GPT-5.5 发布窗口开启,换代在即

OpenAI 通过 Codex 模型列表更新和 Base64 彩蛋暗示 GPT-5.5 即将发布,GPT-5.4 已被摘掉「最前沿」标签,社区抓到多处偷跑痕迹,新一代前沿模型呼之欲出。
OpenAI 没开发布会,没发博客,但所有信号都指向同一件事——GPT-5.5 要来了。
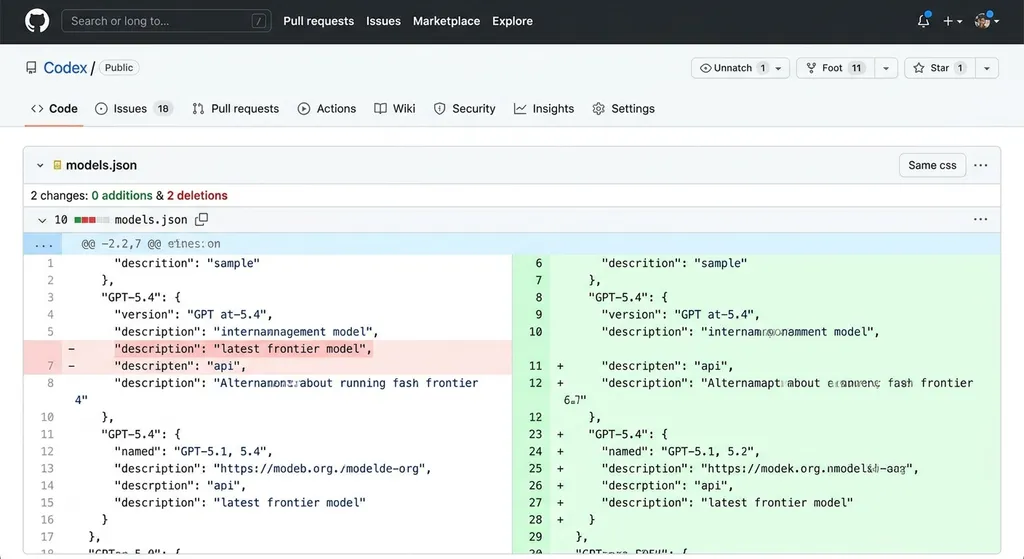
4 月 23 日,OpenAI 在 GitHub 上悄悄更新了 Codex 的 models.json 文件,把 GPT-5.4 头上那顶「latest frontier」的帽子摘了。这个改动本身只有 5 行加、5 行减,但信息量巨大:当现任旗舰不再被称为「最前沿」,唯一合理的解释就是——有新的要来顶替它。
一场精心设计的「偷跑」
事情的时间线值得捋一捋。
4 月 22 日,就有用户在 Codex CLI 终端里撞见了 GPT-5.5 的身影。界面上赫然写着「最前沿的智能体编程模型」。据 Reddit 社区用户 DavidAGMM 的帖子,当时 Codex CLI 里甚至泄露了一整批未发布的模型名称,包括一个颇具神秘感的 glacier-alpha-block-cy3。大概率是内部测试环境的配置被推到了生产环境——这种事在 OpenAI 不是第一次发生了。
到了 23 日,事情开始变得更有「官方感」。X 网友 @JasonBotterill 注意到 models.json 的变更后发帖指出 GPT-5.4 不再标注为「latest frontier」,Codex 负责人 Tibo(@thsottiaux)直接回复确认了这一点。紧接着,OpenAI 开发者官方账号 @OpenAIDevs 发了一条看似莫名其妙的帖子:
NS41
有人很快反应过来——这是 Base64 编码。解码结果:5.5。
这已经不是暗示了,这是明示。
从 5.4 到 5.5:OpenAI 的模型节奏在加速
回顾一下 GPT-5 系列的发布节奏,你会发现 OpenAI 这一年的迭代速度明显提了上来:
- GPT-5.1:作为 5 系列的早期迭代,主要在回答风格和质量上做了优化
- GPT-5.2 Instant:轻量化版本,面向速度敏感场景
- GPT-5.3 Instant mini:进一步压缩的小模型
- GPT-5.4:2026 年 3 月发布,包含 mini 和 Thinking 两个变体,是目前的旗舰
- GPT-5.5:即将登场
从 5.1 到 5.4,每次更新的间隔大约在 4-8 周。5.4 在 3 月中旬落地,5.5 在 4 月下旬进入发布窗口,节奏完全吻合。
但 5.5 的意义可能不止是「又一次小版本更新」。从 Codex 对它的定位描述——「最前沿的智能体编程模型」——来看,这次的重点很可能落在 Agent 能力上。换句话说,GPT-5.5 不只是「更聪明」,而是「更能干活」。
为什么是 Codex 先动?
这个问题值得想一想。
OpenAI 选择在 Codex 这个产品线上率先释放信号,而不是 ChatGPT,这本身就说明了 5.5 的核心卖点。Codex 是 OpenAI 面向开发者的 AI 编程工具,直接对标 GitHub Copilot(虽然 Copilot 背后也是 OpenAI 的模型)。在这个场景里,模型需要的不只是语言理解能力,还需要:
- 长上下文处理能力(读懂整个代码库)
- 工具调用能力(执行命令、操作文件)
- 多步推理能力(把一个需求拆解成可执行的步骤)
- 自主决策能力(在不确定的情况下做出合理判断)
这些恰恰是「智能体」(Agent)的核心能力。有用户反馈,在偷跑期间看到的 GPT-5.5 配置显示支持 1M 上下文窗口——如果属实,这意味着它可以一次性吃下一个中等规模项目的全部代码。
有意思的是,社区里已经有人在讨论一个很实际的问题:GPT-5.5 能不能补齐前端能力?这一直是 GPT 系列相对 Gemini 的短板。有开发者半开玩笑地说「为什么不蒸馏一下 Gemini 呢」——虽然是玩笑,但确实点出了一个真实痛点:在前端代码生成、UI 理解这些任务上,GPT 系列的表现一直不算拔尖。5.5 能不能在这方面有所突破,是很多开发者关心的事。
竞争格局:5.5 面对的对手不一样了
2026 年的 AI 模型市场和一年前已经完全不同。
Google 的 Gemini 3 Pro 据传即将 GA,社区里有传言说它的表现「远胜以往」,甚至有人拿它和 Gemini 3.5 相提并论。Anthropic 的 Claude 在代码生成领域已经建立了相当强的口碑,尤其是在复杂项目的上下文理解上。DeepSeek 在国内市场持续发力,性价比优势明显。
OpenAI 需要 5.5 来重新确立自己在前沿模型上的领先地位。从「最前沿的智能体编程模型」这个定位来看,他们选择的突破口是 Agent 能力——这也是目前整个行业最热的方向。
不过,光有模型还不够。Codex 作为产品的体验、API 的定价、速率限制,这些都会影响开发者的实际选择。目前 Codex Pro 20x 的账号已经有用户报告被路由到了新模型,说明 OpenAI 在灰度测试阶段优先照顾的是高付费用户——这个策略和之前 GPT-4.5 只对 Pro 用户开放如出一辙。
对开发者意味着什么
如果你在用 OpenAI 的 API 做开发,有几件事值得提前准备。
首先是模型切换。按照 OpenAI 的惯例,新模型发布后会有一段并行期,但旧模型最终会被下线。从 2026 年初 GPT-4o 等旧版模型被停止提供的经验来看,这个过渡期可能比你想象的短。如果你的应用还在硬编码模型名称,现在是个好时机把它改成可配置的。
其次是上下文窗口。如果 1M 上下文得到确认,这会解锁很多之前做不了的场景——比如把整个项目的代码一次性喂给模型做 code review,或者让模型在理解完整业务逻辑的前提下做重构建议。但更长的上下文也意味着更高的 token 消耗,成本控制需要重新规划。
最后是 Agent 能力。如果 5.5 真的在工具调用和自主决策上有显著提升,那些基于 LLM 构建的自动化工作流(CI/CD 集成、自动 bug 修复、代码迁移等)可能会迎来一波能力跃升。
抢先体验:API 调用准备
对于想第一时间接入 GPT-5.5 的开发者,可以提前准备好调用代码。按照 OpenAI 的命名惯例,新模型大概率会以 gpt-5.5 作为模型标识符。以下是一个基本的调用示例:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.openai-hub.com/v1" # OpenAI Hub 聚合接口,国内直连
)
response = client.chat.completions.create(
model="gpt-5.5", # 模型正式上线后可用,具体名称以官方为准
messages=[
{"role": "system", "content": "You are a senior software engineer."},
{"role": "user", "content": "Review this code and suggest improvements..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
如果你需要在同一个项目里灵活切换 GPT-5.5、Claude、Gemini 等不同模型做对比测试,OpenAI Hub(openai-hub.com)支持用同一个 Key 调用所有主流模型,接口格式兼容 OpenAI SDK,切换模型只需要改一个字符串,省去了管理多个 API Key 的麻烦。
# 同样的代码,换个模型名就能调 Claude 或 Gemini
response = client.chat.completions.create(
model="claude-sonnet-4-20250514", # 或 gemini-2.5-pro 等
messages=[
{"role": "user", "content": "Same prompt, different model."}
]
)
接下来看什么
从目前的信号密度来看,GPT-5.5 的正式发布可能就在未来几天内。OpenAI 的套路一般是:先偷跑/泄露制造话题 → 官方账号放彩蛋确认 → 正式发布博客 + API 上线。现在已经走到了第二步。
值得关注的几个点:
- 定价:5.5 作为新旗舰,定价会比 5.4 高多少?Agent 能力是否会单独计费?
- 速率限制:Pro 用户和普通用户的差异会有多大?
- Thinking 变体:5.4 有 Thinking 版本,5.5 大概率也会有,推理能力的提升幅度是关键
- 前端能力:社区呼声很高,OpenAI 有没有针对性地补强
- 实际 benchmark:偷跑阶段的零星反馈不够系统,需要等正式发布后的大规模测试
不管怎样,2026 年的模型竞赛还在加速。GPT-5.5 的到来不是终点,而是新一轮军备竞赛的起点。对开发者来说,好消息是选择越来越多,模型越来越强;坏消息是,你得花越来越多的时间来搞清楚哪个模型最适合你的场景。
这大概就是这个时代做开发者的甜蜜烦恼。
参考来源:
- GPT-5.5 已进入发布窗口,官方已完成预热 — Linux.do 社区讨论,汇总了官方信号和社区分析
- 疑似 Codex 中 5.5 上线,原设置的 GPT-5.4 被路由 — Codex Pro 用户反馈模型被路由到新版本
- GPT 新模型已确认将在稍后发布 — models.json 变更分析及 Base64 彩蛋解读
- 开个贴,一起见证 GPT-5.5 的发布 — 社区实时讨论帖
- GPT-5.5 有没有可能补齐前端能力 — 开发者对新模型能力的期待讨论
- OpenAI Codex models.json 更新 — GitHub 上的模型配置文件变更记录
- GPT-5.5 明天发布讨论 — Reddit Codex 社区的发布预测帖
