Trellis v0.5 Beta 实测:多智能体编排走进主流团队

多智能体编排框架 Trellis 发布 v0.5 Beta,在易用性上做了大幅改进,已被多家大中厂五十人以上部门采用。我们实测了这个版本,聊聊它解决了什么问题,还有哪些坑没填。
Trellis v0.5 Beta 上周正式推送。这个在开发者社区里口碑两极分化的多智能体编排框架,终于在易用性上迈了一大步。
据作者在 Linux.do 社区透露,Trellis 目前已经被国内外多家大厂和中厂的团队采用,部分部署规模超过五十人。这个数字放在 AI 框架赛道里不算炸裂,但对于一个社区驱动的开源项目来说,已经说明了一些问题——至少有人愿意把它用在生产环境里,而不只是跑个 demo 发条推。
先说背景:为什么又来一个框架
做 AI 应用的开发者大概都有同一个感受:框架太多了。
LangChain、LlamaIndex、CrewAI、AutoGen、MetaGPT……每隔几周就冒出一个新的编排框架,每个都号称自己是"终极方案"。Linux.do 上有个帖子标题直接写"现在的 AI 框架也太多了吧",底下的讨论基本就是开发者的集体吐槽现场。
但吐槽归吐槽,需求是真实的。当你的应用不再是"一个 prompt 进去、一段文本出来"的简单链路,而是需要多个 Agent 协作完成复杂任务时,你确实需要一个编排层。问题在于,现有的框架要么太重(LangChain 的抽象层数能让人迷路),要么太轻(一些轻量方案在多 Agent 协调上基本靠祈祷)。
Trellis 试图找一个中间地带。
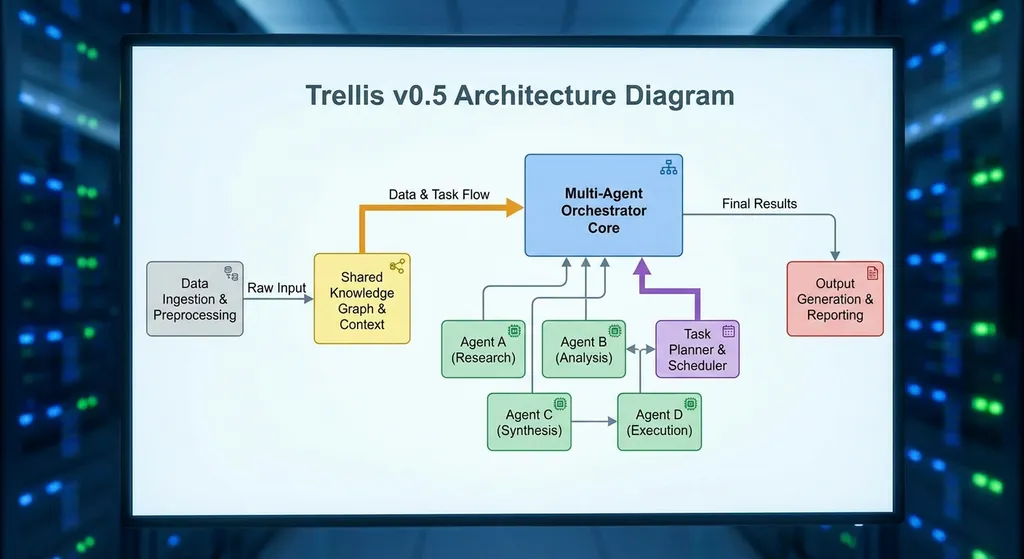
v0.5 到底改了什么
要理解 v0.5 的意义,得先知道之前的版本有多让人头疼。
社区里一位用户的反馈非常典型:"之前我用 4.0,后面它自己都忘记这个框架了,而且 PRD task 规划好的任务列表都不做。"这句话信息量很大——Agent 在执行多步任务时会"失忆",规划好的任务链执行到一半就断了。这不是 Trellis 独有的问题,几乎所有多智能体框架在长链路任务上都会遇到上下文丢失的困境,但 Trellis 早期版本显然没处理好。
根据目前公开的信息和社区讨论,v0.5 Beta 的改进主要集中在几个方向:
1. 文档站大改
这听起来不性感,但可能是最实际的改进。作者在社区里提到"beta 文档站大改",并放出了新的文档地址。对于一个框架来说,文档质量直接决定了上手成本。之前 Trellis 的一个痛点就是文档跟不上迭代速度,开发者经常发现文档里的示例代码跑不通,或者某个关键概念没有解释清楚。
新文档站至少在结构上做了重新组织,这对于想要评估和试用的团队来说,门槛降低了不少。
2. 易用性大幅提升
作者原话是"在易用性方面做了非常多提升"。结合社区讨论来看,这大概率包括:
- 任务编排的配置方式简化,减少了样板代码
- Agent 之间的通信机制更加透明,调试时能看清楚数据流向
- 对主流模型的适配更加开箱即用
这些改进的方向是对的。多智能体编排框架最大的敌人不是功能不够多,而是开发者在调试时完全看不懂"这几个 Agent 之间到底在聊什么"。如果 v0.5 真的在可观测性上下了功夫,那确实值得关注。
3. 更新节奏加快
作者提到"最近更新太多",这既是好事也是隐患。好的一面是团队在积极迭代,坏的一面是对于已经在生产环境使用的团队来说,频繁更新意味着频繁的兼容性验证。不过考虑到目前还是 Beta 阶段,这个节奏可以理解。
跟竞品比,Trellis 的位置在哪
说实话,多智能体编排这个赛道现在非常拥挤。我们把几个主流选手拉出来对比一下:
LangChain / LangGraph:生态最大,社区最活跃,但抽象层太多,调试体验差。很多开发者的感受是"用 LangChain 写完之后,不知道自己到底写了什么"。LangGraph 在编排能力上有改进,但学习曲线依然陡峭。
CrewAI:上手简单,角色定义直观,适合快速搭建多 Agent 原型。但在复杂场景下的控制粒度不够,生产环境部署的案例相对少。
AutoGen(微软):背靠大厂,在多 Agent 对话模式上有独到设计。但框架本身偏研究导向,工程化程度不如预期。
MetaGPT:以软件开发流程为核心场景,SOP 驱动的设计思路很有意思,但场景适用面相对窄。
Trellis 的差异化在哪?从目前的信息来看,它试图在"够用的抽象"和"足够的控制力"之间找平衡。它不像 LangChain 那样试图包办一切,也不像 CrewAI 那样只做最简单的场景。五十人团队的采用案例说明它在工程化方面做得还行——至少能扛住一定规模的协作开发。
但说实话,Trellis 目前最大的短板是生态。LangChain 有海量的第三方集成和社区插件,CrewAI 有简洁的上手体验,AutoGen 有微软的背书。Trellis 作为一个社区项目,在这些维度上都不占优。它能走多远,很大程度上取决于接下来几个版本能不能持续兑现"易用性"的承诺。
多智能体编排的真实需求到底有多大
这是一个值得冷静思考的问题。
过去一年,"Agent"这个词被严重滥用了。很多所谓的"多智能体系统",本质上就是几个 prompt 串起来跑,加个循环判断就号称"自主决策"。真正需要复杂多 Agent 编排的场景,在实际业务中占比并不高。
但确实存在一些场景,单 Agent 搞不定:
- 复杂的代码生成与审查流程:一个 Agent 写代码,一个 Agent 做 code review,一个 Agent 跑测试,彼此之间需要多轮交互。这比单纯让一个模型"一次性写对"要靠谱得多。
- 多步骤的数据分析管线:数据清洗、特征工程、模型选择、结果解读,每个环节的 Agent 有不同的工具集和专业知识。
- 企业级的工作流自动化:涉及多个系统、多个审批节点、多种异常处理路径的业务流程,单 Agent 的上下文窗口和推理能力很难覆盖。
这些场景的共同特点是:任务链路长、中间状态多、需要不同"专业能力"的协作。在这些场景下,一个好的编排框架确实能省很多事。
问题是,大部分开发者的日常需求还没到这个复杂度。对于"调一个 API、处理一下返回、做个简单判断"这种场景,直接写几十行代码比引入任何框架都高效。
所以 Trellis 的目标用户画像其实很清晰:有一定规模的团队,在做有一定复杂度的 AI 应用,需要多个 Agent 协作,并且希望有一个统一的编排层来管理这些 Agent 的生命周期和通信。
从 Vibe Coding 到工程化:框架的角色在变
一个有意思的背景是,Trellis 的讨论经常出现在"vibe coding"相关的话题里。
Vibe coding——用自然语言描述需求,让 AI 直接生成代码——在过去半年里从一个梗变成了一种真实的开发方式。越来越多的开发者发现,对于原型开发和小型项目,vibe coding 的效率确实高得离谱。
但当项目规模变大、团队人数变多时,vibe coding 的局限性就暴露了:生成的代码缺乏一致性,不同 Agent 之间的协作缺乏规范,出了 bug 很难定位。这时候就需要一个框架来提供结构和约束。
Trellis 在这个语境下的价值是:它不是要替代 vibe coding,而是要给 vibe coding 加上工程化的骨架。你可以继续用自然语言描述任务,但任务的分解、分配、执行、监控都有框架来管。
这个定位是合理的。AI 辅助开发正在从"个人效率工具"向"团队协作基础设施"演进,编排框架在这个过程中扮演的角色会越来越重要。
实际使用建议
如果你正在评估是否要在项目中引入 Trellis v0.5 Beta,这里有几点建议:
适合尝试的情况:
- 你的团队已经在做多 Agent 应用,现有方案(或者没有方案)让你很痛苦
- 你对 LangChain 的复杂度感到厌倦,想要一个更轻量但不失控制力的替代
- 你愿意接受 Beta 阶段的不稳定性,并且有能力参与社区反馈
暂时观望的情况:
- 你的应用场景用单 Agent 就能搞定,没必要为了"多智能体"而多智能体
- 你的团队对框架稳定性要求很高,不能接受 Beta 版本的风险
- 你已经在 LangGraph 或 AutoGen 上投入了大量工程,迁移成本太高
一个务实的做法是:先在一个非核心项目上试用 v0.5 Beta,跑通一个完整的多 Agent 工作流,评估一下框架的实际表现和团队的学习成本,再决定是否大规模采用。
顺便提一句,不管你用哪个编排框架,底层的模型调用都是绑不开的。如果你的 Agent 需要调用不同的模型(比如推理用 Claude,生成用 GPT,轻量任务用 DeepSeek),可以看看 OpenAI Hub 这类 API 聚合服务,一个 Key 统一调用,省得在框架里维护一堆不同的 API 配置。
写在最后
AI 框架赛道的淘汰赛还在继续。每个月都有新框架诞生,也有旧框架被遗忘。Trellis v0.5 Beta 的发布不是一个里程碑式的事件,但它代表了一个值得关注的趋势:多智能体编排正在从"实验室玩具"变成"生产工具"。
能不能真正站稳,取决于接下来几个月的执行力。文档能不能跟上、社区能不能活跃起来、大厂的采用案例能不能公开分享——这些比任何技术细节都重要。
框架之争的终局从来不是谁的架构最优雅,而是谁能让开发者最快地把事情做完。Trellis 在 v0.5 上押注"易用性",方向没错。剩下的,交给时间。
参考来源
- 现在的 AI 框架也太多了吧… — Linux.do 社区讨论,Trellis 作者自荐及大厂采用情况披露
- 对于 Trellis 框架的 Q & A — Linux.do 社区,用户对 Trellis 早期版本的使用反馈
- 累了,来几个摸鱼的佬友聊聊天,关于 vibe coding 进阶 — Linux.do 社区,Trellis 作者关于 v0.5 更新和文档站改版的说明
