨什么时候用,Skills 机制要求开发者显式声明使用场景。
这看起来限制了灵活性,但对企业场景来说是必需的。你不会希望一个客服 Agent 因为"理解错了"用户意图,就去调用删除数据库的 API。
模块化与单一职责
每个 Skill 只做一件事,做好一件事。这不仅是工程最佳实践,也是安全边界的划分方式。一个 Skill 出问题,影响范围是可控的。
审计与追溯
SDK 内置了完整的执行日志机制。每次 Skill 调用、参数传递、返回结果都有记录。出了问题能快速定位是哪个环节、哪个决策导致的。
Skills vs MCP:互补而非竞争
很多人会拿 Agent Skills 和 Anthropic 的 MCP(Model Context Protocol)对比。两者确实都在解决 Agent 能力扩展问题,但设计哲学完全不同。
MCP 是"急切加载"(Eager Loading)模式。启动时就建立所有连接,把所有可用工具的完整信息加载到上下文。优势是调用时延低,Agent 能看到完整的能力全貌。代价是上下文开销大,启动慢。
Agent Skills 是"惰性加载"(Lazy Loading)模式。启动时只加载元数据,用到时才加载完整内容。优势是上下文高效,启动快。代价是首次调用某个技能时会有额外的加载延迟。
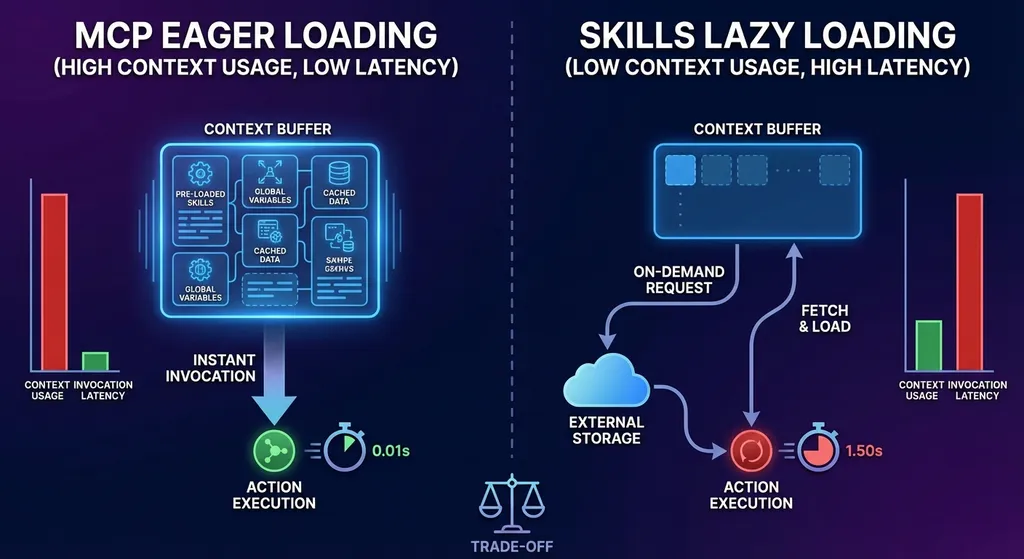
实际场景中,两者是互补的。MCP 适合需要频繁切换多个工具、对延迟敏感的交互式场景,比如 IDE 里的代码助手。Skills 适合工具集合大、但单次任务只用到少数几个工具的场景,比如企业工作流自动化。
不少团队已经在用混合架构:核心的高频工具用 MCP 连接,长尾的专用工具用 Skills 封装。OpenAI 这次更新也原生支持了 MCP,开发者可以根据场景灵活选择。
实战:如何写一个高质量的 Skill
一个 Skill 的核心是 skill.md 文件。这不是普通的 Markdown 文档,而是一份结构化的能力声明。
以一个 MySQL 数据分析 Skill 为例:
---
name: mysql_employee_analysis
description: 分析员工数据库,生成统计报告
version: 1.0.0
author: your-team
---
# MySQL 员工数据分析
## 适用场景
- 需要查询员工基本信息统计
- 需要生成部门人员分布报告
- 需要分析薪资数据趋势
## 使用方法
### 连接数据库
使用环境变量中的连接信息:
- `MYSQL_HOST`
- `MYSQL_USER`
- `MYSQL_PASSWORD`
- `MYSQL_DATABASE`
### 查询示例
**查询部门人数分布:**
```sql
SELECT department, COUNT(*) as count
FROM employees
GROUP BY department;
查询平均薪资:
SELECT AVG(salary) as avg_salary
FROM employees;
注意事项
- 只允许 SELECT 查询,不支持 INSERT/UPDATE/DELETE
- 查询结果最多返回 1000 行
- 敏感字段(如身份证号)会自动脱敏
错误处理
- 连接失败:检查环境变量配置
- 查询超时:优化 SQL 或增加索引
- 权限不足:联系 DBA 授权
关键点:
1. **元数据要精准**:`description` 要让 Agent 一眼看出这个 Skill 是干什么的,什么时候该用。别写"数据库操作工具"这种废话,要写"分析员工数据库,生成统计报告"。
2. **适用场景要具体**:不是列举功能,而是描述使用场景。Agent 看到用户说"帮我看看各部门有多少人",能立刻匹配到这个 Skill。
3. **使用方法要完整**:包括环境准备、参数说明、代码示例。但不要写成 API 文档,要写成"操作手册"。
4. **边界要清晰**:明确说明能做什么、不能做什么。这是安全控制的第一道防线。
5. **错误处理要实用**:不是列举所有可能的错误码,而是告诉 Agent 遇到常见问题怎么办。
## 在代码中使用 Skills
OpenAI Agents SDK 的 API 设计很简洁。如果你在用 OpenAI Hub,代码几乎一样,只需要改个 base_url:
```python
from openai import OpenAI
# 使用 OpenAI Hub
client = OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://api.openai-hub.com/v1\"
)
# 创建 Agent,加载 Skills
response = client.chat.completions.create(
model=\"gpt-4\",
messages=[
{
\"role\": \"system\",
\"content\": \"你是一个数据分析助手。\"
},
{
\"role\": \"user\",
\"content\": \"帮我分析一下各部门的人员分布\"
}
],
tools=[
{
\"type\": \"skill\",
\"skill\": {
\"name\": \"mysql_employee_analysis\",
\"path\": \"./skills/mysql_employee_analysis\"
}
}
]
)
print(response.choices[0].message.content)
Agent 会自动处理 Skill 的加载和调用。你看到的只是最终结果,但背后经历了:
- Agent 读取 Skill 元数据,判断是否适用
- 决定使用后,加载完整的 Instructions
- 根据 Instructions 构造 SQL 查询
- 执行查询,处理结果
- 如果遇到错误,查看错误处理说明,尝试修复
- 返回最终分析结果
整个过程对开发者是透明的。你只需要写好 Skill 定义,剩下的交给 SDK。
生态演进:标准化的必然性
Agent Skills 不是 OpenAI 的专利。Anthropic 有 MCP,Google 有 Vertex AI Extensions,各家都在建自己的能力扩展机制。但行业正在走向标准化。
原因很简单:碎片化对谁都没好处。开发者不想为每个平台写一套工具集成代码,企业不想被单一厂商锁定,模型提供商也希望有更丰富的生态。
Skills 和 MCP 的设计都是开放的。OpenAI 把 Skills 规范开源在 GitHub 上,Anthropic 的 MCP 协议也是公开的。社区已经开始出现跨平台的 Skill 仓库,一个 Skill 定义可以在多个 Agent 框架中使用。
这种标准化趋势对开发者是好事。你写的 Skill 不会因为换了个模型或框架就作废。投入是可复用的。
挑战与局限
Agent Skills 不是银弹。几个明显的局限:
学习曲线
写好一个 Skill 需要对 Agent 的工作机制有深入理解。什么信息该放在元数据,什么该放在 Instructions,什么该延迟到 References,这需要经验。
调试困难
渐进式加载虽然高效,但也增加了调试难度。Agent 为什么没选这个 Skill?是元数据写得不够清楚,还是场景匹配逻辑有问题?这些问题不像传统代码那样容易定位。
性能开销
惰性加载意味着首次调用会有额外延迟。对于实时性要求高的场景,这可能是个问题。虽然可以通过预加载优化,但又回到了上下文开销的老问题。
安全边界
再严格的 Skill 定义,也挡不住 LLM 的"创造性理解"。Agent 可能会用你意想不到的方式组合多个 Skills,产生意外的副作用。这需要在系统层面做更多的安全控制,而不是只依赖 Skill 定义。
对开发者的建议
如果你在构建企业级 Agent,这次更新值得关注。几个实用建议:
从小规模开始
不要一上来就把所有工具都改成 Skills。先选几个高频、相对独立的能力试水,积累经验后再扩展。
重视元数据质量
元数据是 Agent 决策的关键输入。花时间打磨 description 和适用场景描述,比写一堆详细文档更重要。
建立 Skill 库
把通用的 Skills 沉淀下来,形成团队的能力资产。数据库查询、文件操作、API 调用这些基础能力,写一次到处用。
监控与迭代
上线后持续监控 Skill 的使用情况。哪些 Skill 被频繁调用?哪些从来没用过?调用失败率如何?这些数据会告诉你哪里需要优化。
混合使用 MCP 和 Skills
不要非此即彼。核心工具用 MCP 保证性能,长尾工具用 Skills 节省上下文。根据场景选择合适的机制。
OpenAI 这次更新的时机也值得玩味。就在几个月前,Anthropic 刚推出 MCP 并获得广泛关注。OpenAI 的回应不是简单跟进,而是提出了一套不同的解决方案,并且原生支持 MCP。这种"竞争中合作"的态势,对整个 Agent 生态是好事。
Agent 技术正在从"能跑起来"走向"能用起来"。能力扩展和安全控制是这个过程中的两大核心问题。OpenAI 这次更新给出了一套系统性的解决方案,虽然不完美,但方向是对的。
参考资料
- OpenAI Agents SDK GitHub 仓库 - Agent Skills 官方规范和示例代码
- Agent Skills 与 MCP 对比解读 - 深入分析两种能力扩展机制的设计哲学和适用场景
- AI Agent 开发实战指南 - 从协议互联到企业级智能体落地的完整实践
