Claude Opus 4.7 全面上线,Anthropic 又卷了一把

Anthropic 发布旗舰模型 Claude Opus 4.7,编程自主性、图像识别和逻辑推理能力显著提升,同步更新 Claude Code 桌面端和 Routines 自动化功能,加速从模型工具向任务执行平台转型。
Anthropic 没打算让同行喘口气。
4 月 15 日深夜,Claude Opus 4.7 悄然上线。各家 API 聚合平台几乎在同一时间跟进,凌晨零点左右开发者社区就已经炸开了锅。有人连夜跑了 70 美元的 Token 做实测,结论是「比 4.6 强 20% 左右,真正意义上的无敌」。当然,也有人被 429 和 503 错误反复折磨,retry 了九十轮才勉强用上。
这就是 Anthropic 的节奏——发货快,产能跟不上,但模型本身确实在往前走。
核心升级:不是刷分,是补短板
Opus 4.7 这次的提升方向很明确,不是在某个 benchmark 上再涨两个点,而是在开发者日常最痛的几个地方集中发力。
第一个是逻辑推理和 Bug 检测。社区实测反馈最集中的一点:Opus 4.7 在排查复杂 Bug 时的能力「比 4.6 强不止一点」。这不是玄学,而是模型在长链路任务中的自我验证能力有了实质性进步。过去用 4.6 跑一个复杂重构任务,中间走偏了往往要到最后才暴露;4.7 会在过程中更主动地回头检查,相当于自带了一个初级 Code Reviewer。
第二个是图像识别。Opus 4.7 支持最高 2576 像素长边的图像处理,分辨率是前代的三倍以上。这意味着它可以直接看懂复杂的工程图纸、密集的 UI 截图、甚至手写的架构草图。对于那些习惯截个图丢给 AI 说「帮我看看这个报错」的开发者来说,体验会有质的变化。
第三个是指令理解和长任务稳定性。说白了就是:你给它一个复杂的多步骤指令,它不容易跑偏了,也不容易在第 15 步的时候突然忘了第 3 步说的是什么。
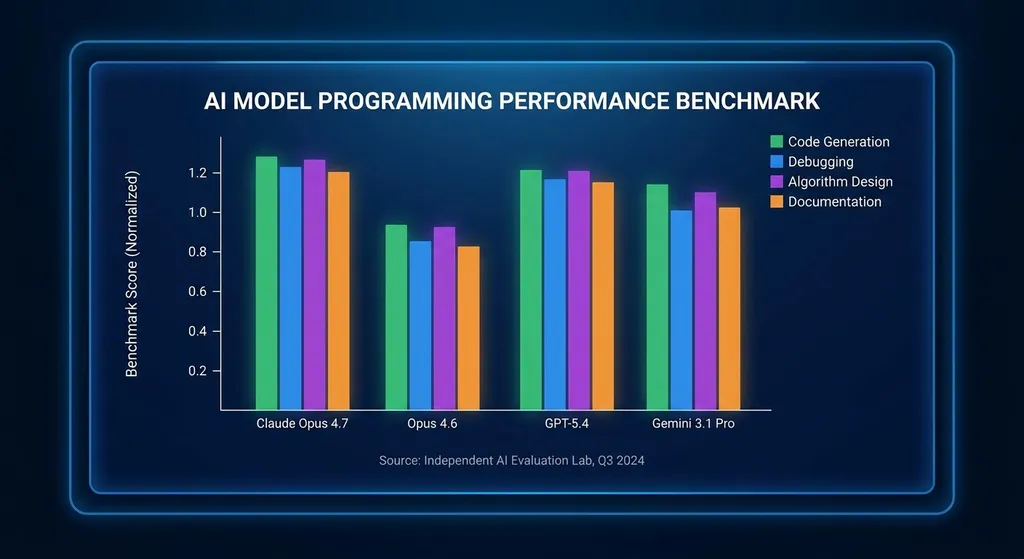
按照 Anthropic 官方的说法,Opus 4.7 在多个测试中已经超过了 Opus 4.6、GPT-5.4 和 Gemini 3.1 Pro,但仍然低于还在预览阶段的 Mythos Preview。这个结果说明两件事:公开可用模型的天花板又被抬高了;Anthropic 手里还有没放出来的东西。
新 Tokenizer:更聪明,但也更贵
Opus 4.7 换了新的 tokenizer。这个变化容易被忽略,但对实际使用成本影响不小。
新 tokenizer 的好处是对信息的切分更合理,模型理解更完整,尤其在高算力模式下「思考」会更充分。但代价是:同样的输入内容,切出来的 token 数量可能跟以前不一样。
社区里已经有人算过账了——「用了大概 70 刀,感觉确实比 4.6 好,就是贵了」。如果你的工作流对 token 用量比较敏感,这轮切换建议盯一下实际消耗。模型更仔细是好事,但预算和吞吐需要重新平衡。
对于通过 API 调用的开发者来说,这一点尤其重要。同样的 prompt,跑 4.7 的成本可能比 4.6 高出一截。好消息是,如果你用的是 OpenAI Hub 这类聚合平台,切换模型只需要改一个参数,可以很方便地在 4.6 和 4.7 之间做 A/B 测试,找到性能和成本的平衡点。
实际调用:一个参数的事
Opus 4.7 已经在各主要平台上线。如果你通过 OpenAI Hub 调用,接口完全兼容 OpenAI 格式,切换模型只需要把 model 参数改一下:
import openai
client = openai.OpenAI(
api_key="你的 OpenAI Hub API Key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7-20260415",
messages=[
{"role": "system", "content": "你是一个资深软件工程师。"},
{"role": "user", "content": "请审查以下代码中的潜在 Bug 并给出修复建议。"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
如果你想测试它的图像识别能力,传入图片也很直接:
response = client.chat.completions.create(
model="claude-opus-4-7-20260415",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张截图里的报错信息是什么意思?怎么修?"},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{你的图片base64编码}"
}
}
]
}
],
max_tokens=4096
)
国内直连,不用折腾网络环境,一个 Key 就能调 Claude、GPT、Gemini、DeepSeek 等主流模型。对于想第一时间试用 Opus 4.7 又不想折腾海外支付和网络的开发者来说,这可能是最省事的方式。
Claude Code 同步大改:从工具到工作台
模型升级只是这次更新的一半。另一半同样重要——Claude Code 桌面端几乎被重写了。
Anthropic 这次给 Claude Code 加了三个关键能力:
Routines:让 Claude 在后台替你干活
Routines 是一套自动化流程系统,支持三种触发方式:
- 定时触发:按小时、每天、工作日、每周,或者用 cron 自定义
- GitHub 触发:PR、push、issue、workflow run 等事件发生时自动执行
- API 触发:外部系统调用触发
一个典型场景:每天晚上自动跑一次日志整理,给新 issue 贴标签、分配负责人,早上团队上班时收到一份整理好的摘要。这些事人工也能做,但做起来枯燥又容易忘。
更关键的是,Routines 跑在 Anthropic 的云基础设施上,不依赖你的电脑在线。笔记本合上,任务照跑。
目前 Pro 用户每天最多 5 次,Max 用户 15 次,Team 和 Enterprise 用户 25 次。
桌面端多会话并行
新版 Claude Code 支持一个窗口内同时跑多个会话,通过侧边栏管理,拖拽分屏。不再需要开一堆终端窗口来维持多个任务线。
同时内置了终端、文件编辑器、HTML/PDF 预览、更快的 diff 查看器。以前需要在 Claude Code、编辑器、浏览器之间反复切换的操作,现在一个窗口搞定。
/ultrareview 命令
新增的 /ultrareview 不是简单扫一眼 diff,而是尽可能模拟一位认真的 Reviewer 会做的事——找逻辑漏洞、检查边界条件、发现潜在的性能问题。配合 Opus 4.7 更强的推理能力,这个功能的实用价值会比在 4.6 上高不少。
Claude Code 桌面端负责人 Anthony Morris 说他自己已经连续好几周没用过传统 IDE 了。这话当然有营销成分,但方向是真实的:Anthropic 正在把 Claude Code 从一个「终端里会聊天的 AI」推向一个完整的任务执行平台。
身份验证争议:Anthropic 要查证件了
伴随 Opus 4.7 发布的还有一个不太让人愉快的消息:Anthropic 开始为部分使用场景引入身份验证。
官方说法是在触及某些能力、平台例行完整性检查、安全与合规要求时,用户会被要求验证身份。但社区里不少人猜测这是针对特定地区用户的「实名制」。目前已经有用户发现,在尝试订阅 Max 会员时会被触发验证。
这对国内开发者来说是个现实问题。直接用官方服务的门槛又高了一层——海外信用卡、网络环境、现在还加上身份验证。相比之下,通过 API 聚合平台调用反而成了更稳定的选择。
成本压力:Anthropic 自己也在算账
能力越强,成本越高,这个矛盾 Anthropic 自己也没解决。
最近 Anthropic 调整了企业版定价,从按席位收费改为「每月每用户 20 美元 + 按实际用量计费」。对重度使用 Claude Code 的团队来说,成本可能翻 2-3 倍。
Uber CTO 透露,2026 年才过去几个月,Uber 就已经用完了全年的 AI 预算,主要原因就是 Claude Code 使用量飙升。Anthropic 自己也下调了毛利率预期——模型推理支出的增长速度明显快于收入增长。
这解释了为什么 Opus 4.7 的 token 单价更高,也解释了为什么 Routines 要设每日次数上限。Anthropic 在能力和成本之间走钢丝,而这个平衡点还在不断移动。
竞争格局:三家混战,开发者受益
把 Opus 4.7 放到整个市场里看,现在的局面是 Anthropic、OpenAI、Google 三家在高端模型上贴身肉搏。
Opus 4.7 超过了 GPT-5.4 和 Gemini 3.1 Pro,但优势不是碾压级的。真正拉开差距的是 Anthropic 在开发者工具链上的投入——Claude Code 的 Routines、桌面端改版、/ultrareview,这些东西加在一起构成了一个比单纯模型能力更有粘性的生态。
OpenAI 有 Codex 和 GPT 系列的庞大用户基础,Google 有 Gemini 和云服务的整合优势,Anthropic 选择的差异化路径是:把模型能力和开发工作流深度绑定,让 Claude 不只是一个你问它答的工具,而是一个能在后台持续替你干活的系统。
这个方向对不对,市场会给答案。但至少目前来看,开发者是最大的受益者——三家卷起来,模型越来越强,价格战迟早会来。
该不该现在切换到 Opus 4.7?
说点实在的建议:
如果你的主要场景是复杂代码重构、大型项目的 Bug 排查、需要模型看截图理解上下文,Opus 4.7 的提升是实打实的,值得切换。
如果你的场景主要是简单的代码补全、文档生成、日常问答,4.6 甚至 Sonnet 就够用了,没必要为了 20% 的提升多花那么多钱。
如果你对成本敏感,建议先小规模测试,对比一下同样任务在 4.6 和 4.7 上的 token 消耗和输出质量,再决定是否全面切换。
Anthropic 提到后续 Opus 系列可能按每两个月一次的节奏更新。这意味着 4.7 不会是终点,但它是目前公开可用的最强选项之一。
参考来源:
- Linux.do - opus4.7 实测讨论 — 社区开发者对 Opus 4.7 的实际使用体验和性能对比反馈
- Linux.do - 各平台上线 Opus 4.7 讨论 — API 聚合平台上线时间和稳定性讨论
- Linux.do - 公益渠道上线 claude-opus-4-7 — 社区公益 API 渠道的上线情况
