系统级抓包+AI,API逆向从此自动化

Anything Analyzer v3.0.0 发布,新增系统级网络监听能力,可自动捕获任意应用的 API 请求并生成结构化协议文档,直接喂给 AI 编码工具生成对接代码,大幅降低 API 逆向工程门槛。
不用再手动抓包了,Anything Analyzer 把 API 逆向这件事自动化了
搞过 API 对接的开发者都知道,最痛苦的环节往往不是写代码,而是搞清楚接口到底长什么样。文档缺失、字段含义不明、鉴权逻辑靠猜——这些事吃掉的时间,可能比真正写业务逻辑还多。
4 月中旬,开源工具 Anything Analyzer 推送了 v3.0.0 大版本更新。这次的核心变化只有一个,但足够重磅:支持系统级别的网络监听。
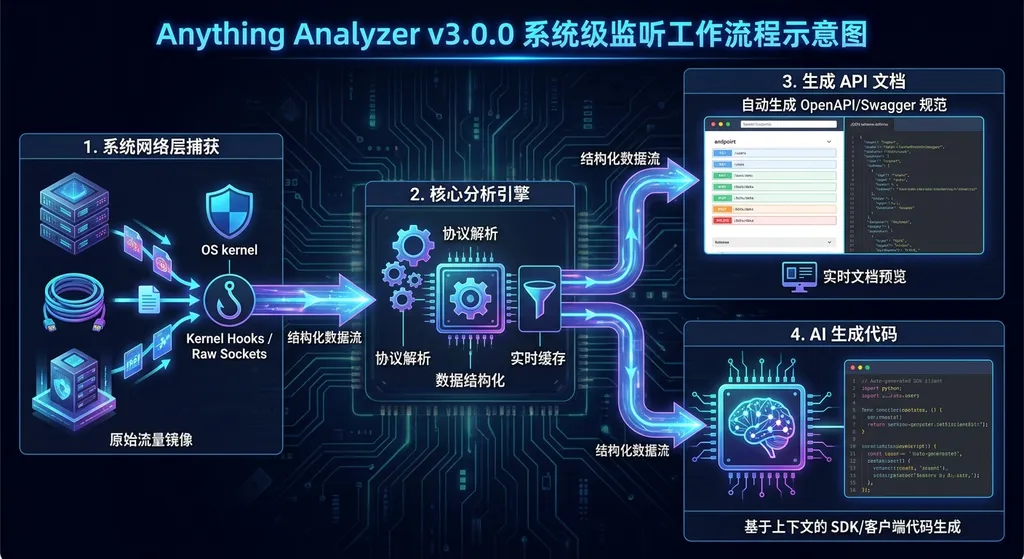
简单说,以前你需要手动配代理、挂 Charles 或 mitmproxy,把流量导过去才能分析。现在 Anything Analyzer 可以直接在操作系统层面拦截网络请求,不管是浏览器、桌面客户端还是后台服务发出的 HTTP/HTTPS 流量,它都能捕获,然后自动整理成结构化的 API 协议文档。
这份文档的设计目标很明确——直接喂给 AI 写代码。
它到底解决了什么问题
先说背景。
在 AI 编程工具(Cursor、Copilot、Windsurf 等)已经能帮你写大部分胶水代码的今天,瓶颈反而前移了:你得先告诉 AI,目标 API 的请求格式、参数结构、鉴权方式是什么。没有这些信息,再强的模型也只能给你编一个看起来像那么回事但跑不通的调用。
传统做法是这样的:
- 打开 Charles / Fiddler / mitmproxy,配好代理和证书
- 操作目标应用,触发你关心的接口
- 在抓包工具里翻找、筛选、复制请求和响应
- 手动整理成文档或 Prompt,喂给 AI
- AI 生成代码,你调试,发现遗漏字段,回到第 2 步
这个循环每次做都烦,尤其是面对复杂应用时,几十上百个请求混在一起,光筛选就够喝一壶的。
Anything Analyzer 想做的事情是把第 1 到第 4 步压缩成一步:你只管操作应用,它在后台自动抓、自动分析、自动生成文档。
v3.0.0 的系统级监听,技术上怎么实现的
在 v3.0.0 之前,Anything Analyzer 的工作方式更像一个增强版的抓包工具——需要你手动指定监听目标或配置代理。这在很多场景下够用,但碰到以下情况就会卡壳:
- 应用内置了证书固定(Certificate Pinning),代理方案直接失效
- 某些桌面客户端不走系统代理
- 你不确定目标功能到底会调哪些接口,需要全量捕获再筛选
v3.0.0 引入的系统级监听,本质上是在更底层的网络栈上做拦截。具体来说,它不再依赖应用层的代理配置,而是通过操作系统提供的网络接口(类似 Wireshark 的工作层级,但专注于 HTTP/HTTPS 协议解析)来捕获流量。
这意味着几件事:
- 覆盖面更广:只要是从本机发出的 HTTP 请求,理论上都能捕获,不管发起者是谁
- 配置更少:不需要手动设代理、导证书,启动就能用
- 对目标应用无侵入:应用本身感知不到被监听,减少了行为差异
当然,HTTPS 的解密仍然需要处理证书信任的问题,这一点没有银弹。但相比之前需要逐个应用配置的方式,v3.0.0 把这个过程做了很大程度的自动化。
生成的文档长什么样
这是开发者最关心的部分。
Anything Analyzer 生成的不是简单的请求日志,而是经过结构化处理的 API 协议文档。根据社区用户的反馈,输出内容通常包括:
- 接口 URL 和请求方法
- 请求头(包括鉴权相关的 Token、Cookie 等)
- 请求体的字段结构和类型推断
- 响应体的字段结构
- 接口之间的调用顺序和依赖关系(比如先登录拿 Token,再用 Token 调业务接口)
关键在于,这份文档的格式是为 AI 消费优化的。你可以直接把它粘贴到 Cursor、Copilot Chat 或者任何支持长上下文的 AI 编程工具里,让模型基于真实的协议细节来生成对接代码。
举个实际场景:你想对接某个内部管理系统的数据导出功能,但这个系统没有公开 API 文档。以前你可能需要花半天时间抓包、整理、试错。现在的流程变成了:
- 启动 Anything Analyzer 的系统级监听
- 在管理系统里正常操作一遍数据导出
- 停止监听,拿到自动生成的协议文档
- 把文档喂给 AI,让它生成 Python/Node.js 的调用代码
整个过程可能 10 分钟就搞定了。
跟现有工具比,它的位置在哪
先说清楚,Anything Analyzer 不是要替代 Charles 或 mitmproxy。这些工具在网络调试、性能分析等场景下依然不可替代。
Anything Analyzer 瞄准的是一个更具体的需求:从抓包结果到可用文档的自动化转换。
| 维度 | Charles / Fiddler | mitmproxy | Anything Analyzer v3.0.0 | |------|------------------|-----------|-------------------------| | 抓包能力 | 成熟稳定 | 可编程,灵活 | 系统级,配置少 | | 文档生成 | 无,需手动整理 | 可通过脚本实现 | 自动生成结构化文档 | | AI 工具对接 | 无 | 需自行开发 | 原生支持,输出格式为 AI 优化 | | 上手门槛 | 中等 | 较高(需写脚本) | 低(号称傻瓜式) | | 适用场景 | 通用网络调试 | 自动化测试、安全分析 | API 逆向 + AI 编码 |
可以看出,Anything Analyzer 的差异化在于把抓包和 AI 编码这两个环节串起来了。它不是最强的抓包工具,但它可能是目前把「抓包→文档→AI 生成代码」这条链路做得最顺滑的。
对接 AI 编码工具的实际用法
项目文档提到,生成的协议分析文档可以直接对接 Cursor(CC)等 AI 编程工具。实际操作中,工作流大概是这样的:
- Anything Analyzer 生成 API 文档(Markdown 或 JSON 格式)
- 在 Cursor 中打开文档,或者将内容粘贴到对话窗口
- 用自然语言描述你要实现的功能,比如「基于这份 API 文档,用 Python requests 实现自动登录并导出用户列表」
- AI 根据文档中的真实接口信息生成代码
因为文档里包含了真实的请求头、参数结构和鉴权方式,AI 生成的代码质量会比你口头描述接口要高得多。少了那个「AI 瞎猜参数名」的环节,调试时间能省不少。
如果你的工作流中涉及调用大模型 API 来做进一步的自动化处理(比如让模型批量分析多个接口文档、生成测试用例等),可以通过 OpenAI Hub 这类 API 聚合平台来统一调用不同模型。下面是一个示例,把 Anything Analyzer 生成的文档喂给大模型,让它自动生成对接代码:
import openai
client = openai.OpenAI(
api_key="你的 OpenAI Hub API Key",
base_url="https://api.openai-hub.com/v1"
)
# 假设 api_doc 是 Anything Analyzer 生成的协议文档内容
api_doc = open("captured_api_doc.md", "r").read()
response = client.chat.completions.create(
model="gpt-4o", # 也可以换成 claude-sonnet、gemini-pro、deepseek-chat 等
messages=[
{
"role": "system",
"content": "你是一个资深后端开发者,擅长根据 API 协议文档生成 Python 对接代码。生成的代码需要包含完整的错误处理和鉴权逻辑。"
},
{
"role": "user",
"content": f"以下是通过抓包工具自动生成的 API 协议文档:\n\n{api_doc}\n\n请基于这份文档,用 Python requests 库生成完整的 API 对接代码,包括登录鉴权和核心业务接口的调用。"
}
],
temperature=0.3 # 生成代码时低温度更稳定
)
print(response.choices[0].message.content)
这个思路的好处是,你可以根据不同接口的复杂度选择不同的模型——简单的 CRUD 接口用 DeepSeek 就够了,复杂的鉴权流程可以上 Claude 或 GPT-4o,一个 Key 切换模型就行。
社区反馈和当前状态
从 linux.do 社区的讨论来看,v3.0.0 发布后社区活跃度明显上升,帖子已经到了第 14 页。用户反馈集中在几个方面:
正面的:
- 系统级监听确实省事,不用再折腾代理配置
- 生成的文档质量比手动整理的好,尤其是接口依赖关系的梳理
- 对接 AI 编码工具的体验比较顺滑
需要注意的:
- 有用户反馈遇到 502 错误,不过从讨论来看这更像是服务端的临时问题,而非工具本身的 Bug(502 是服务器内部错误,跟客户端工具关系不大)
- 系统级监听在不同操作系统上的表现可能有差异,Windows 上的兼容性目前反馈最多
- HTTPS 解密仍然是个需要用户理解的环节,不是完全的「零配置」
总体来说,这是一个处于快速迭代期的开源项目。v3.0.0 的系统级监听是一个方向性的升级,但在稳定性和跨平台一致性上还有打磨空间。
这件事为什么值得关注
往大了说,Anything Analyzer 代表的是一个趋势:AI 编程工具的上下文获取正在被自动化。
过去一年,AI 编码能力的提升有目共睹——从补全到生成,从单文件到跨项目。但一个被忽视的瓶颈是:模型的输出质量高度依赖输入的上下文质量。你给它一份精确的 API 文档,它能写出能跑的代码;你给它一段模糊的描述,它只能给你一个大概的框架。
所以,谁能更高效地把真实世界的技术信息转化成 AI 可消费的结构化上下文,谁就能在 AI 编程这条链路上占据关键位置。
Anything Analyzer 做的就是这件事的一个切面:把网络协议这种非结构化的、散落在抓包日志里的信息,自动转化成 AI 能直接理解和使用的文档。
类似的思路其实在其他领域也在发生。比如 Harness 的 AI 编排工具通过文件系统、沙箱、记忆(AGENTS.md)等组件来为 AI 提供结构化上下文;再比如各种 RAG 方案试图把文档库变成模型可检索的知识源。
不同的切入点,同一个方向:让 AI 拿到更好的上下文,从而产出更好的结果。
写在最后
如果你的日常工作涉及 API 对接、协议分析、或者需要逆向工程某些没有文档的接口,Anything Analyzer v3.0.0 值得试一试。系统级监听这个能力,确实把工具的适用范围往前推了一大步。
但也别期望太高。它目前还是一个社区驱动的开源项目,不是商业级产品。遇到兼容性问题、边界情况处理不完善,都是正常的。好在开源意味着你可以参与改进,社区的迭代速度看起来也不慢。
对于开发者来说,更值得思考的可能是这个工具背后的工作流变化:当「抓包→文档→AI 生成代码」这条链路足够顺滑时,很多以前需要人工逆向的工作,可能真的会变成一键完成的事情。
这个变化,比工具本身更有意思。
参考来源
- Anything Analyzer v3.0.0 发布讨论帖 - linux.do:社区原始发布帖,包含版本更新说明和用户讨论反馈
