Codex 会话终于能「看见」了

OpenAI 开源 Codex 会话管理与可视化工具,开发者可加载 JSON 日志直观调试多智能体任务,支持元数据检查、多语言翻译、数据集清洗与协作分享,补上了 Codex 生态的关键一环。
OpenAI 这周悄悄放出了一个不少 Codex 用户等了很久的东西——一套开源的会话管理与可视化工具。名字叫 Euphony,做的事情很直接:让你能看清楚 Codex 智能体到底在干什么、干了什么、在哪一步出了问题。
这听起来像是个小功能,但用过 Codex 跑多智能体任务的人都知道,会话管理和调试一直是个痛点。你让三个智能体并行改代码,任务跑完了,想回溯某个智能体为什么做了一个奇怪的决策?以前基本靠翻 JSON 日志肉眼 grep。现在终于有了正经的可视化方案。
为什么这件事值得关注
先说背景。Codex 在过去几个月的进化速度相当快。从最早的代码补全工具,到现在官网首页写的「智能体式编码的指挥中心」,它的定位已经完全变了。最新版本支持多智能体并行工作、处理 GitHub 代码评审、管理多终端窗口、SSH 连接远程环境——本质上它已经不是一个「写代码的 AI」,而是一个「帮你管理开发流程的智能体编排平台」。
OpenAI 自己的工程团队甚至做了一个极端实验:三个工程师用 Codex 在几周内交付了一个百万行代码的项目,平均每人每天处理 3.5 个 PR。他们的原话是「只用了手工编写代码所需的大约 1/10 的时间」。
但问题也随之而来。当你把越来越多的开发环节交给智能体,你就越需要知道它们在做什么。这不是信任问题,是工程问题。一个智能体跑偏了,如果你没有办法快速定位到具体是哪一轮对话、哪个系统指令、哪次工具调用出了问题,调试成本会指数级上升。
这就是 Euphony 要解决的事。
Euphony 具体能做什么
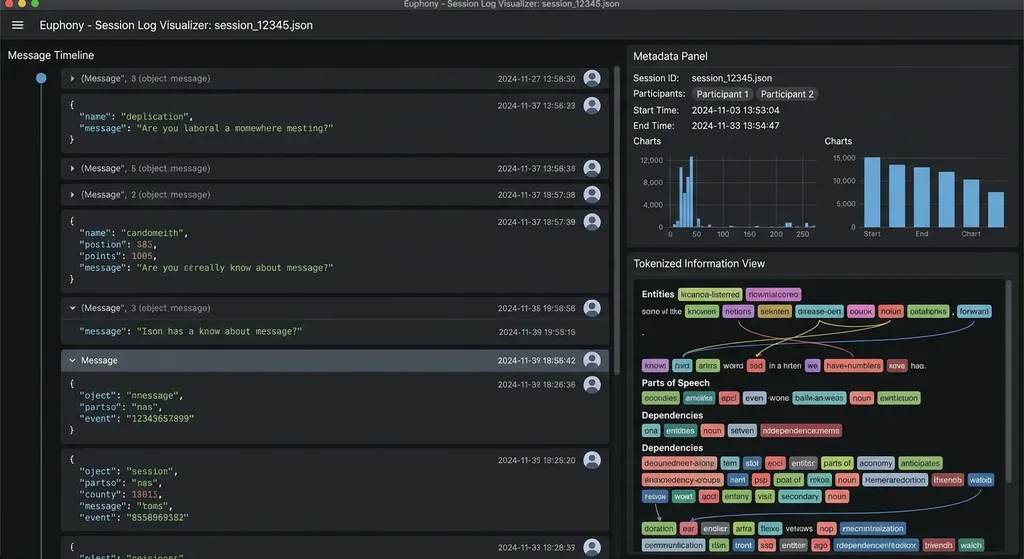
拆开来看,Euphony 提供了五个核心能力:
1. 调试 AI 聊天记录
加载 Codex 产生的 JSON 日志文件,完整展示元数据、提示堆栈和标记化信息。这是最基础也最重要的功能。
举个实际场景:你让 Codex 智能体去重构一个模块,它跑了二十几轮对话,最后生成的代码有个隐蔽的 bug。以前你得打开那个动辄几千行的 JSON 文件,在嵌套的 input 数组里一层层找。现在 Euphony 把整个对话流程铺成时间线,每一轮的系统指令、用户输入、智能体响应、工具调用都分门别类展示。你可以直接点到某一轮,看到完整的 prompt 堆栈——包括那些你可能忘了自己设过的 AGENTS.md 规则。
这个功能对理解 Codex 的智能体循环特别有用。熟悉 Codex 架构的开发者知道,它的核心是一个基于 Responses API 的循环:发送请求 → 处理事件流 → 执行工具调用 → 把结果追加到 input → 发送下一轮请求。每一轮的 input 都包含之前所有轮次的完整历史,数据量是二次增长的。Euphony 让你能直观地看到这个膨胀过程,快速判断是不是上下文窗口被撑满导致了智能体行为退化。
2. 可视化 Codex 会话
这个功能面向的是更宏观的视角。它不只是展示对话内容,而是把整个开发工作流可视化——代码库结构、文件变更列表、智能体的操作轨迹。
想象一个场景:你用 Codex 同时开了五个任务,分别处理前端组件、后端 API、数据库迁移、测试用例和 CI 配置。每个任务背后是一个独立的智能体会话。Euphony 可以把这五个会话的文件变更叠加到同一个代码库视图上,让你一眼看出哪些文件被多个智能体同时修改了——这在多智能体协作中是最容易出问题的地方。
官方给的例子是「多智能体游戏开发会话」,追踪沙盒代码的变更。这个例子选得很聪明,因为游戏开发天然涉及大量并行任务(渲染、物理、AI、网络),正好是多智能体编排的典型场景。
3. 多语言翻译与探索
这个功能乍看有点意外,但仔细想想很合理。Codex 的用户遍布全球,很多团队的内部讨论、研究笔记、需求文档都不是英文的。Euphony 支持用 Markdown 公式自动翻译非英语对话,让团队成员可以直接审阅其他语言的聊天记录。
官方举的例子是「团队可以直接审阅中文研究聊天记录」。对于国内开发者来说,这意味着你可以用中文和 Codex 交互,然后把会话记录分享给英文团队审阅,中间不需要手动翻译。反过来也一样。
4. 数据集筛选与编辑
这个功能把 Euphony 的定位从「调试工具」扩展到了「数据工具」。你可以用它浏览、编辑、筛选 Codex 会话中的特定消息,然后导出清洗后的数据。
最直接的用途是清理训练数据。如果你在用 Codex 的会话记录做微调数据集,里面难免有噪声——比如智能体的自我纠正、重复的工具调用、无意义的中间状态。以前你得写脚本处理,现在可以在 Euphony 的界面里直接操作,上传前把噪声去掉。
5. 协作与分享
支持生成对话或特定消息的直接链接。这个功能看起来简单,但在团队协作中非常实用。
以前提 bug 报告是这样的:「Codex 在处理 XX 任务时出了问题,我把日志文件附在附件里了,你看第 847 行到第 923 行。」现在是这样的:「这是出问题的那轮对话的链接,你点开就能看到完整上下文。」
效率差距不用多说。
放在 Codex 生态里看
要理解 Euphony 的意义,得把它放到 Codex 整个生态的演进脉络里看。
OpenAI 在今年初发布了一篇很有意思的工程博客,详细拆解了 Codex 的智能体循环。文章里有一个关键洞察:Codex CLI 发送到 Responses API 的数据量是二次增长的。每一轮对话都要把之前所有轮次的完整历史打包发送。虽然 API 提供了 previous_response_id 参数来缓解这个问题,但 Codex 为了保持请求无状态和支持零数据保留配置,选择不使用它。
这意味着一个长会话的 JSON 日志可能非常庞大,结构也非常深。没有专门的可视化工具,人工审阅几乎不可能。Euphony 本质上是在补这个架构决策带来的可观测性缺口。
再看 OpenAI 自己的工程实践。他们在那个百万行代码项目中总结了一个重要经验:「Codex 会复现代码仓库中已存在的模式——甚至包括那些不均衡或不够理想的模式。随着时间的推移,这不可避免地导致漂移。」他们的应对方式是建立「黄金原则」和循环清理流程,定期运行后台 Codex 任务扫描偏差。
但要发现偏差,首先得能看到偏差。Euphony 提供的会话可视化能力,正好是这个反馈循环中缺失的一环。你可以用它回溯智能体的决策过程,找到模式漂移的起点,然后针对性地更新 AGENTS.md 或黄金原则。
对开发者意味着什么
说点实际的。
如果你现在在用 Codex 做日常开发,Euphony 最直接的价值是降低调试成本。多智能体任务出了问题,不用再肉眼翻 JSON,直接在可视化界面里定位。
如果你在做更复杂的智能体编排——比如让 Codex 自动处理 PR 评审、自动修复 CI 失败、自动响应代码审查意见——Euphony 的会话追踪能力会变得更关键。因为这些场景下,智能体的决策链条更长,出错的可能性更多,人工介入的成本也更高。
如果你在做 AI 相关的研究或数据工作,数据集筛选和多语言翻译功能可能是意外之喜。
值得一提的是,Euphony 是开源的。这意味着你可以根据自己的需求做定制——比如接入自己的日志系统、添加自定义的分析维度、或者把它集成到现有的开发工具链里。对于那些在 Codex 基础上构建内部工具的团队来说,这比一个封闭的 SaaS 产品有用得多。
横向对比:可观测性这件事
其实不只是 OpenAI,整个 AI 智能体领域都在补可观测性的课。
LangSmith 做 LangChain 的链路追踪,Weights & Biases 做实验管理,Arize 做模型监控。但这些工具大多面向的是通用的 LLM 应用,对 Codex 这种深度集成开发工具链的智能体编排平台来说,通用工具往往不够贴合。
比如 Codex 的 shell 工具调用、plan 更新、MCP 服务器集成,这些都是 Codex 特有的概念。通用的 LLM 可观测性工具可能只能把它们当作普通的 function call 来展示,丢失了很多语义信息。Euphony 作为官方工具,天然理解这些概念,展示效果会更好。
当然,Euphony 目前看起来还比较早期。从社区反馈来看,它解决了「有没有」的问题,但在「好不好用」上还有提升空间。比如对超大日志文件的性能表现、对复杂多智能体会话的可视化布局、以及与 IDE 的集成深度,这些都需要时间打磨。
一个更大的趋势
往远了说,Euphony 的出现反映了一个更大的趋势:当 AI 智能体从「辅助工具」变成「协作伙伴」,开发者需要的不只是更强的模型,还需要更好的工具来理解和管理这些智能体。
OpenAI 自己的工程团队在那篇博客里说了一句很到位的话:「当软件工程团队的主要工作不再是编写代码,而是设计环境、明确意图和构建反馈回路时,会发生哪些变化。」
反馈回路的前提是可观测性。你得先看到智能体在做什么,才能判断它做得对不对,才能调整环境和意图让它做得更好。Euphony 就是这个反馈回路里的「眼睛」。
对于正在用 Codex 或者考虑用 Codex 的团队,建议关注这个工具的后续发展。它现在可能还不够完善,但方向是对的。在多智能体协作成为常态的未来,谁先建立起有效的可观测性体系,谁就能更早地从 AI 辅助开发中获得真正的效率提升,而不是在调试智能体的黑箱上浪费时间。
顺便说一句,Codex 背后的模型(包括 GPT-5.3-Codex 等)如果你想在自己的项目里调用,OpenAI Hub 已经支持了,一个 Key 就能跑,国内直连也没问题。
参考来源:
- OpenAI 官方推出 Codex 会话管理和可视化功能 - Linux.do — 社区讨论帖,包含 Euphony 功能概览和开发者反馈
