GPT-5.4-Cyber来了:安全AI不再人人可用

OpenAI 推出网络安全专用模型 GPT-5.4-Cyber,具备二进制逆向工程等专属能力,首次采用分级认证体系控制访问权限,标志着高能力 AI 模型从通用开放走向定向管控。
OpenAI 把安全模型单独拎出来了,这次不是加 guardrails
4 月 16 日,OpenAI 正式推出 GPT-5.4-Cyber——一个专门为防御性网络安全场景微调的模型变体。不是在通用模型上多加几条规则,而是从底层重新调过的版本。同步扩展的还有 Trusted Access for Cyber(TAC)计划,开放对象从此前的小范围测试扩大到数千名安全研究员和数百个防御团队。
这件事的信号很明确:头部 AI 厂商已经不再相信"一个模型打天下"的逻辑了。至少在网络安全这个领域,通用模型的能力边界和风险边界都太模糊,必须拆出来单独管。
不是更强的 GPT-5.4,是一个不同的东西
先说清楚 GPT-5.4-Cyber 到底是什么。
它基于 GPT-5.4 基础模型微调而来,但和标准版有本质区别。OpenAI 用了一个很直白的词来描述它的定位:cyber-permissive,也就是"对安全操作更宽容"。
具体来说,标准版 GPT-5.4 在遇到涉及漏洞分析、恶意代码解读、逆向工程等请求时,大概率会拒绝或给出高度阉割的回答。这对普通用户是合理的安全策略,但对安全研究员来说是灾难——你让模型帮你分析一个可疑二进制文件,它告诉你"我无法协助可能涉及恶意软件的请求",这就没法干活了。
GPT-5.4-Cyber 把这个拒绝阈值大幅降低了,同时新增了标准版不具备的专属能力,其中最关键的一项是二进制逆向工程。安全人员可以直接把编译后的二进制文件丢给模型,不需要源码就能分析其中的恶意行为、漏洞和安全缺陷。
这个能力对做恶意软件分析和漏洞研究的人来说,价值非常直接。过去用 IDA Pro、Ghidra 做逆向,门槛高、耗时长,很多中小安全团队根本没有足够的逆向工程师。现在模型能在这个环节提供实质性的辅助,相当于把逆向分析的人力瓶颈往下压了一大截。
谁能用?不是你想用就能用
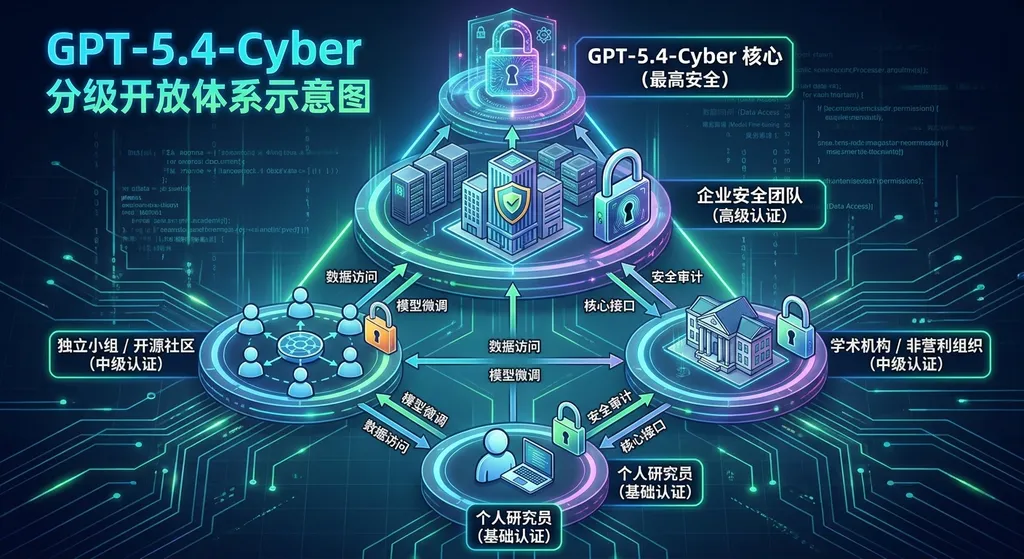
GPT-5.4-Cyber 最值得关注的不是模型本身有多强,而是 OpenAI 围绕它建立的访问控制体系。
TAC 计划在这次升级后引入了分级认证体系。不同等级对应不同的模型能力权限,最高等级才能解锁 GPT-5.4-Cyber 的完整功能。申请路径分两条:
- 个人安全研究员:在 chatgpt.com/cyber 完成身份认证(KYC)
- 企业安全团队:通过 OpenAI 客户代表申请接入
- 已在 TAC 计划中的用户:可单独申请升级到更高权限等级
这套机制的核心逻辑是:用身份验证替代能力限制。
过去 OpenAI 的安全策略是"堵"——在模型输出端加 guardrails,不让它回答危险问题。但这种做法的问题所有安全从业者都清楚:该拦的拦不住(越狱绕过),不该拦的反而被误杀(正当安全研究被拒绝)。
现在换了思路:不限制模型能做什么,而是限制谁能用这个模型。这和现实世界里管控危险物品的逻辑一样——你不会禁止手术刀的存在,但你会要求使用者必须是持证医生。
听起来合理,但问题也很明显:KYC 能防住多少?通过认证的人如果把模型输出转手给攻击者呢?模型能力一旦泄露到未授权场景怎么办?这些问题 OpenAI 目前没有给出令人信服的回答。
一周前 Anthropic 刚秀了肌肉,OpenAI 就跟上了
理解 GPT-5.4-Cyber 发布的时机,需要看两个背景事件。
第一个是 Anthropic 的 Mythos 模型。 就在 GPT-5.4-Cyber 发布前一周,英国人工智能安全研究所公布了一项测试结果:Anthropic 的 Mythos 模型首次成功完成了"TLO"挑战——在模拟企业网络中自主走完 32 步攻击链,从初始侦察一路推进到完全控制目标环境。
32 步,全自主,完整攻击链。这不是"AI 帮你写个钓鱼邮件"的水平,这是 AI 自己当渗透测试员的水平。
这个结果释放的信号非常强烈:AI 的攻击能力已经不是理论上的威胁了,它正在变成现实。对防御薄弱、存在已知漏洞的系统来说,AI 驱动的自动化攻击已经构成实际风险。
Anthropic 的做法是极度保守地开放——Mythos 只面向约 40 家机构。OpenAI 选择了另一条路:更大范围地开放防御能力,用数千人的规模去覆盖。
两家公司的策略差异很有意思。Anthropic 说"这东西太危险了,我们严格控制";OpenAI 说"攻击能力已经在那了,防御能力必须跟上,而且要让更多防御者用得上"。谁对谁错现在下结论太早,但 OpenAI 显然在赌一个判断:防御侧的 AI 普及速度如果跟不上攻击侧,整个生态会更危险。
第二个是 Axios 供应链攻击事件。 4 月 10 日,OpenAI 刚发布了对 Axios 开发者工具供应链攻击的响应报告。从事件响应到发布专用安全模型,间隔不到一周。
这个节奏说明 GPT-5.4-Cyber 的开发早就在进行了,Axios 事件更像是加速了发布决策的催化剂。供应链攻击的频率和隐蔽性都在上升,传统的人工审计根本跟不上节奏,这恰恰是 AI 模型能发挥价值的场景。
CTF 成绩单:从 27% 到 76%
OpenAI 在公告中披露了一组数据,展示其模型在夺旗赛(CTF)基准测试中的成绩变化:
| 时间 | 模型 | CTF 得分 | |------|------|----------| | 2025 年 8 月 | GPT-5 | 27% | | 2025 年 11 月 | GPT-5.1-Codex-Max | 76% | | 2026 年 4 月 | GPT-5.4-Cyber | 未公布具体数字 |
从 27% 到 76%,不到四个月,接近三倍的提升。CTF 比赛涵盖逆向工程、密码学、Web 安全、二进制利用等多个方向,这个成绩的跃升说明 OpenAI 在安全领域的模型能力确实在快速迭代。
OpenAI 还表示,未来所有新版本都将按"可能达到高级网络安全能力"的标准进行规划与评估,纳入其安全准备框架(Preparedness Framework)。这意味着网络安全不再是模型评估的附加项,而是核心维度之一。
Codex Security:从工具到生态
GPT-5.4-Cyber 不是孤立的产品,它是 OpenAI 安全产品线的模型层支撑。
今年早些时候,OpenAI 发布了 Codex Security 的研究预览版,定位是大规模识别和修复代码漏洞的工具。自全面上线以来,Codex Security 已经协助修复了生态系统中超过 3000 个高危和严重安全漏洞。
同时,OpenAI 还在做两件容易被忽略但很关键的事:
- 资助 Linux Foundation 的开源安全项目:不只是卖模型,而是往开源安全基础设施里投钱
- Codex for Open Source:为开源项目提供免费安全扫描,目前已覆盖超过 1000 个项目
把这些拼在一起看,OpenAI 的意图很清楚:不是做一个安全模型卖 API,而是试图构建一个以模型能力为核心的防御者生态。从底层模型(GPT-5.4-Cyber)到应用工具(Codex Security)到社区投入(开源安全资助),三层都在布。
这个布局是否能成,取决于一个关键问题:安全社区是否买账。安全从业者是出了名的谨慎和怀疑,让他们把核心工作流交给一个闭源模型,信任门槛非常高。
对开发者意味着什么
如果你是做安全相关开发的,GPT-5.4-Cyber 的出现有几个直接影响:
-
安全工具链会加速 AI 化。 逆向分析、漏洞扫描、恶意软件检测这些环节,AI 辅助从"锦上添花"变成"标配"。不用 AI 的安全团队在效率上会越来越吃亏。
-
模型选择变得更重要。 通用模型和安全专用模型的能力差距会越来越大。用通用 GPT-5.4 做安全分析和用 GPT-5.4-Cyber 做,体验可能是两个世界。
-
访问权限本身成为资源。 TAC 计划的分级认证意味着,能不能用上最强的安全模型,取决于你的身份和资质。这对独立安全研究员来说可能是个门槛。
更大的趋势是:大模型正在从"通用万能"走向"领域专精"。 安全是第一个明确落地的垂直领域,接下来大概率会看到医疗、法律、金融等方向的专用模型变体。
通过 API 接入 GPT-5.4 系列
对于想在自己的安全工具或工作流中集成 GPT-5.4 能力的开发者,标准版 GPT-5.4 可以通过 API 调用。如果你在国内开发,可以通过 OpenAI Hub 直连调用,兼容 OpenAI 格式,省去网络折腾:
from openai import OpenAI
client = OpenAI(
api_key=\"你的 OpenAI Hub Key\",
base_url=\"https://api.openai-hub.com/v1\"
)
response = client.chat.completions.create(
model=\"gpt-5.4\",
messages=[
{
\"role\": \"system\",
\"content\": \"你是一个安全分析助手,帮助分析代码中的潜在漏洞。\"
},
{
\"role\": \"user\",
\"content\": \"分析以下代码片段是否存在 SQL 注入风险:\
\
query = f\\"SELECT * FROM users WHERE id = {user_input}\\"\"
}
],
temperature=0.2
)
print(response.choices[0].message.content)
需要注意的是,GPT-5.4-Cyber 的完整能力(如二进制逆向)目前仅通过 TAC 计划开放,标准 API 调用的是通用版 GPT-5.4。但对于日常的代码审计、漏洞模式识别、安全报告生成等场景,通用版已经够用。
冷静看:一个模型解决不了安全问题
说完好的,也得说说这件事的局限。
"cyber-permissive"本身就是双刃剑。 降低拒绝阈值意味着模型更容易输出敏感内容。KYC 能过滤掉大部分恶意用户,但不能防住所有场景。一个通过认证的研究员把模型输出截图发到公开论坛,或者把分析结果分享给未授权的人,这些都是现实中会发生的事。
分级开放的公平性问题。 大型安全厂商和知名研究机构拿到高等级权限相对容易,但独立研究员、小型安全团队、发展中国家的安全从业者呢?如果最强的防御工具只有少数人能用,防御能力的不平等反而会加剧。
对闭源模型的依赖风险。 把核心安全工作流建立在一个闭源模型上,意味着你的能力上限由 OpenAI 决定。模型更新、API 变动、定价调整、甚至政策变化,都可能直接影响你的工作。安全社区一直有很强的开源传统,这种依赖关系会让很多人不舒服。
根本问题没变。 供应链攻击、零日漏洞、社会工程——这些威胁的本质是人和流程的问题,不是模型能力的问题。GPT-5.4-Cyber 能提升防御效率,但不能替代安全团队的判断力。把它当成"银弹"是危险的。
行业共识正在形成
抛开具体产品不谈,GPT-5.4-Cyber 的发布标志着一个行业共识的形成:网络安全能力足够强的 AI 模型,不能再按普通通用模型的逻辑去开放。
Anthropic 用极小范围开放来控制风险,OpenAI 用分级认证来平衡开放与管控,两种路径都指向同一个结论——AI 在安全领域的关键问题,正在从"能做什么"转向"谁能用、在什么场景下用、厂商如何控风险"。
这对整个 AI 行业都有示范意义。当模型能力强到一定程度,无差别开放就不再是最优策略。安全领域走在前面,但不会是唯一一个需要面对这个问题的领域。
未来几个月值得关注的是:Google 和 Meta 会不会跟进推出类似的安全专用模型?开源社区能不能做出可以对标的替代方案?以及最关键的——这些模型在真实攻防场景中的表现,到底能不能兑现论文和公告里的承诺。
答案还在路上,但方向已经很清楚了。
参考来源
- 逆风而行!开始分发 GPT-5.4! - Linux.do(社区讨论 GPT-5.4 分发动态)
- OpenAI 发布 GPT-5.4-Cyber:AI 网络安全防御进入专用模型时代 - 掘金(技术社区对 GPT-5.4-Cyber 的详细解读)
