腾讯开源混元Hy3:295B参数的快慢思考MoE

腾讯今日发布并开源混元Hy3 preview,295B总参数、21B激活参数的混合专家模型,支持256K上下文,融合快慢思考能力,在推理、代码、智能体等维度全面升级,API定价激进。
腾讯今天把混元系列迄今最大的一张牌摊到了桌面上。
4月23日,腾讯正式发布并开源混元 Hy3 preview 语言模型——一个总参数 295B、激活参数 21B 的混合专家(MoE)架构模型,最大支持 256K 上下文长度,且原生融合了快思考与慢思考两种推理模式。
这不是一次常规的版本迭代。按照官方的说法,今年 2 月腾讯混元团队对预训练和强化学习基础设施做了一次"重建",Hy3 preview 是重建后训练出的第一个模型。换句话说,这是腾讯在大模型赛道上的一次重新出发。
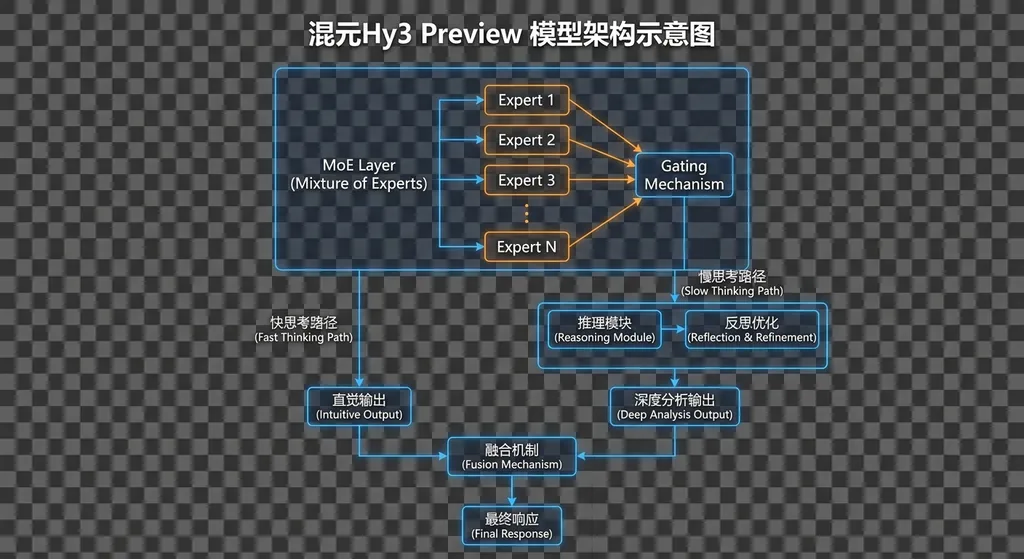
295B 总参、21B 激活:MoE 路线的又一个注脚
先看硬参数。295B 总参数,21B 激活参数——这意味着 Hy3 preview 的稀疏率大约在 93% 左右。每次推理时,模型只激活约 7% 的参数,剩下的专家模块"待命"。
这个设计思路并不新鲜。从 Mixtral 到 DeepSeek-V3,再到 Qwen3,MoE 已经成为当下大模型扩参数的主流路径。逻辑很简单:你想要一个"懂得多"的模型,但又不想每次推理都把所有参数跑一遍——MoE 就是这个矛盾的折中解。总参数决定了模型的知识容量上限,激活参数决定了单次推理的计算成本。
拿几个同期选手横向比一下:
| 模型 | 总参数 | 激活参数 | 最大上下文 | 架构 | |------|--------|----------|------------|------| | 混元 Hy3 preview | 295B | 21B | 256K | MoE | | DeepSeek-V3 | 671B | 37B | 128K | MoE | | Qwen3-235B | 235B | 22B | 128K | MoE | | Llama 4 Maverick | 400B | 17B | 1M | MoE |
Hy3 preview 的总参数规模介于 Qwen3-235B 和 Llama 4 Maverick 之间,激活参数与 Qwen3 接近,但上下文长度拉到了 256K,是 DeepSeek-V3 和 Qwen3 基础版的两倍。
256K 上下文意味着什么?大约等于一本 20 万字的中文小说,或者一个中型代码仓库的核心模块。对于需要处理长文档分析、大规模代码理解、多轮复杂对话的场景来说,这个窗口长度已经够用了。当然,Llama 4 Maverick 号称支持 1M,但实际可用的有效上下文长度和标称值之间往往存在不小的差距,这一点业内都心知肚明。
值得注意的是,Hy3 preview 目前还是 preview 状态。这通常意味着模型还在持续优化中,正式版可能会在参数效率、长上下文表现等方面进一步提升。腾讯选择在这个阶段就开源,一方面是抢时间窗口,另一方面也是想借助社区反馈加速迭代——这在当下的开源模型竞争中已经是标准操作了。
快慢思考融合:不是所有问题都值得"深度思考"
如果说 MoE 架构是 Hy3 preview 的骨架,那快慢思考融合就是它最想讲的故事。
所谓"快思考"和"慢思考",借用的是丹尼尔·卡尼曼在《思考,快与慢》中的经典框架。映射到大模型上:
- 快思考(System 1):直接给出答案,不展开推理链。适合简单问答、日常对话、格式化输出等场景。速度快,token 消耗少。
- 慢思考(System 2):展开完整的思维链(Chain-of-Thought),一步步推导。适合数学证明、复杂代码调试、多步逻辑推理等场景。质量高,但 token 消耗大。
过去一年,"思考模型"是行业热词。OpenAI 的 o 系列、DeepSeek-R1、Qwen3 的 thinking 模式,都在往这个方向走。但问题也很明显:如果所有请求都走慢思考,推理成本会飙升,而且很多简单问题根本不需要那么长的思维链。你问模型"今天星期几",它先花 500 个 token 自我推理一番,这不是智能,是浪费。
快慢思考融合要解决的就是这个问题:让模型自己判断什么时候该"想一想",什么时候该"脱口而出"。
Qwen3 在今年早些时候已经做了类似的尝试,通过 enable_thinking 参数让用户手动切换思考模式。但这本质上还是把决策权交给了调用方。Hy3 preview 的做法更进一步——根据官方描述,模型能够根据问题复杂度自适应地选择推理深度。
这个能力如果真的做到位了,对实际部署的意义很大。想象一个客服场景:用户问"怎么退款",快思考直接回答流程;用户问"我买了 A 产品但收到了 B 产品,而且 B 产品有质量问题,我想退款并且要求赔偿",慢思考介入,分析多个条件后给出结构化回复。同一个模型、同一个 API,自动适配不同复杂度的请求,这才是生产环境真正需要的东西。
当然,"自适应"说起来容易做起来难。模型如何判断一个问题的复杂度?判断错了怎么办?简单问题误触发慢思考只是浪费 token,但复杂问题误走快思考可能直接给出错误答案。这个平衡点的把控,需要看实际使用中的表现。preview 阶段,保持观察比下结论更重要。
基础设施重建:腾讯在补什么课?
官方通稿里有一句话值得多看两眼:"今年 2 月,腾讯混元重建了预训练和强化学习的基础设施。"
"重建"这个词的分量不轻。它意味着之前的基础设施存在足够大的问题,以至于修修补补已经不够用了,必须推倒重来。
腾讯同时提出了模型追求实用性的三个原则:
- 能力体系化——不追求单项跑分冠军,而是综合能力均衡
- 评测真实性——减少对 benchmark 的过拟合,关注真实场景表现
- 性价比追求——在性能和成本之间找到最优解
这三条原则读起来像是在"纠偏"。过去两年,国内大模型竞赛中有一个公开的秘密:不少模型在公开 benchmark 上的分数很漂亮,但实际使用体验和跑分之间存在明显落差。原因很多——针对测试集做优化、评测维度单一、忽视长尾场景等等。腾讯混元之前的版本也没能完全避免这些问题。
现在明确提出"评测真实性",某种程度上是在承认过去的路径有偏差,同时也是在向开发者社区释放信号:我们这次是认真的,不玩跑分游戏了。
至于这个信号能不能兑现,还是要看 Hy3 preview 在真实任务上的表现。好在模型已经开源,社区很快就会给出独立评测。
定价:一场明牌的价格战
来看 API 定价,这可能是 Hy3 preview 发布中最"卷"的部分。
基础 API 价格按输入长度分三档:
| 输入分桶 | 输入价格(元/百万Tokens) | 输出价格(元/百万Tokens) | 缓存命中价格(元/百万Tokens) | |----------|--------------------------|--------------------------|-----------------------------| | 0~16K | 1.2 | 4 | 0.4 | | 16~32K | 1.6 | 6.4 | 0.6 | | 32~256K | 2 | 8 | 0.8 |
分桶定价的设计很务实。大部分 API 调用的输入长度集中在 16K 以内,这一档给了最低价。只有真正用到长上下文的请求才会触发更高的价格,避免了"为用不到的能力买单"的问题。
缓存命中价格更值得关注——0.4 元/百万 Tokens 的输入价格,相当于基础价的三分之一。对于有大量重复前缀(比如系统 prompt、固定的 few-shot 示例)的生产场景来说,这个缓存折扣能显著降低成本。
更激进的是 Token Plan 套餐:
| 套餐 | 月费 | 单价(元/百万Tokens) | Tokens 额度(百万) | |------|------|----------------------|--------------------| | Lite | 28元 | 0.80 | 35 | | Standard | 78元 | 0.78 | 100 | | Pro | 238元 | 0.74 | 320 | | Max | 468元 | 0.72 | 650 |
Max 套餐的单价做到了 0.72 元/百万 Tokens。这个价格是什么概念?对比 DeepSeek-V3 的官方 API 定价(输入 1 元/百万 Tokens、输出 2 元/百万 Tokens),Hy3 preview 的套餐价在输入侧已经更便宜了。
28 元/月的 Lite 套餐显然是冲着个人开发者来的。一杯奶茶的钱,拿到 3500 万 Tokens 的额度,足够个人项目和学习实验用了。腾讯的意图很明确:先把开发者拉进来,用起来,形成习惯,后面再考虑商业化的事。
这也是当下国内大模型 API 市场的缩影——价格战已经打到了地板附近。对开发者来说这当然是好事,但对模型厂商来说,如何在极低的 API 单价下维持可持续的商业模型,是一个迟早要回答的问题。
生态铺开:从腾讯全家桶到开源智能体
Hy3 preview 的落地节奏很快。发布当天,模型已经在腾讯的一系列产品中上线或正在上线:
- 已上线:元宝、CodeBuddy、WorkBuddy、QQ、ima、QQ浏览器、腾讯文档、腾讯乐享
- 陆续上线中:微信公众号、腾讯新闻、腾讯自选股、和平精英、腾讯客服
这个产品覆盖面几乎涵盖了腾讯的所有核心业务线——社交、办公、搜索、游戏、金融、客服。大模型从"实验室产品"到"全业务线渗透",腾讯的内部推进速度不慢。
更有意思的是开源智能体生态的接入。官方提到 Hy3 preview 已支持 OpenClaw、OpenCode、KiloCode 等流行的开源智能体产品。这说明腾讯不只是把模型开源了事,而是在主动适配社区中已经跑起来的智能体框架。
对于做 AI Agent 开发的团队来说,这是一个实际的利好。一个 295B 参数、支持 256K 上下文、具备快慢思考能力的开源模型,天然适合作为智能体的"大脑"——长上下文能装下更多的工具描述和历史记录,快慢思考能在简单工具调用和复杂规划之间灵活切换。
开源的意义:不只是放出权重
在当下的大模型竞争格局中,"开源"本身已经成为一种竞争策略。Meta 用 Llama 系列搅动了整个行业,DeepSeek 靠开源迅速建立了开发者口碑,Qwen 系列则在中文开源模型中占据了重要位置。
腾讯选择开源 Hy3 preview,战略意图很清晰:
第一,抢占开发者心智。在 MoE 架构的开源模型中,DeepSeek-V3 和 Qwen3 已经建立了先发优势。Hy3 preview 要想在这个赛道上获得一席之地,必须尽早让开发者用上、评上、讨论起来。
第二,借助社区力量加速迭代。preview 状态意味着模型还有优化空间,社区的真实反馈比内部测试更有价值。
第三,为腾讯云的 API 服务导流。开源模型本身不赚钱,但围绕模型的云服务、定制化部署、企业级支持才是商业化的落脚点。Token Plan 套餐的设计就是这个逻辑的体现。
对于开发者来说,多一个高质量的开源选择永远不是坏事。如果你正在做模型选型,Hy3 preview 值得加入你的评估列表——尤其是如果你的场景对长上下文和推理能力有较高要求的话。模型开源后,通过 OpenAI Hub 等聚合平台也能方便地进行多模型对比测试,快速验证在自己业务场景下的实际表现。
冷静看:preview 阶段的几个待验证问题
最后,泼几点冷水——不是唱衰,而是作为开发者在做技术决策时应该关注的点:
-
快慢思考的自适应准确率。这是 Hy3 preview 最核心的卖点,也是最需要验证的能力。建议等社区的独立评测出来后再做判断,尤其关注在边界 case 上的表现。
-
长上下文的实际有效性。256K 是标称值,但在接近上限时模型的注意力分配是否均匀、是否存在"中间遗忘"问题,需要针对性测试。这个问题在几乎所有长上下文模型上都存在,Hy3 preview 大概率也不例外。
-
MoE 架构的部署门槛。295B 总参数意味着即使是推理部署,对显存的要求也不低。虽然激活参数只有 21B,但所有专家的权重都需要加载到显存中。个人开发者想本地跑满血版基本不现实,量化版本的性能损失需要关注。
-
preview 到正式版的距离。preview 状态的模型可能存在稳定性、一致性方面的问题。如果是生产环境使用,建议等正式版发布后再做迁移。
写在最后
腾讯混元 Hy3 preview 的发布,是 2025 年国内大模型开源竞赛中的又一个重要节点。295B 参数的 MoE 架构、256K 长上下文、快慢思考融合、激进的 API 定价——每一项单独拿出来都不算惊艳,但组合在一起,构成了一个相当有竞争力的产品方案。
更重要的是腾讯在这次发布中展现出的态度转变:从追求跑分到追求实用性,从闭门造车到拥抱开源生态,从单点突破到全业务线铺开。这些变化比模型本身的参数更值得关注。
至于 Hy3 preview 能不能真正兑现它的承诺,时间和社区会给出答案。模型已经开源,代码已经放出,剩下的就交给每一个愿意动手试试的开发者了。
参考来源:
- 混元迄今最智能的模型:腾讯发布并开源 Hy3 preview 语言模型 - IT之家:Hy3 preview 发布详情、API 定价及产品落地信息
- Qwen3-Next 技术浅析:长上下文+高稀疏MoE+混合注意力 - 知乎:MoE 架构与长上下文扩展的技术趋势分析
- Qwen3混合思考与快慢思考机制解析 - 知乎:快慢思考融合的行业背景与技术路线对比
- Qwen3是如何实现混合推理(快慢思考)的? - 知乎:混合推理模式的具体实现方式参考
