OpenAI 开源隐私过滤小模型,1.5 亿参数跑在浏览器里

OpenAI 发布开源隐私过滤模型 privacy-filter,仅 1.5 亿参数、5000 万活跃参数,支持 128K 上下文,采用 Apache 2.0 许可,可在浏览器和笔记本上运行,为开发者提供轻量级 PII 检测方案。
OpenAI 这次没发大模型,发了个小的。
2026 年 4 月,OpenAI 在 Hugging Face 上开源了一个名为 privacy-filter 的隐私过滤模型。总参数量 1.5 亿,活跃参数仅 5000 万,Apache 2.0 许可,能在浏览器里跑。这大概是 OpenAI 迄今为止发布的最"不起眼"的模型——但它解决的问题一点都不小。
一个被低估的刚需
做过任何涉及用户数据的 AI 应用的开发者都知道,隐私信息过滤是个绕不开的坑。
你的 RAG 管道里混进了用户的手机号、身份证号、邮箱地址,怎么办?你的训练数据里有客户的真实姓名和住址,清洗了吗?你的日志系统把用户的银行卡号明文打进去了,合规团队知道吗?
传统做法是写正则表达式。手机号、邮箱这些格式固定的还好说,但碰到"我住在朝阳区某某小区 3 号楼 1502"这种自然语言描述的地址,正则就歇菜了。更别提跨语言场景——中文地址、日文姓名、阿拉伯语电话号码,每种都要单独写规则,维护成本指数级上升。
有人用 NER(命名实体识别)模型来做,效果好一些,但通用 NER 模型的标签体系不是为隐私场景设计的,"人名"和"需要脱敏的人名"之间还有一道鸿沟。也有人直接调 GPT-4 来做 PII 检测,效果确实好,但你愿意为每条日志花几分钱调一次 API 吗?在高吞吐场景下,这个成本会让财务部门找你谈话。
OpenAI 的 privacy-filter 就是冲着这个缺口来的。
架构:不是生成式,是分类器
这个模型最有意思的地方在于它的架构选择。
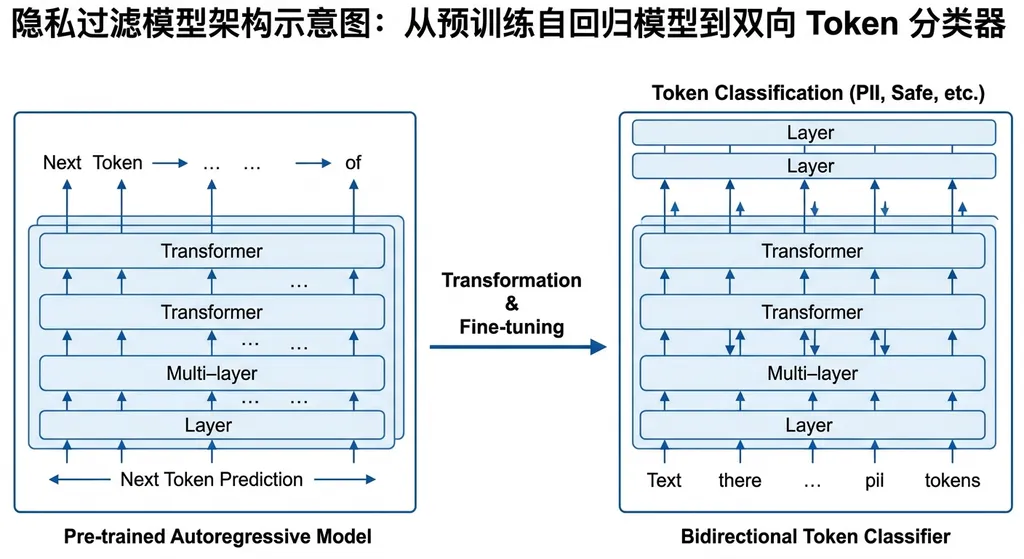
按照模型卡的描述,privacy-filter 的训练分两步走:
第一步,基于 GPT-OSS 架构做预训练自回归,得到一个结构类似但体积更小的 checkpoint。这一步和常规语言模型训练没什么区别,目的是让模型学会"理解语言"。
第二步才是关键——把这个自回归模型转换成双向 token 分类器,用监督分类损失做后训练。模型不再逐个生成 token,而是在一次前向传递中对输入序列的每个 token 打标签,然后通过约束维特比(Viterbi)算法解码出连贯的标注结果。
这个设计思路值得展开说说。
自回归模型(比如 GPT 系列)是一个 token 一个 token 往外蹦的,速度受限于序列长度。但 PII 检测本质上是个序列标注任务——给你一段文本,告诉我哪些片段是手机号、哪些是地址、哪些是姓名。这跟翻译、写作完全不同,不需要"生成"任何东西。
所以 OpenAI 做了一个很务实的选择:用自回归预训练来获取语言理解能力,然后把模型"掰"成双向分类器来做推理。双向意味着模型在判断某个 token 时能同时看到它前面和后面的内容,这对实体识别至关重要。维特比解码则保证了输出的标注序列是全局最优的,不会出现"B-PHONE 后面直接跟 B-ADDRESS"这种不合法的标签转移。
简单类比:这就像你先培养一个人的阅读理解能力,然后让他去做阅卷老师——他不需要自己写文章,只需要快速准确地在试卷上画圈标记。
8 个输出类别
模型的标签分类法包含 8 个输出类别。虽然模型卡没有逐一列出所有类别的具体名称,但从隐私过滤的通用实践来看,大概率覆盖了以下几类核心 PII:
- 人名(Person Name)
- 电话号码(Phone Number)
- 电子邮箱(Email Address)
- 物理地址(Physical Address)
- 身份证件号(ID Number)
- 金融账户信息(Financial Account)
- 日期/出生日期(Date/DOB)
- 其他敏感信息(Other Sensitive)
8 个类别不算多,但对于大多数合规场景来说够用了。而且模型支持微调,如果你的业务场景需要识别特定类型的敏感信息(比如医疗记录中的病历号、保险单号),可以在这个基础上加训。
真正的杀手锏:小、快、能本地跑
说实话,如果 privacy-filter 是个 7B 甚至 3B 的模型,它的吸引力会大打折扣。市面上能做 NER 和 PII 检测的开源模型不少,GLiNER、Universal NER 都是不错的选择。
但 1.5 亿总参数、5000 万活跃参数,这个量级就完全不一样了。
做个对比:
| 模型 | 参数量 | 能否浏览器运行 | 上下文长度 | 许可证 | |------|--------|----------------|------------|--------| | privacy-filter | 150M(50M 活跃) | 能 | 128K | Apache 2.0 | | GLiNER-large | 400M+ | 勉强 | 512-1024 | Apache 2.0 | | GPT-4o(API 调用) | 未公开 | 否(云端) | 128K | 商业 API | | spaCy NER | ~15M | 能 | 无限制 | MIT |
spaCy 更小,但它是基于规则+统计的传统 NLP,对复杂语境下的 PII 识别能力有限。GLiNER 效果好,但参数量是 privacy-filter 的好几倍,浏览器端部署不现实。GPT-4o 效果最好,但成本和延迟都不适合高吞吐场景。
privacy-filter 卡在了一个很精准的生态位上:比传统 NLP 工具聪明,比大模型便宜快速,而且小到可以塞进浏览器。
128K 的上下文窗口也值得一提。模型卡特别强调了"无分块处理长文本"——这意味着你可以把一整篇长文档丢进去,不用自己做 chunking 和结果拼接。对于处理合同、报告、邮件这类长文本的场景,这省了不少工程量。
运行时控制:精度和召回的权衡
做过信息抽取的人都知道,精度(Precision)和召回(Recall)是一对永恒的矛盾。
在隐私过滤场景下,这个矛盾尤其尖锐:
- 高召回意味着"宁可错杀不可放过",尽可能多地标记潜在 PII,但可能把"张三丰"这种武侠人物也标成需要脱敏的人名
- 高精度意味着"只标确定的",误报少但可能漏掉一些隐蔽的隐私信息
不同业务场景的需求完全不同。金融合规可能要求极高召回——漏掉一个身份证号就是事故;而内容展示场景可能更在意精度——总不能把文章里提到的公众人物名字全打码吧。
privacy-filter 提供了预设操作点(operating points)来配置这个权衡,同时还能控制检测到的跨度长度。这个设计很实用,开发者不需要自己去调阈值、做后处理,直接选一个预设就行。
放在 OpenAI 开源战略里看
这个模型不是孤立发布的。
回顾 OpenAI 最近几个月的动作,你会发现一条清晰的开源安全工具链正在成型:
- gpt-oss:OpenAI 的开源基座模型系列,privacy-filter 的架构就脱胎于此
- gpt-oss-safeguard:开源的安全推理模型,专门做内容安全分类,支持自定义策略,能输出完整的 Chain-of-Thought 推理过程
- privacy-filter:开源的隐私过滤模型,专注 PII 检测
- 青少年安全策略:配合 gpt-oss-safeguard 使用的提示词格式安全策略,与 Common Sense Media 等机构合作制定
看出来了吗?OpenAI 在构建一套完整的开源安全基础设施。
gpt-oss-safeguard 负责内容层面的安全审查——这段话有没有暴力、色情、仇恨言论?privacy-filter 负责数据层面的隐私保护——这段文本里有没有需要脱敏的个人信息?两者互补,覆盖了 AI 应用安全的两个核心维度。
这个战略意图很明显:OpenAI 想成为 AI 安全领域的"基础设施提供商"。不只是卖 API,还要定义安全标准、提供安全工具、建立安全生态。当你的整个安全栈都建立在 OpenAI 的开源工具上时,你对 OpenAI 生态的依赖就不仅仅是一个 API Key 的事了。
这一招,Meta 在 Llama 上玩过,Google 在 Android 上玩过。开源不是慈善,是生态战略。
实际使用场景
说几个 privacy-filter 最可能落地的场景:
第一,RAG 管道的预处理层。在文档被切片、向量化之前,先过一遍 privacy-filter,把 PII 标记出来。可以选择直接脱敏(替换为占位符),也可以打标签后在检索时做过滤。这比在最终输出端做过滤要可靠得多——源头治理永远优于末端拦截。
第二,日志和监控系统。线上系统的日志里经常不小心混入用户隐私信息,尤其是在调试阶段。在日志写入前加一层 privacy-filter,自动检测并脱敏,能有效降低数据泄露风险。模型够小,延迟够低,不会成为日志管道的瓶颈。
第三,客户端侧的隐私保护。这是 privacy-filter 最独特的应用场景。因为模型能在浏览器里运行,你可以在用户输入发送到服务器之前就做一次本地 PII 检测,提醒用户"你即将发送的内容包含手机号,是否继续?"。数据不出端,隐私保护做到了极致。
第四,训练数据清洗。大模型训练前的数据清洗是个苦活,PII 过滤是其中重要一环。privacy-filter 的 128K 上下文和高吞吐特性,让它很适合批量处理大规模语料。
第五,合规审计。GDPR、CCPA、中国的《个人信息保护法》都对 PII 处理有严格要求。privacy-filter 可以作为自动化审计工具,定期扫描数据库和文档,生成 PII 分布报告。
局限性和需要注意的地方
当然,这个模型不是万能的。
首先,8 个类别的覆盖范围有限。如果你的场景涉及特殊类型的敏感信息(比如生物特征数据、基因信息、宗教信仰),需要自己微调。好在模型支持微调,Apache 2.0 许可也没有限制。
其次,1.5 亿参数的模型在复杂语境下的判断能力肯定不如大模型。比如"小明在论文里引用了张三的研究"——这里的"张三"是需要脱敏的真实人名,还是学术引用中的公开信息?这种需要深层语义理解的判断,小模型可能力不从心。
第三,多语言能力存疑。模型卡没有明确说明支持哪些语言。考虑到 GPT-OSS 的训练数据以英文为主,privacy-filter 在中文、日文等语言上的表现可能需要额外验证。如果你的场景主要是中文,建议先做一轮评测再决定是否采用。
第四,维特比解码虽然保证了全局最优,但也意味着推理时需要在整个序列上做动态规划。对于 128K 这种超长序列,解码阶段的计算开销不可忽视。实际部署时需要关注这部分的延迟。
跟竞品比怎么样
目前市面上做 PII 检测的工具大致分三类:
基于规则的:Microsoft Presidio 是代表。优点是可解释性强、速度快,缺点是对自然语言描述的 PII 识别能力差,维护成本高。
基于传统 NLP 的:spaCy + 自定义 NER 管道。灵活性好,但需要大量标注数据和调参经验。
基于大模型的:直接调 GPT-4、Claude 等。效果最好,但成本高、延迟大、数据需要出端。
privacy-filter 开辟了第四条路:用大模型的训练方法论(预训练+后训练),做一个专用的小模型。它继承了大模型对语言的理解能力,但推理成本和部署门槛降到了传统 NLP 工具的水平。
如果非要给个判断:对于大多数需要在生产环境中做 PII 检测的团队来说,privacy-filter 很可能会成为首选方案——至少是首选的候选方案之一。它在效果、成本、部署灵活性之间找到了一个很好的平衡点。
但如果你的场景对准确率要求极高(比如金融合规),建议把 privacy-filter 作为第一层快速过滤,再用大模型对标记出的片段做二次确认。两层方案的总成本仍然远低于全量调用大模型。
对开发者意味着什么
隐私保护正在从"可选项"变成"必选项"。
全球范围内,数据隐私法规越来越严。欧盟的 GDPR 罚单动辄上亿欧元,中国的《个人信息保护法》也在持续加强执法力度。对于 AI 应用开发者来说,"我的模型/管道里有没有泄露用户隐私"不再是一个可以事后补救的问题。
OpenAI 开源 privacy-filter,某种程度上是在降低整个行业的合规门槛。以前你要么花大价钱买商业 PII 检测服务,要么自己从头训一个模型,要么硬着头皮写正则。现在有了一个免费、开源、效果不错的选择。
对于正在构建 AI 应用的团队,我的建议是:
- 尽快在你的数据管道中加入 PII 检测环节,不管用什么工具
- 评估 privacy-filter 在你的具体场景(尤其是你的语言和数据类型)上的表现
- 如果效果不够好,基于 privacy-filter 做微调,而不是从头训练
- 考虑多层防护策略,不要把所有赌注押在单一工具上
隐私过滤这件事,做了不一定有人夸你,但不做迟早会出事。OpenAI 给了你一个成本极低的起点,剩下的就看你自己了。
如果你已经在用 OpenAI Hub 这类 API 聚合平台调用各种模型,那在调用链路中嵌入一层本地的 privacy-filter 做预处理,是一个成本几乎为零但收益显著的安全加固手段。数据先在本地过一遍,脱敏后再发到云端,心里踏实得多。
参考来源:
- openai/privacy-filter 模型卡 - Hugging Face — OpenAI 官方发布的隐私过滤模型页面,包含架构细节和使用说明
- openai/privacy-filter 开源隐私过滤器小模型讨论 - Linux.do — 社区对该模型的讨论和中文解读
