Cloudflare 推出 Agent Memory:让 AI 智能体拥有持久记忆

Cloudflare 发布 Agent Memory 托管服务,为 AI 智能体提供持久化记忆能力,支持批量提取和直接工具调用,让智能体能够记住重要信息、遗忘无用数据,并随时间推移变得更智能。
Cloudflare 推出 Agent Memory:让 AI 智能体拥有持久记忆
Cloudflare 昨天(4月17日)发布了 Agent Memory 托管服务,这是一个专为 AI 智能体设计的持久化记忆系统。简单说,就是让你的 AI Agent 能像人一样记住过去的对话和操作,而不是每次对话都从零开始。
这个功能看起来不起眼,但解决的是 AI 智能体落地的核心痛点之一:状态管理。目前市面上大部分 Agent 框架都是无状态的,每次调用都需要重新加载上下文,既浪费 token 又影响响应速度。Cloudflare 这次直接把记忆层做成了基础设施,开发者不用自己折腾数据库和检索逻辑了。
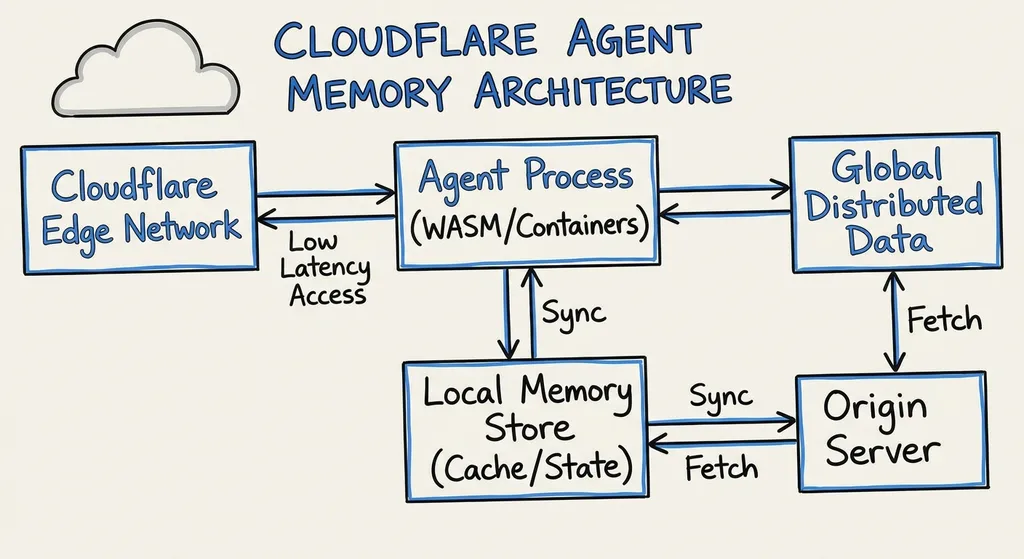
为什么 Agent 需要记忆
传统的 LLM 应用是无状态的,每次请求都是独立的。但 Agent 不一样,它需要在多轮交互中保持上下文,甚至跨会话记住用户的偏好和历史操作。
举个例子,你让一个客服 Agent 帮你查订单,它查完之后你又问「能帮我退货吗」,这时候 Agent 需要知道你刚才查的是哪个订单。如果没有记忆,它就得重新问你订单号,体验很差。
更复杂的场景是多步骤任务。比如一个代码审查 Agent,它需要记住之前审查过哪些文件、发现了哪些问题、用户采纳了哪些建议。这些信息如果每次都塞进 prompt,token 消耗会爆炸,而且 context window 也有限制。
Agent Memory 要解决的就是这个问题:把重要信息持久化存储,需要的时候再检索出来,而不是每次都把所有历史记录塞进 prompt。
Agent Memory 的核心能力
Cloudflare 的 Agent Memory 提供了三个核心能力:
1. 持久化存储
记忆数据存储在 Cloudflare 的全球网络中,支持跨会话访问。开发者可以为每个用户或每个会话创建独立的记忆空间,数据隔离做得很彻底。
存储的数据结构很灵活,支持键值对、向量嵌入、时间戳等元数据。这意味着你既可以存储结构化的用户偏好(比如「用户喜欢用 TypeScript」),也可以存储非结构化的对话历史(比如「上次讨论了数据库优化方案」)。
2. 智能检索
Agent Memory 内置了语义检索能力,基于向量相似度匹配相关记忆。这比简单的关键词搜索要强得多,能理解用户意图的语义层面。
比如用户问「上次那个性能问题解决了吗」,Agent Memory 可以检索出之前关于「数据库查询慢」「索引优化」等相关记忆,即使用户没有用完全相同的词汇。
检索支持批量操作,可以一次性拉取多条相关记忆,减少 API 调用次数。这对降低延迟很重要,毕竟 Agent 的响应速度直接影响用户体验。
3. 自动遗忘
这是 Agent Memory 最有意思的地方。它不是简单地把所有数据都存下来,而是会根据重要性和时效性自动清理过期记忆。
开发者可以设置记忆的 TTL(Time To Live),也可以手动标记某些记忆为「重要」或「临时」。Agent Memory 会根据这些标记和访问频率,自动决定哪些记忆该保留、哪些该淡化。
这个设计很符合人类记忆的工作方式:重要的事情会反复强化,不重要的事情会逐渐遗忘。对 Agent 来说,这能避免记忆空间被无用信息占满,也能降低检索时的噪音。
技术实现细节
Agent Memory 基于 Cloudflare Workers 和 Durable Objects 构建,这意味着它天然具备全球分布式、低延迟、高可用的特性。
数据存储在 Cloudflare 的边缘节点上,检索请求会路由到离用户最近的节点,延迟通常在 50ms 以内。这对实时交互的 Agent 应用很关键,用户不会感觉到明显的等待。
向量检索用的是 Cloudflare Vectorize,支持多种嵌入模型(OpenAI、Cohere、自定义模型都可以)。开发者可以选择用哪个模型生成嵌入,也可以自己管理嵌入的生成和更新。
数据隔离做得很细致。每个 Agent 实例可以有独立的记忆空间,不同用户的记忆完全隔离,不会互相干扰。这对多租户应用很重要,尤其是涉及敏感数据的场景。
API 调用示例
Agent Memory 提供了 RESTful API,兼容 OpenAI 的调用风格。如果你用的是 OpenAI Hub,可以直接切换 base URL 来调用 Cloudflare 的服务。
存储记忆
import requests
# 使用 OpenAI Hub 调用 Cloudflare Agent Memory
base_url = "https://api.openai-hub.com/v1/cloudflare/agent-memory"
api_key = "your-openai-hub-api-key"
# 存储一条记忆
response = requests.post(
f"{base_url}/memories",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json={
"user_id": "user_123",
"session_id": "session_456",
"content": "用户偏好使用 TypeScript 和 React 进行前端开发",
"metadata": {
"category": "preference",
"importance": "high",
"timestamp": "2026-04-18T10:30:00Z"
},
"ttl": 2592000 # 30 天后过期
}
)
print(response.json())
检索记忆
# 语义检索相关记忆
response = requests.post(
f"{base_url}/memories/search",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json={
"user_id": "user_123",
"query": "用户喜欢用什么技术栈",
"top_k": 5, # 返回最相关的 5 条记忆
"filter": {
"category": "preference" # 只检索偏好类记忆
}
}
)
memories = response.json()["memories"]
for memory in memories:
print(f"相关度: {memory['score']:.2f}")
print(f"内容: {memory['content']}")
print(f"时间: {memory['metadata']['timestamp']}")
print("---")
批量操作
# 批量存储多条记忆
response = requests.post(
f"{base_url}/memories/batch",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json={
"user_id": "user_123",
"memories": [
{
"content": "用户在项目中遇到了数据库查询性能问题",
"metadata": {"category": "issue", "importance": "high"}
},
{
"content": "建议添加索引优化查询",
"metadata": {"category": "solution", "importance": "medium"}
},
{
"content": "用户采纳了索引优化方案",
"metadata": {"category": "action", "importance": "high"}
}
]
}
)
print(f"成功存储 {response.json()['count']} 条记忆")
更新和删除
# 更新记忆的重要性
response = requests.patch(
f"{base_url}/memories/mem_789",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json={
"metadata": {
"importance": "critical" # 提升重要性
}
}
)
# 删除过期记忆
response = requests.delete(
f"{base_url}/memories/mem_789",
headers={"Authorization": f"Bearer {api_key}"}
)
适用场景
Agent Memory 适合哪些场景?从 Cloudflare 的文档和社区反馈来看,主要有这几类:
客服和支持 Agent
这是最直接的应用。客服 Agent 需要记住用户的历史问题、解决方案、满意度反馈等信息。有了 Agent Memory,用户不用每次都重复说明背景,Agent 可以主动关联之前的对话,提供更个性化的服务。
比如用户上次反馈过「登录总是超时」,这次又来咨询,Agent 可以主动问「上次的登录问题解决了吗」,而不是机械地问「请问有什么可以帮您」。
代码助手和开发工具
代码审查、重构建议、Bug 修复这些任务都需要上下文。Agent Memory 可以记住项目的技术栈、代码风格、历史问题,给出更精准的建议。
比如一个代码审查 Agent,它可以记住「这个项目用 ESLint 的 Airbnb 规范」「团队不喜欢用 any 类型」「上次建议过把这个函数拆分」,下次审查时就能保持一致性。
个性化推荐和内容生成
内容创作 Agent 可以记住用户的写作风格、偏好话题、目标受众,生成更符合预期的内容。
比如一个营销文案 Agent,它可以记住「用户喜欢简洁直接的风格」「目标受众是技术开发者」「避免使用夸张的形容词」,每次生成文案时都能保持这些特点。
多步骤任务和工作流
复杂的自动化任务往往需要多个步骤,每个步骤的结果会影响后续决策。Agent Memory 可以记录任务进度、中间结果、异常情况,让 Agent 能够断点续传。
比如一个数据处理 Agent,它需要「下载数据 → 清洗 → 转换 → 上传」。如果中间某个步骤失败了,Agent 可以从记忆中恢复进度,不用从头开始。
与现有方案的对比
市面上已经有一些 Agent 记忆方案,比如 LangChain 的 Memory 模块、LlamaIndex 的 Memory Store、阿里云 Tablestore 的轻量级框架。Cloudflare 的 Agent Memory 有什么优势?
托管服务 vs 自建方案
最大的区别是 Agent Memory 是完全托管的。你不需要自己搭建数据库、管理向量索引、处理数据同步,Cloudflare 全包了。
LangChain 和 LlamaIndex 的方案更灵活,但需要你自己选择存储后端(Redis、PostgreSQL、Pinecone 等),配置嵌入模型,处理数据迁移。对小团队来说,这些基础设施工作的成本不低。
Agent Memory 的定价也很直接:按存储容量和 API 调用次数计费,没有隐藏成本。你不用担心数据库的运维、备份、扩容这些问题。
全球分布 vs 单区域部署
Cloudflare 的全球网络是它的核心优势。Agent Memory 的数据存储在边缘节点上,检索延迟通常在 50ms 以内,比中心化的数据库快得多。
如果你的 Agent 服务面向全球用户,这个优势会很明显。用户在美国、欧洲、亚洲访问时,都能获得接近的响应速度,不会因为地理位置导致体验差异。
阿里云 Tablestore 这类方案虽然也支持多区域部署,但需要你自己配置跨区域同步,复杂度高。
自动遗忘 vs 手动清理
大部分现有方案都需要开发者手动管理记忆的生命周期。你得写代码定期清理过期数据、归档不常用的记忆、压缩历史记录。
Agent Memory 的自动遗忘机制把这些逻辑内置了。你只需要设置 TTL 和重要性标记,系统会自动处理清理和归档。这对长期运行的 Agent 应用很重要,能避免记忆空间无限膨胀。
当然,自动遗忘也意味着你对数据的控制力变弱了。如果你需要精确控制每条记忆的保留策略,可能还是得用自建方案。
潜在问题和限制
Agent Memory 目前还是 Beta 版本,有一些限制需要注意:
数据导出和迁移
Cloudflare 承诺数据可以导出,但具体的导出格式和迁移工具还没公布。如果你担心供应商锁定,可能需要等正式版发布后再评估。
好消息是 Agent Memory 的 API 设计比较标准,理论上可以用其他向量数据库(Pinecone、Weaviate)替换。但实际迁移时,自动遗忘、TTL 这些特性可能需要你自己实现。
嵌入模型的选择
Agent Memory 支持多种嵌入模型,但不同模型的向量维度和语义表达能力差异很大。如果你中途切换嵌入模型,历史记忆的向量需要重新生成,这个过程可能比较耗时。
建议在项目初期就确定好嵌入模型,避免后期迁移的麻烦。如果你用的是 OpenAI 的 text-embedding-3-small 或 text-embedding-3-large,Agent Memory 有优化支持,检索速度会更快。
成本控制
虽然 Agent Memory 的定价看起来合理,但如果你的 Agent 应用有大量用户,存储和检索的成本会快速增长。
比如一个客服 Agent,如果每个用户平均有 100 条记忆,每条记忆 1KB,100 万用户就是 100GB 存储。再加上每天数百万次的检索请求,月度账单可能会超出预期。
建议在设计时就考虑好记忆的粒度和保留策略。不是所有对话都需要存储,也不是所有记忆都需要永久保留。合理设置 TTL 和重要性标记,能显著降低成本。
隐私和合规
Agent Memory 存储的是用户的对话历史和偏好数据,涉及隐私合规问题。Cloudflare 承诺数据加密存储,支持 GDPR 和 CCPA 合规,但具体的数据处理协议还需要仔细审查。
如果你的应用涉及敏感数据(医疗、金融、法律等),可能需要额外的安全措施,比如端到端加密、数据脱敏、访问审计等。这些功能 Agent Memory 目前还不完全支持,可能需要你在应用层实现。
对 Agent 生态的影响
Agent Memory 的发布,标志着 AI 基础设施正在从「模型即服务」向「Agent 即服务」演进。
过去一年,大家都在讨论 Agent 的架构、工具调用、多模态能力,但很少有人关注状态管理这个基础问题。Cloudflare 把记忆层做成标准化的基础设施,降低了 Agent 应用的开发门槛。
这对整个生态是好事。开发者不用再花时间折腾数据库和检索逻辑,可以把精力放在 Agent 的业务逻辑和用户体验上。就像当年 AWS S3 标准化了对象存储,Cloudflare Agent Memory 可能会标准化 Agent 的记忆层。
当然,这也意味着更多的供应商锁定风险。如果 Agent Memory 成为事实标准,开发者可能会越来越依赖 Cloudflare 的生态。好在 Cloudflare 一直以开放和互操作性著称,希望他们能保持这个传统。
从竞争格局来看,AWS、Google Cloud、Azure 应该很快会跟进类似的服务。Agent 记忆是 AI 基础设施的关键一环,云厂商不会放弃这块市场。接下来可能会看到一波「记忆即服务」的竞争,对开发者来说是好事。
实际使用建议
如果你打算用 Agent Memory,这里有几个建议:
1. 设计好记忆的粒度
不要把所有对话都存成一条记忆。合理的做法是提取关键信息,比如用户偏好、任务进度、重要决策等,存成独立的记忆条目。
比如一段对话:
用户:我想用 React 和 TypeScript 搭建一个电商网站
Agent:好的,我建议用 Next.js 框架,它对 SEO 友好
用户:听起来不错,那数据库用什么?
Agent:可以考虑 PostgreSQL,配合 Prisma ORM
用户:行,就这么定了
应该提取成这样的记忆:
- 「用户偏好:React + TypeScript」
- 「项目类型:电商网站」
- 「技术选型:Next.js + PostgreSQL + Prisma」
而不是把整段对话存下来。这样检索时更精准,存储成本也更低。
2. 合理设置 TTL
不同类型的记忆应该有不同的保留期限:
- 用户偏好:长期保留(90 天或更久)
- 任务进度:中期保留(30 天)
- 临时上下文:短期保留(7 天)
- 会话状态:极短期(1 天)
定期审查记忆的访问频率,把不常用的记忆降低重要性或提前清理。
3. 结合向量检索和结构化查询
语义检索很强大,但不是万能的。有些场景下,结构化查询更高效。
比如查询「用户最近一次登录时间」,用 metadata 过滤比语义检索快得多。而查询「用户之前遇到过类似的问题吗」,语义检索更合适。
建议在存储记忆时,同时设置好 metadata 字段(category、timestamp、importance 等),方便后续的混合查询。
4. 监控和优化
Agent Memory 提供了使用统计和性能指标,定期查看这些数据,优化记忆的存储和检索策略。
关注这几个指标:
- 平均检索延迟:如果超过 100ms,考虑优化查询条件或减少 top_k
- 记忆命中率:如果低于 50%,说明记忆的粒度或检索策略有问题
- 存储增长速度:如果每月增长超过 20%,需要调整 TTL 或清理策略
总结
Agent Memory 是 Cloudflare 在 AI 基础设施上的又一次布局。它解决的是 Agent 应用的核心痛点:状态管理和上下文保持。
从技术实现来看,Agent Memory 做得很扎实:全球分布式存储、语义检索、自动遗忘、数据隔离,该有的功能都有了。API 设计也很友好,兼容 OpenAI 的调用风格,上手成本低。
当然,作为 Beta 版本,还有一些限制和不确定性。数据导出、成本控制、隐私合规这些问题需要在实际使用中验证。但整体方向是对的,把记忆层做成标准化的基础设施,能显著降低 Agent 应用的开发门槛。
如果你正在开发 Agent 应用,尤其是需要多轮交互和个性化能力的场景,Agent Memory 值得一试。它不会解决所有问题,但至少能让你少写很多基础设施代码,把精力放在真正重要的事情上。
OpenAI Hub 已经支持 Cloudflare Agent Memory 的调用,可以直接通过统一的 API Key 访问。对国内开发者来说,这意味着不用翻墙、不用担心网络问题,就能用上 Cloudflare 的全球基础设施。
参考来源
- Cloudflare 现在支持托管 Agent Memory (测试版) - Linux.do 社区对 Agent Memory 的讨论和初步评测
- Agent Memory(上):记忆的形态、功能与代表性路径 - 知乎专栏深度解析 Agent 记忆系统的技术原理和实现路径
