27B 干翻 397B:Qwen3.6 最强开源稠密模型来了

阿里通义千问今日开源 Qwen3.6-27B,270 亿参数稠密模型在所有主要编程基准上全面超越前代 15 倍参数量的 MoE 旗舰,成为当前最具部署性价比的智能体编程模型。
阿里通义千问团队今天放出了 Qwen3.6 开源家族的第三张牌——Qwen3.6-27B。一个 270 亿参数的稠密多模态模型,在所有主要编程基准上全面超越了前代旗舰 Qwen3.5-397B-A17B。
后者是什么规格?总参数 397 亿,激活参数 17 亿的 MoE 模型。换句话说,一个体量只有它零头的稠密模型,把它按在地上摩擦了。
这不是 PR 话术,是跑分实打实说话。
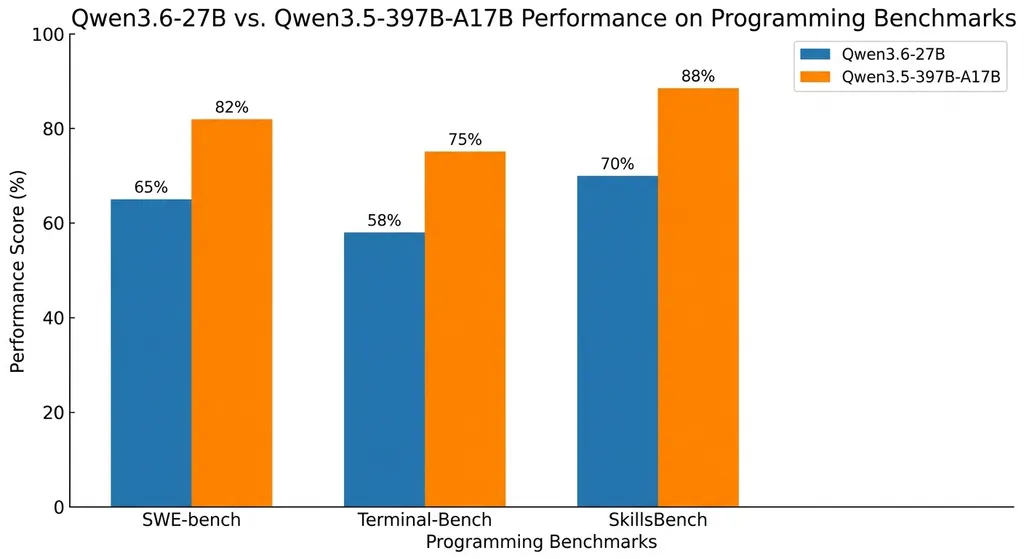
数字说话:编程能力全面碾压
先看最硬的指标。SWE-bench 是当前衡量模型真实软件工程能力最被认可的基准之一——不是让你补全一行代码,而是给你一个真实的 GitHub issue,让模型自己定位问题、修改代码、提交 patch。
Qwen3.6-27B 的成绩单:
- SWE-bench Verified:77.2(前代 76.2)
- SWE-bench Pro:53.5(前代 50.9)
- Terminal-Bench 2.0:59.3(前代 52.5)
- SkillsBench:48.2(前代 30.0)
每一项都在涨,但最值得注意的是 SkillsBench——从 30.0 跳到 48.2,涨幅超过 60%。SkillsBench 测的是模型在多样化编程技能上的综合表现,这个幅度的提升意味着 Qwen3.6-27B 不只是在某个单点上做了优化,而是编程能力的底层水位整体抬高了。
Terminal-Bench 2.0 从 52.5 到 59.3 也很说明问题。这个基准考察的是模型在终端环境下的交互式编程能力——读日志、跑命令、调试报错、迭代修复——本质上就是智能体编程的核心场景。接近 7 个点的提升,对于实际使用体验的改善是非线性的。
而这一切,是用 27B 参数做到的。对面是 397B。
稠密 vs MoE:为什么这件事值得单独说
可能有人会说,MoE 模型的激活参数只有 17B,实际推理时的计算量并不比 27B 大多少,拿总参数量来比不公平。
这个说法有道理,但只说对了一半。
MoE 的优势在于用更少的计算量撬动更大的参数空间,理论上能获得更好的效果。但它的代价是部署复杂度。397B 的总参数意味着你需要把整个模型加载到显存里——即使每次推理只激活一部分专家,模型权重本身是要全量驻留的。对于大多数开发者和中小团队来说,这直接决定了你需要几张卡、什么规格的卡。
27B 稠密模型就简单多了。没有专家路由的额外开销,没有 MoE 特有的负载均衡问题,部署就是标准流程。一张主流的消费级或专业级 GPU(比如 RTX 4090 或 A100 40G),做量化后就能跑起来。对于想在本地或私有环境部署智能体编程助手的团队来说,这个规格几乎是甜点级的。
阿里自己也很清楚这一点。官方博客里用了一个很直白的表述:"开发者在实用、可广泛部署规模上获取顶尖编程能力的理想选择。" 翻译一下就是——我们知道你们要的不是跑分最高的模型,而是你们真正能用起来的最强模型。
27B 这个规格本身也不是随便选的。官方提到这是"社区呼声最高的模型规格"。回顾 Qwen 的开源历史,从 Qwen2.5 时代的 7B/14B/32B/72B 到 Qwen3 系列的参数调整,27B 这个档位一直是社区讨论最多的——大到能干活,小到能部署,恰好卡在实用性的最优区间。
不只是编程:推理和多模态同样在线
编程能力是 Qwen3.6-27B 的主打卖点,但它并不是一个只会写代码的模型。
在推理任务上,GPQA Diamond 拿到了 87.8。GPQA 是一个由领域专家出题的高难度问答基准,Diamond 是其中最难的子集,涵盖物理、化学、生物等学科的研究生级别问题。87.8 这个分数,官方的说法是"可与数倍于其规模的模型相媲美"。考虑到这个基准上 Claude 3.5 Sonnet 大约在 65 左右,GPT-4o 在 53 左右(注意这些是较早的数据,各家都在迭代),Qwen3.6-27B 的推理能力确实已经进入了第一梯队。
多模态方面,Qwen3.6-27B 原生支持图像、视频和文本的混合输入。这不是后期拼接一个视觉编码器上去的方案,而是训练阶段就融合了多模态数据。官方表示其视觉语言能力与此前发布的 Qwen3.6-35B-A3B 保持一致——后者在 RefCOCO 上拿到 92.0,在多数视觉语言基准上与 Claude Sonnet 4.5 持平甚至超越。
对于开发者来说,这意味着你可以用同一个模型处理代码审查、文档理解、UI 截图分析等混合场景,不需要为不同模态切换不同的模型。在智能体工作流中,这种统一性的价值比单项跑分更大。
Qwen3.6 家族的排兵布阵
把 Qwen3.6 已经发布的三个模型放在一起看,阿里的产品策略就很清晰了:
- Qwen3.6-Plus:闭源旗舰,通过百炼 API 调用,面向追求极致效果、不在乎部署成本的场景
- Qwen3.6-35B-A3B:开源 MoE,总参数 35B / 激活参数 3B,极致轻量,适合资源受限的边缘部署
- Qwen3.6-27B:开源稠密,270 亿参数,性能天花板最高的开源选项,适合有一定算力的团队本地部署
三个模型覆盖了从云端 API 到本地重度部署到边缘轻量部署的完整光谱。而且它们共享同一套多模态架构和思考/非思考模式的设计,开发者在不同规格之间切换的迁移成本很低。
值得一提的是,上周刚发布的 Qwen3.6-35B-A3B 已经展现了 MoE 架构在极端效率上的潜力——30 亿激活参数就能在编程基准上接近甚至超越 270 亿稠密模型(指前代 Qwen3.5-27B)。而现在 Qwen3.6-27B 又把稠密模型的上限往上推了一大截。两条技术路线在同一个版本周期内互相追赶,这对开源社区来说是好事。
实际部署:怎么用起来
模型权重已经在 Hugging Face 和 ModelScope 上放出来了,开发者可以直接下载。
几个关键的部署信息:
第一,支持思考和非思考两种模式。思考模式下模型会展开完整的推理链,适合复杂的编程和推理任务;非思考模式更快更直接,适合简单的问答和补全。这个设计在 Qwen3 时代就有了,到 3.6 已经比较成熟。
第二,百炼平台即将支持 API 调用,并且保留了 preserve_thinking 功能。这个功能允许在多轮对话中保留前序轮次的思维链内容,对于智能体任务来说非常关键——你的 agent 在第三步做决策时,能看到第一步和第二步的完整推理过程,而不是只看到最终输出。
第三,也是对开发者最实用的一点:Qwen3.6-27B 可以直接集成到主流的编程助手工具中。官方明确提到了三个:
- OpenClaw(原名 Moltbot / Clawdbot):可自托管的开源 AI 编码智能体,连接百炼即可在终端中获得完整的智能体编码体验
- Claude Code:通过 Qwen API 对 Anthropic API 协议的兼容支持
- Qwen Code:专为终端设计的开源 AI 智能体,针对 Qwen 系列深度优化
这意味着你不需要自己搭建复杂的工具链,直接在现有的开发工作流中替换底层模型就行。特别是 Claude Code 的兼容——很多开发者已经习惯了 Claude Code 的交互方式,现在可以无缝切换到 Qwen3.6-27B 作为后端,既省了 API 费用,又能在本地跑,数据不出域。
如果你想通过 API 快速体验,阿里云百炼平台上线后可以直接调用。对于习惯用统一接口管理多个模型的开发者,OpenAI Hub 等聚合平台通常也会在模型上线后较快跟进支持,一个 Key 就能切换测试不同模型的效果差异。
放在行业里看:开源编程模型的军备竞赛
2025 年下半年以来,编程能力已经成为大模型竞争最激烈的战场。原因很简单——这是当前大模型最容易变现的能力,也是开发者最愿意付费的场景。
Claude 凭借 Sonnet 系列在编程领域建立了强大的口碑,Cursor、Windsurf 等 AI 编程工具的爆发进一步放大了这个需求。OpenAI 的 Codex 和 GPT 系列也在持续强化编程能力。而在开源侧,竞争同样白热化:DeepSeek-Coder 系列、CodeLlama、StarCoder,以及 Qwen 自己的 Coder 系列,都在争夺"最强开源编程模型"的头衔。
但 Qwen3.6-27B 的策略有点不一样。它不是一个专门的 Coder 模型,而是一个通用多模态模型,只是编程能力恰好做到了开源最强。这种"全能型选手在单项上也能打"的路线,对开发者来说更有吸引力——你不需要为编程和通用任务分别部署两个模型。
更重要的是,Qwen3.6-27B 强调的不是"写代码",而是"智能体编程"。两者的区别在于:写代码是给你一个函数签名,让模型补全实现;智能体编程是给你一个模糊的需求描述,让模型自己规划步骤、调用工具、读写文件、运行测试、迭代修复。后者才是 AI 编程真正有生产力价值的形态,也是 SWE-bench 这类基准试图衡量的能力。
从 SWE-bench Verified 77.2 这个分数来看,Qwen3.6-27B 已经进入了一个相当实用的区间。作为参考,这个基准上的人类开发者基线大约在 4.8%(是的,这个基准对人类也很难,因为它要求在不熟悉的代码库中快速定位和修复问题)。77.2% 意味着模型能解决超过四分之三的真实 GitHub issue,这在实际工作中已经是一个非常有用的助手了。
一些值得关注的细节
翻看 Qwen3.6 系列的发布节奏,有几个细节值得开发者留意:
从 4 月 16 日发布 Qwen3.6-35B-A3B 到今天发布 27B,间隔只有 6 天。加上更早的 Qwen3.6-Plus,整个 3.6 系列的发布节奏非常密集。这说明阿里在 Qwen3.6 这一代上做了充分的准备,多个规格的模型是并行训练、分批发布的,而不是一个一个串行迭代。
另一个细节是 Manus 与通义千问的战略合作。今年 3 月,Manus 宣布将基于通义千问系列开源模型,在国产模型和算力平台上实现全部功能。Qwen3.6-27B 这种兼顾性能和部署便利性的模型,很可能就是 Manus 在国内落地的核心底座之一。
还有一点:官方博客提到 Qwen3.6 开源家族"正在持续壮大,敬请关注后续发布"。结合此前 Qwen3.6-Max-Preview 已经在闭源侧亮相,后续大概率还会有更大规格的开源模型(比如 72B 级别)放出来。对于当前就有部署需求的团队,27B 是一个很好的起点;如果你的场景对能力上限要求更高,可以等等看后续的大杯和超大杯。
写在最后
270 亿参数干翻 397 亿参数,稠密模型在编程能力上全面超越 MoE 模型——Qwen3.6-27B 用一种非常直观的方式证明了一件事:在模型架构和训练方法持续进化的今天,参数量越来越不是决定性能的唯一因素。
对于开发者来说,这是一个好消息。它意味着你不需要堆最贵的硬件、跑最大的模型,也能获得第一梯队的智能体编程能力。一张卡,一个模型,编程、推理、多模态全都有了。
开源模型的黄金时代,还在加速到来。
参考来源:
- IT之家:通义千问 Qwen3.6-27B 宣布开源 — 首发报道,包含完整基准测试数据
- IT之家:阿里千问 Qwen3.6-35B-A3B 开源发布 — Qwen3.6 系列前序模型发布详情
- 知乎:Qwen3.6-Plus 重磅发布,编程与智能体能力全面提升 — Qwen3.6 系列整体能力分析
