DeepSeek V4 下周发布,三大架构组件曝光

DeepSeek 创始人梁文锋确认 V4 将于 4 月下旬发布,万亿参数、百万上下文,核心是 Engram 条件记忆架构、流形约束超连接和 DualPath 双路径系统三大技术突破。
DeepSeek V4 下周发布,三大架构组件曝光
DeepSeek 创始人梁文锋 4 月 10 日在内部沟通中确认:新一代旗舰模型 DeepSeek V4 将于 4 月下旬正式发布。这是继 R1 推理模型之后,DeepSeek 今年最重要的产品更新。
更关键的是,普林斯顿博士生 Yifan Zhang 在社区透露了 V4 的三项核心架构组件:Engram 条件记忆架构、流形约束超连接(mHC)、DualPath 双路径推理系统。这三个技术点不是简单的参数堆叠,而是从底层重构了大模型的记忆、训练和推理机制。
从去年 V3 以"低成本高性能"颠覆行业认知,到现在 V4 的架构级创新,DeepSeek 的打法越来越清晰:不跟 OpenAI 拼算力,而是拼效率和工程能力。
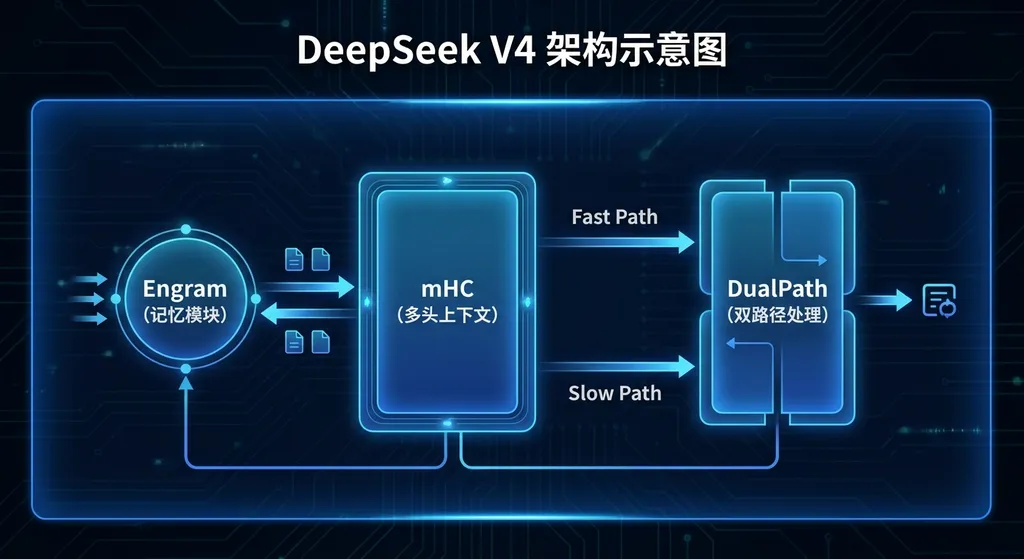
Engram:把"记忆"和"计算"拆开
传统 Transformer 架构有个根本问题:知识存储和逻辑推理混在一起。模型既要记住"巴黎是法国首都"这种静态知识,又要处理"如果 A 大于 B,B 大于 C,那么 A 和 C 的关系"这种动态推理。两件事用同一套参数做,效率低,成本高。
Engram 的思路是把静态知识记忆和动态逻辑计算分离。具体怎么做,DeepSeek 还没公开细节,但从名字看(Engram 在神经科学里指"记忆痕迹"),大概率是引入了类似外部知识库的机制,让模型在推理时可以按需调用知识,而不是把所有知识都塞进参数里。
这个设计的好处是:
- 参数效率更高:同样的参数量,能处理更复杂的任务
- 知识更新更灵活:不用每次都重新训练整个模型
- 长上下文处理更稳定:V4 的百万 Token 上下文窗口,很可能就是靠 Engram 撑起来的
类比一下,传统模型像是把整本百科全书背下来,Engram 更像是记住了图书馆的索引系统——需要什么知识,去查就行。
mHC:让超大模型训练不崩
万亿参数模型的训练有多难?梯度爆炸、梯度消失、训练不收敛,这些问题在小模型上可能只是偶尔出现,在超大模型上几乎是常态。
流形约束超连接(mHC) 是 DeepSeek 针对这个问题设计的稳定性技术。从名字看,"流形约束"指的是对模型拓扑结构的几何约束,"超连接"可能是指跨层的残差连接或者注意力机制的改进。
官方数据显示,mHC 让超大模型的训练效率提升了约 30%。这个数字很实在——对于动辄几千万美元训练成本的模型来说,30% 的效率提升意味着省下上千万美元和几周时间。
更重要的是,mHC 让 DeepSeek 可以在国产算力上训练超大模型。华为昇腾、寒武纪这些芯片的算力密度和互联带宽都不如英伟达 H100,但通过算法层的优化,DeepSeek 正在证明"不用顶配美国芯片也能训练世界级模型"。
DualPath:把闲置网卡利用起来
推理侧的瓶颈在哪?KV-Cache。
大模型推理时,每个 Token 的注意力计算都需要访问之前所有 Token 的 Key 和 Value,这些数据存在 KV-Cache 里。上下文越长,KV-Cache 越大,显存压力越大,推理速度越慢。
DualPath 双路径系统的思路是:把 KV-Cache 的加载压力分摊到闲置的网卡资源上。具体实现可能是把部分 KV-Cache 存到远程节点,通过高速网络按需加载。这个设计结合了北大、清华团队的智能体推理框架,在线服务吞吐量提升了近 2 倍。
这个优化很工程化,但很实用。对于企业级部署来说,吞吐量翻倍意味着同样的硬件成本可以服务更多用户,或者同样的用户量可以省一半机器。
百万上下文 + 长期记忆:不只是窗口变大
V4 的上下文窗口升级到 百万 Token,这个数字本身不稀奇——Gemini 1.5 Pro 早就做到了 200 万 Token。关键是 DeepSeek 怎么用这个窗口。
传统大模型的上下文是"一次性"的:对话结束,上下文清空,下次重新开始。V4 引入了 长期记忆(LTM) 机制,让模型可以在多次对话中积累和调用历史信息。
这个能力对企业级应用是刚需。举个例子:
- 代码审查:模型可以记住项目的代码规范、历史 PR 的讨论,给出更符合团队习惯的建议
- 文档问答:模型可以记住用户之前问过的问题和反馈,避免重复解释
- 客服系统:模型可以记住用户的偏好和历史工单,提供更个性化的服务
LTM 的实现细节还不清楚,但从 Engram 架构看,很可能是通过外部记忆库 + 检索增强的方式做的。这个方向上,DeepSeek 不是第一个尝试的,但如果能在万亿参数模型上做到稳定可用,就是工程能力的体现。
原生多模态:不是拼接,是融合
V4 采用了 原生多模态融合架构,在预训练阶段就把图像、视频、文本统一处理,而不是像 GPT-4V 那样用独立的视觉编码器 + 语言模型拼接。
原生多模态的好处是:
- 跨模态理解更深:模型可以在预训练时学习图像和文本的深层关联,而不是后期"硬拼"
- 推理效率更高:不需要额外的模态转换开销
- 训练更稳定:统一的损失函数,避免多模态对齐的复杂性
这个方向上,Google 的 Gemini 走得最激进,DeepSeek 算是跟进。但考虑到 V4 的开源属性,如果多模态能力真的做到 Gemini 的水平,对开源社区的影响会很大。
国产算力适配:战略意义大于技术意义
V4 的一个重要特点是深度适配华为昇腾等国产算力平台。这不是简单的移植,而是从算子优化、推理引擎到分布式训练框架的系统级重构。
梁文锋透露,这是 V4 延期的主要原因之一。从技术角度看,国产芯片的算力密度、互联带宽、软件生态都不如英伟达,适配成本高、收益不明显。但从战略角度看,这是 DeepSeek 必须做的事——如果中国 AI 公司永远依赖美国芯片,那技术再先进也是"沙滩上的城堡"。
据悉,阿里、字节、腾讯等公司已经预订了数十万片新一代 AI 算力芯片,计划通过云服务提供 V4。受此影响,新型 AI 芯片的市场价格近期上涨了约 20%。这个数字背后,是整个产业在为 V4 的规模化部署做准备。
开源 + 商业化:DeepSeek 的新阶段
V4 将继续遵循 Apache 2.0 协议开源,企业可以自主部署、商业使用。这是 DeepSeek 一直坚持的路线,也是它和 OpenAI 最大的区别。
但开源不等于不赚钱。梁文锋透露,DeepSeek 正在组建产品团队,并发布了"模型策略产品经理"职位招聘。这标志着 DeepSeek 开始从"技术演示"向产品化和商业化转型。
可能的商业模式包括:
- API 服务:提供托管的 V4 API,按调用量收费
- 企业私有化部署:提供定制化的部署和优化服务
- 行业解决方案:针对金融、医疗、法律等垂直领域提供微调和应用开发服务
这个转型对 DeepSeek 的长期竞争力很重要。技术再好,如果没有可持续的商业模式,就很难在 OpenAI、Google 这些巨头的竞争中活下来。
V4 vs GPT-6:两条路线的正面对决
就在 V4 发布的同一时间窗口,OpenAI 的 GPT-6(代号"Spud")也在坊间盛传即将发布,据称性能提升超过 40%,支持 200 万 Token 上下文。
两款全球顶级大模型在同一时间亮相,这对整个 AI 行业来说是罕见的"双雄对决"时刻。从技术路线看:
GPT-6:
- 大规模算力堆叠(据传训练成本超过 10 亿美元)
- 商业闭源,通过 API 服务变现
- 依赖英伟达顶配芯片
- 强调通用能力和用户生态
DeepSeek V4:
- 效率优先,训练成本控制在千万美元级别
- 开源普惠,Apache 2.0 协议
- 适配国产算力,降低部署门槛
- 强调架构创新和工程能力
两者的差异很有代表性:GPT-6 的优势在于资本壁垒和用户生态,V4 的优势在于可访问性和生态自主性。前者是"高墙花园",后者是"开放平原"。
从竞争格局看,V4 不太可能在短期内撼动 GPT-6 的市场地位——OpenAI 的品牌、生态、资本优势太明显。但 V4 的意义在于:中国 AI 团队已经具备在最顶尖的技术层面与全球第一梯队正面竞争的能力。不是以"低成本替代品"的身份,而是以真正的技术创新者的身份。
对开发者的影响
V4 发布后,开发者可以通过 DeepSeek 官方 API 或者 OpenAI Hub 这类聚合平台调用。如果你已经在用 OpenAI 的 SDK,切换到 V4 几乎不需要改代码:
from openai import OpenAI
# 通过 OpenAI Hub 调用 DeepSeek V4
client = OpenAI(
api_key=\"your-openai-hub-key\",
base_url=\"https://api.openai-hub.com/v1\"
)
response = client.chat.completions.create(
model=\"deepseek-v4\",
messages=[
{\"role\": \"system\", \"content\": \"你是一个代码审查助手,熟悉 Python 和 Go 的最佳实践。\"},
{\"role\": \"user\", \"content\": \"帮我审查这段代码:\
\
```python\
def process_data(data):\
result = []\
for item in data:\
if item > 0:\
result.append(item * 2)\
return result\
```\"}
],
max_tokens=2000
)
print(response.choices[0].message.content)
如果要用 V4 的长期记忆能力,可能需要额外的 API 参数(具体等官方文档):
response = client.chat.completions.create(
model=\"deepseek-v4\",
messages=[...],
# 启用长期记忆,关联到特定用户或会话
user=\"user-123\",
session_id=\"session-456\",
# 允许模型访问历史对话
enable_long_term_memory=True
)
对于需要处理超长文档的场景(比如分析整个代码仓库、审查长篇合同),V4 的百万上下文窗口可以一次性塞进去,不用再做分块和摘要:
# 读取整个代码仓库的文件
repo_content = \"\"
for file in repo_files:
with open(file, 'r') as f:
repo_content += f\"\
\
# File: {file}\
{f.read()}\"
response = client.chat.completions.create(
model=\"deepseek-v4\",
messages=[
{\"role\": \"system\", \"content\": \"你是一个代码架构分析师。\"},
{\"role\": \"user\", \"content\": f\"分析这个代码仓库的架构设计,指出潜在的问题:\
\
{repo_content}\"}
],
max_tokens=5000
)
几个值得关注的点
-
V4 的实际性能:架构创新听起来很美,但最终还是要看 benchmark 和实际使用体验。DeepSeek 之前在 V3 上的表现证明了他们的工程能力,V4 应该不会让人失望。
-
国产算力的成熟度:V4 对昇腾的深度适配,某种程度上是在给国产 AI 芯片"背书"。如果 V4 能在昇腾上跑得又快又稳,会极大提振国产算力生态的信心。
-
开源社区的反应:V4 开源后,会不会像 LLaMA 那样催生一大批微调版本和应用?这取决于 V4 的易用性和文档质量。
-
商业化的进展:DeepSeek 能不能在开源的同时找到可持续的商业模式?这关系到它能不能在长期竞争中活下来。
写在最后
DeepSeek V4 的发布,标志着中国 AI 进入了一个新阶段:不再是追赶和模仿,而是在关键技术方向上提出自己的解决方案。Engram、mHC、DualPath 这些架构组件,不是简单的工程优化,而是对大模型底层机制的重新思考。
从 V3 的"低成本高性能"到 V4 的"架构级创新",DeepSeek 的打法越来越清晰:不跟 OpenAI 拼算力和资本,而是拼效率、拼工程能力、拼对开发者的理解。这条路能走多远,V4 的表现会给出答案。
下周见。
参考来源
- DeepSeek V4 就快来了(据说这周发布),你有什么期待? - Linux.do - 社区讨论,包含普林斯顿博士生 Yifan Zhang 透露的架构细节
- DeepSeek V4 要来了:1 万亿参数、100 万上下文 - 知乎 - 技术分析文章,详细解读 Engram 架构
OpenAI Hub 已支持 DeepSeek V3,V4 发布后将第一时间接入。
