小米MiMo-V2.5发布:这次真要硬刚顶级模型了

小米发布MiMo-V2.5系列大模型并开启公测,主攻智能体与代码生成场景,宣称可与Claude Opus 4.6、GPT-5.4正面较量,即将全球开源。
距离上次「深夜三连更」才过去一个月,小米的大模型团队又交卷了。
4月22日,小米正式发布 MiMo-V2.5 系列大模型,包括标准版 MiMo-V2.5 和旗舰版 MiMo-V2.5-Pro,目前已在 MiMo 开放平台开启公测,并明确宣布即将全球开源。
这个迭代速度,说实话有点猛。3月19日雷军才刚官宣 V2-Pro、V2-Omni、V2-TTS 三款模型,一个月出头就推到了 V2.5。社区里有人感慨「2-Pro 才发布没多久,现在就来 2.5-Pro 了」——不是错觉,小米的模型发布节奏确实在加速。
但速度快不代表什么,关键是这次 V2.5 到底带来了什么。
小米给自己找了两个最硬的对手
先说最抓眼球的部分。小米在官方介绍中直接点名了两个对手:Claude Opus 4.6 和 GPT-5.4,声称 MiMo-V2.5-Pro 在通用智能体能力、复杂软件工程和长程任务等维度上,已经能与这两个全球顶尖 Agent 模型「正面较量」。
这话说得很大。
社区的反应也很分裂。有人看到跑分数据后觉得「超过 Gemini 了,差距居然不大」,也有人直接泼冷水:「出个跑分就正面硬刚 xxx 了,就正常说个发布新闻我也不会说啥啊。」
说实话,这种质疑完全合理。跑分和实际体验之间的鸿沟,在大模型领域已经是老生常谈了。但小米这次给出的不只是跑分,还有两个相当有说服力的案例。
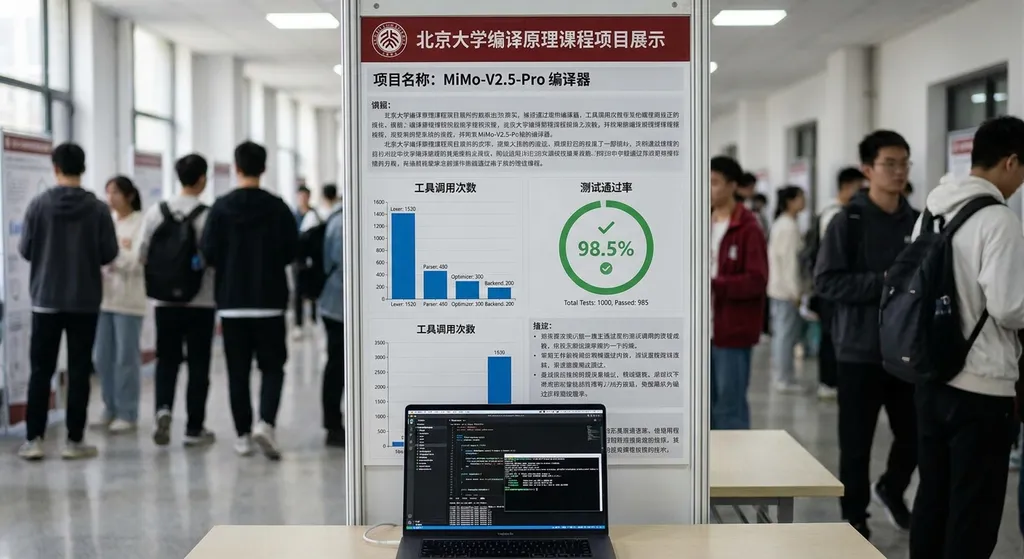
4.3小时写完一个编译器,拿了满分
第一个案例来自北京大学《编译原理》课程项目。
任务要求是用 Rust 从零实现一个完整的 SysY 编译器,涵盖词法分析器、语法分析器、AST 构建、Koopa IR 代码生成、RISC-V 汇编后端,以及性能优化。这是一个正经的本科课程大作业,北大学生通常需要数周时间完成。
MiMo-V2.5-Pro 用了 4.3 小时,经过 672 次工具调用,在隐藏测试集上拿到了 233/233 满分。
这个结果值得拆开来看。
首先,这不是简单的代码补全或者函数生成,而是一个需要深度理解编译原理、具备长程规划能力的系统工程任务。模型需要理解各模块之间的依赖关系,按正确的顺序构建整个编译器 pipeline,还要处理各种边界情况。
其次,672 次工具调用意味着模型在持续地与环境交互——写代码、运行测试、发现问题、修复 bug,这是一个典型的 Agent 工作流。不是一次性生成,而是迭代式地解决问题。
最后,满分。在隐藏测试集上。这说明模型不是在背答案,而是真正理解了任务需求并正确实现了。
一句话需求,交付8000行代码的视频编辑器
第二个案例更贴近实际开发场景。
输入只有一句话:「构建一个视频编辑器 Web 应用」。MiMo-V2.5-Pro 自主工作了 11.5 小时,经过 1,868 次工具调用,最终交付了一款可运行的 Web 应用,具备多轨道时间线、片段裁剪、交叉淡化、音频混合以及导出流程等功能。总代码量 8,192 行。
把这个数字放到语境里:一个中级前端开发者,从零开始写一个功能类似的视频编辑器,保守估计需要两到三周。而且这还不算需求分析、技术选型、架构设计的时间。
当然,我们不知道这 8,192 行代码的质量如何,是否有冗余,是否经得起生产环境的考验。但作为一个从单句需求到可运行应用的端到端演示,这个结果已经相当能打了。
这两个案例共同指向一个方向:MiMo-V2.5 系列的核心卖点不是聊天,不是写作,而是作为一个能自主完成复杂工程任务的 Agent。
从 V2 到 V2.5,到底升级了什么
回顾一下上一代的基础。3月发布的 MiMo-V2-Pro 拥有超过 1T 的总参数量(42B 激活参数),采用混合注意力架构,支持 1M 超长上下文。当时的定位就已经是「面向高强度 Agent 工作场景的旗舰基座模型」。
从 V2 到 V2.5,小米官方用了「全方位跃升」这个说法。结合公开信息来看,升级主要集中在几个方面:
-
智能体能力的系统性增强。不只是单次工具调用更准确,而是在长程任务中的规划、执行、纠错能力都有提升。672 次和 1,868 次工具调用能跑通,说明模型在长序列交互中的稳定性有了质的改善。
-
代码生成能力的大幅提升。从编译器满分案例来看,模型对系统级编程语言(Rust)和复杂工程架构的理解已经到了相当深的程度。
-
推理速度的优化。社区用户实测,Pro 版本每秒约 100 token,标准版每秒约 150 token。这个速度在同级别模型中算快的,尤其考虑到 Agent 场景下模型需要频繁调用,推理速度直接影响任务完成时间。
速度这件事,比你想的更重要
展开说说推理速度。
在普通对话场景下,每秒 100 token 和每秒 50 token 的体感差异不大,用户可能就是觉得「快了一点」。但在 Agent 场景下,这个差异会被成百上千次的工具调用放大。
简单算一笔账:假设每次工具调用平均涉及 500 token 的生成,672 次调用就是 336,000 token。每秒 100 token 需要约 56 分钟的纯生成时间,每秒 50 token 就需要 112 分钟。再加上工具执行、结果解析等开销,速度差异直接决定了一个编译器项目是 4 小时完成还是 7、8 小时完成。
对于开发者来说,这不是「快了一点」的问题,而是「能不能在一个工作日内跑完」的问题。
开源这张牌,小米打得越来越熟
小米这次明确表示 V2.5 系列「即将全球开源」。
从 MiMo 系列的历史来看,小米在开源这件事上一直比较积极。V1 系列开源后在社区获得了不错的反响,V2 系列延续了这个策略。现在 V2.5 继续开源,说明小米已经把开源作为 MiMo 大模型的核心战略之一。
这个策略的逻辑很清晰:小米的大模型最终要服务于「人车家」生态,需要大量开发者基于 MiMo 构建应用。开源是获取开发者生态最高效的方式,没有之一。
对于开发者来说,一个即将开源的、主攻 Agent 和代码生成的大模型,意味着可以在本地部署、可以微调、可以集成到自己的工作流中。这比调用闭源 API 的灵活性高出一个量级。
当然,开源的具体形式还有待观察——是完全开放权重,还是有使用限制?是否包含训练代码和数据集信息?这些细节会直接影响开源的实际价值。
Token Plan 更新:学 Sam Altman 做大善人
伴随模型发布,小米还更新了 MiMo 开放平台的 Token Plan:
- 夜间专属优惠速率:0.8x 消耗,相当于打了八折
- 连续包月折扣上线,包年 88 折
- 上线惊喜福利:老用户 Credits 全量重置
社区有人调侃「学 Sam 大善人,给老用户的 plan 限额全重置了」。Credits 全量重置确实是个不错的拉新促活手段,尤其对于之前已经用完额度、正在观望的开发者来说,相当于免费给了一次深度体验新模型的机会。
不过也有用户吐槽「小米的套餐真贵啊」。定价这件事见仁见智,但考虑到 MiMo 即将开源,对价格敏感的开发者完全可以等开源后自行部署。API 服务更多是为那些不想折腾基础设施、追求开箱即用的团队准备的。
放到行业里看:小米的位置在哪
把视角拉远一点。
2026 年的大模型竞争格局已经和一年前完全不同。OpenAI 推进到了 GPT-5.4,Anthropic 的 Claude Opus 迭代到了 4.6,Google 的 Gemini 也在持续更新。国内这边,DeepSeek、Qwen、GLM 各有各的打法。
小米选择的切入角度很明确:Agent 和代码生成。
这个选择有几层考量。第一,通用对话能力的竞争已经白热化,后来者很难在这个维度上建立差异化优势。第二,Agent 能力是当前大模型应用落地最有价值的方向之一,尤其在软件开发领域,能自主完成复杂任务的模型有巨大的商业潜力。第三,小米自身的「人车家」生态天然需要强大的 Agent 能力——智能家居控制、车机交互、跨设备协作,这些场景本质上都是 Agent 任务。
从社区反馈来看,MiMo 系列的实际体验也在快速改善。有用户提到「用了下感觉其实蛮不错的,对话都很中国」,这说明模型在中文理解和文化适配上做了不少功夫。对于国内开发者来说,一个中文体验好、推理速度快、即将开源的 Agent 模型,确实有它的吸引力。
冷静看几个问题
当然,也不能只看好的一面。
第一,「正面较量」不等于「超越」。小米的措辞是「已能与 Claude Opus 4.6、GPT-5.4 正面较量」,这是一个相当模糊的表述。在哪些具体 benchmark 上较量?差距有多大?是全面持平还是部分场景接近?这些信息目前都不够透明。
第二,案例的代表性问题。编译器项目和视频编辑器都是相对结构化的任务,有明确的输入输出和验证标准。在更模糊、更开放的实际开发场景中,模型的表现是否同样出色,还需要更多用户的实测反馈。
第三,开源时间表不明确。「即将开源」到底是一周还是一个月?对于等着用开源权重的开发者来说,这个不确定性多少有些影响决策。
第四,生态成熟度。MiMo 开放平台相比 OpenAI、Anthropic 的开发者生态还很年轻,文档、SDK、社区支持等方面能否跟上模型迭代的速度,是一个持续的挑战。
雷军的 160 亿,开始见响了
3月发布 V2 系列时,雷军透露小米今年在 AI 研发与资本投入将超过 160 亿。一个月后 V2.5 就来了,这个投入产出的节奏说明小米的大模型团队已经进入了一个高效的迭代循环。
从更大的图景来看,小米做大模型的逻辑和纯 AI 公司不同。OpenAI、Anthropic 需要靠模型本身赚钱,小米的大模型最终是要嵌入到手机、汽车、智能家居的整个生态中去。这意味着小米可以在模型层面更激进地开源和降价,因为它的商业回报不在模型本身,而在生态。
这也是为什么小米敢在 V2.5 上直接点名 Claude Opus 4.6 和 GPT-5.4。即使在绝对性能上还有差距,只要在特定场景(Agent、代码生成)上足够能打,再加上开源和价格优势,就能在开发者市场上切下一块蛋糕。
对于开发者来说,MiMo-V2.5 值得关注的理由很简单:一个主攻 Agent 场景、推理速度快、即将开源的国产大模型,在当前的选择池里确实是一个有差异化的选项。等开源权重放出后,跑几个自己业务场景的测试,比看任何跑分都有用。
如果你已经在用 OpenAI Hub 这类 API 聚合平台,后续 MiMo 系列上线的话,切换试用的成本也很低——改个模型名就行。
至于小米能不能真的在大模型赛道上站稳,V2.5 还只是一个阶段性答案。但至少从迭代速度和技术方向来看,这支团队是认真的。
参考来源:
- Xiaomi MiMo-V2.5 系列大模型开启公测并即将开源 - Linux.do 讨论 — 社区对 V2.5 发布的详细讨论,包含官方案例和跑分信息
- 小米悄悄发布了新模型 V2.5 和 V2.5-Pro - Linux.do 讨论 — 社区用户实测推理速度和使用体验反馈
- Xiaomi MiMo-V2.5 系列模型开启公测并即将全球开源 - Linux.do 公告 — MiMo 开放平台官方公测公告及 Token Plan 更新详情
- 小米发布了新模型,而且给 plan 重置了用量 - Linux.do 讨论 — 关于老用户 Credits 重置福利的讨论
- 关于小米最新发布的 MiMo 大模型 - 知乎专栏 — MiMo 系列在智能体框架中的能力分析
