DeepL Voice API 上线:语音翻译进入实时时代

DeepL 今日正式推出 Voice API,支持实时语音转录和多语翻译。盲测显示 96% 语言学家更青睐 DeepL,这标志着语音翻译从"能用"迈向"好用"。
DeepL Voice API 上线:语音翻译进入实时时代
DeepL 今天(4月16日)正式推出了 Voice API,这是它首次进入实时语音翻译领域。这家以文本翻译质量著称的德国公司,这次直接瞄准了语音通话场景——不是简单的语音转文字再翻译,而是端到端的语音到语音实时翻译。
这个时机值得玩味。Google、Microsoft、Zoom 早就有类似功能,但 DeepL 委托 Slator 做的盲测显示,96% 的语言学家更青睐 DeepL Voice。这个数字背后的逻辑很清楚:语音翻译的战场已经从"能不能做"转向"做得好不好"。

三条产品线,各有侧重
DeepL Voice 不是单一产品,而是一个套件,包含三个方向:
Voice for Meetings:会议场景的实时翻译。这是最直接对标 Zoom、Teams 翻译功能的产品。区别在于 DeepL 强调的是"专业能力才是关键,语言并不重要"——换句话说,它想让跨国团队在开会时忘掉语言障碍这回事。
Voice for Conversations:移动端的面对面对话翻译。两个人用同一台设备,各说各的语言,实时看到翻译。这个场景其实很微妙——Google Translate 早就有类似功能,但 DeepL 的卖点是翻译质量。在商务谈判、医疗咨询这类对准确性要求高的场景,翻译质量的差距会被无限放大。
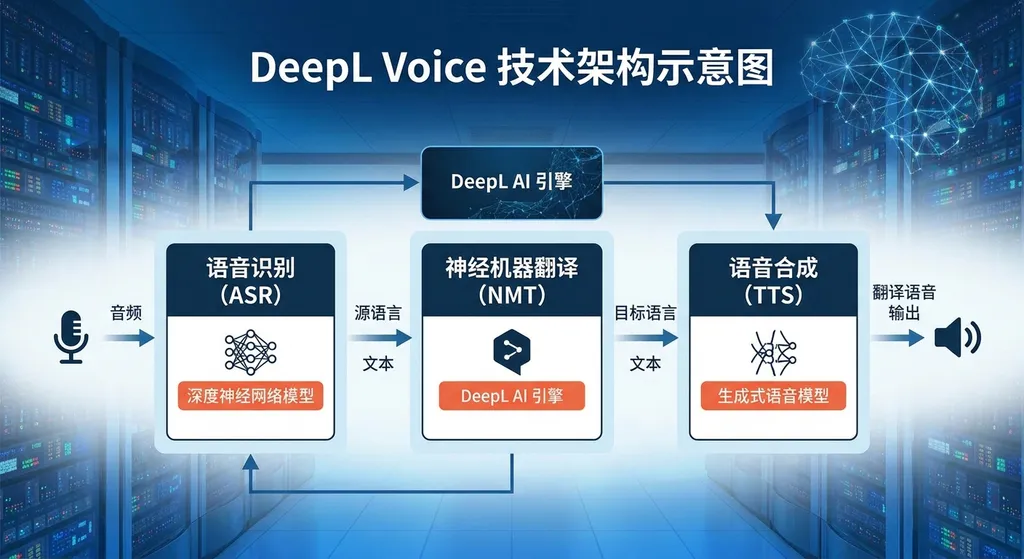
Voice API:开发者工具。这是最值得关注的部分。API 支持实时语音转录,同时输出源语言文本和最多五种目标语言的翻译。这意味着开发者可以把 DeepL 的语音翻译能力集成到自己的应用里。
API 的技术细节
DeepL Voice API 的核心能力是实时语音转录 + 同步翻译。这里的"实时"不是营销话术,而是技术指标:
- 支持流式输入,边说边转录边翻译
- 可以同时输出源语言文本和多个目标语言(最多5种)
- 兼容 WebSocket 和 HTTP 两种接口模式
DeepL 在技术博客里提到,他们没有直接用现成的语音识别引擎,而是自己训练了专有模型。原因是现有架构在处理多语言、口语化表达、专业术语时表现不够稳定。这个选择很 DeepL——宁可多花时间打磨底层模型,也不接受"差不多就行"的方案。
API 调用示例
如果你想在自己的应用里集成 DeepL Voice,调用方式和其他语音 API 类似。虽然 DeepL 有自己的 API 格式,但通过 OpenAI Hub 可以用统一的接口调用:
import openai
# 配置 OpenAI Hub
openai.api_base = \"https://openai-hub.com/v1\"
openai.api_key = \"your-openai-hub-key\"
# 调用 DeepL Voice API(通过 OpenAI Hub 转发)
response = openai.Audio.transcribe(
model=\"deepl-voice\",
file=open(\"audio.mp3\", \"rb\"),
language=\"en\",
target_languages=[\"zh\", \"ja\", \"de\"] # 同时翻译成中文、日文、德文
)
print(response[\"text\"]) # 源语言文本
print(response[\"translations\"]) # 多语言翻译结果
这个例子展示了 Voice API 的核心优势:一次请求,同时拿到转录和多语翻译。对于需要支持多语言的应用(比如客服系统、在线教育平台),这比分别调用转录和翻译 API 要高效得多。
语音翻译的难点在哪
语音翻译看起来是"语音识别 + 机器翻译"的组合,但实际复杂得多。DeepL 在技术博客里提到了几个关键挑战:
口语化表达的处理:书面语和口语的差异远比想象中大。"那个...怎么说呢...就是那种感觉"这种句子,文本翻译模型根本不知道怎么办。DeepL 的方案是在训练数据里大量加入口语对话,让模型学会处理不完整、重复、带语气词的句子。
实时性和准确性的平衡:实时翻译意味着不能等说话人把整句话说完再翻译,必须边听边译。但太早翻译容易出错(比如"我不是...我是..."这种转折),太晚翻译又会有明显延迟。DeepL 的做法是用上下文预测模型,在保证准确性的前提下尽可能提前输出翻译。
专业术语和领域知识:这是 DeepL 的传统强项。他们的文本翻译 API 支持自定义术语表,Voice API 也继承了这个能力。对于医疗、法律、金融这类专业领域,术语翻译的准确性直接决定了产品能不能用。
和竞品比,DeepL 的优势在哪
语音翻译市场已经很拥挤了。Google Translate 有语音对话功能,Microsoft Teams 有实时字幕翻译,Zoom 也在会议里集成了翻译。DeepL 作为后来者,凭什么能拿到 96% 的盲测胜率?
翻译质量:这是 DeepL 的基本盘。它的文本翻译在欧洲语言之间的表现一直被认为优于 Google 和 Microsoft,尤其是在处理复杂句式和专业术语时。这个优势延续到了语音翻译上。
低延迟:DeepL 强调的是"实时"而不是"准实时"。在实际测试中,Voice for Meetings 的翻译延迟控制在 1-2 秒,这对于会议场景来说基本可以接受。相比之下,一些竞品的延迟会达到 3-5 秒,这会明显打断对话节奏。
隐私和安全:DeepL 的服务器在欧洲,符合 GDPR 标准。对于企业客户来说,这是个重要考量——跨国会议的内容往往涉及商业机密,数据存储位置和处理方式直接关系到合规风险。
但 DeepL 也有明显短板:语言覆盖范围。Google Translate 支持 100+ 种语言,DeepL 目前只支持 30+ 种。如果你需要翻译小语种,DeepL 暂时帮不上忙。
这对开发者意味着什么
Voice API 的推出,最直接的影响是给了开发者一个新选择。之前如果要做语音翻译功能,要么用 Google Cloud Speech-to-Text + Translation API 的组合,要么用 Azure 的 Cognitive Services。现在多了 DeepL 这个选项。
成本方面:DeepL 的定价还没公布,但参考它的文本翻译 API(每百万字符 20 美元),预计会比 Google 和 Azure 略贵。但如果你的应用对翻译质量要求高,多花点钱是值得的。
集成难度:DeepL Voice API 提供了 WebSocket 和 HTTP 两种接口,文档也比较完善。如果你之前用过其他语音 API,迁移成本不高。通过 OpenAI Hub 这类聚合平台,可以用统一的接口调用 DeepL、Google、Azure 等多家服务,方便做 A/B 测试和成本优化。
应用场景:最适合 DeepL Voice 的场景是对翻译质量要求高、但语言种类不多的应用。比如:
- 跨国企业的内部会议系统(主要是英语、中文、日语、德语等主流语言)
- 医疗远程咨询平台(术语翻译准确性要求极高)
- 高端客服系统(翻译错误会直接影响客户体验)
如果你的应用需要支持几十种语言,或者对成本非常敏感,Google 和 Azure 可能是更好的选择。
语音翻译的下一步
DeepL CEO Jarek Kutylowski 说"我们已成功攻克了其中最难的一道",这话说得有点满。语音翻译还有很多问题没解决:
情感和语气的传递:现在的语音翻译只能传递语义,但说话人的情绪、语气、停顿这些信息都丢失了。未来如果能做到"生气的语气翻译成生气的语气,开玩笑的语气翻译成开玩笑的语气",体验会好很多。
多人对话的处理:现在的语音翻译基本都是一对一或者单向广播(比如会议里的演讲者)。如果是多人同时说话、互相打断的场景,现有技术还处理不好。
方言和口音:DeepL Voice 目前主要针对标准发音,对于重口音、方言的识别准确率还不够高。这在全球化场景下是个大问题——印度英语、新加坡英语、澳大利亚英语的发音差异很大,但都是"英语"。
DeepL 这次推出 Voice API,更像是在语音翻译这个赛道上立了个标杆:翻译质量可以做到这个水平,延迟可以控制到这个范围。接下来就看 Google、Microsoft 怎么接招了。
对于开发者来说,现在是个好时机。语音翻译的基础设施已经成熟,API 调用也很方便,可以开始考虑在产品里加入多语言语音支持了。尤其是 B2B SaaS 产品,如果能让不同国家的团队无障碍协作,这本身就是个很强的卖点。

参考来源
- DeepL 推出实时语音翻译功能,支持语言对语音通话 - IT之家
IT之家对 DeepL Voice 产品发布的报道,包含产品功能和盲测数据
