GPT-5.5 来了:更聪明,更便宜

OpenAI 发布迄今最强模型 GPT-5.5(代号 Spud),Agent 能力大幅跃升,配合英伟达新芯片每 Token 成本降至前代 1/35,正式拉开大模型「又强又便宜」的新阶段。
OpenAI 今天发布了 GPT-5.5,内部代号「Spud」。距离 Anthropic 放出最新模型刚过去一周,这个节奏很 OpenAI——你出牌,我跟牌,而且要压你一头。
联合创始人 Greg Brockman 给了一个相当高调的定性:「一类全新的智能」。这话放在过去几轮发布里都听过,但这次看完跑分和实际反馈,确实不太一样。
核心变化:不是更会聊天,是更会干活
先说最重要的一点——GPT-5.5 的升级重心不在对话质量上,而在 Agent 能力。
什么意思?过去你用 GPT 干活,本质上是你在当项目经理:把任务拆好、把 prompt 写清楚、一步步喂给模型。GPT-5.5 想改变的是这个交互范式。你可以直接甩一个模糊的、结构混乱的多步骤需求过去,模型自己规划执行路径、调用工具、检查中间结果,一路推进到产出可用的结论。
用 Brockman 的原话说:「更少的指导,更多的产出。」
这不是画饼。从早期测试者的反馈来看,GPT-5.5 在几个场景上的提升是肉眼可见的:
- 理解系统架构的能力明显增强,不再需要你把整个代码库的上下文手动喂进去
- 定位故障的准确率提高,能主动关联上下游依赖
- 在代码审查场景中,能预判 reviewer 可能提出的问题
有开发者在社区里分享了一个直观感受:「5.4 更像一个完美主义的逻辑大师,5.5 更像一个实践派——先做再测。」这个比喻挺准确的。5.5 的风格更偏向「先出活、再迭代」,测试用例写得更多,会更积极地读取上下文,减少了那种「看起来很专业但其实是废话」的输出。
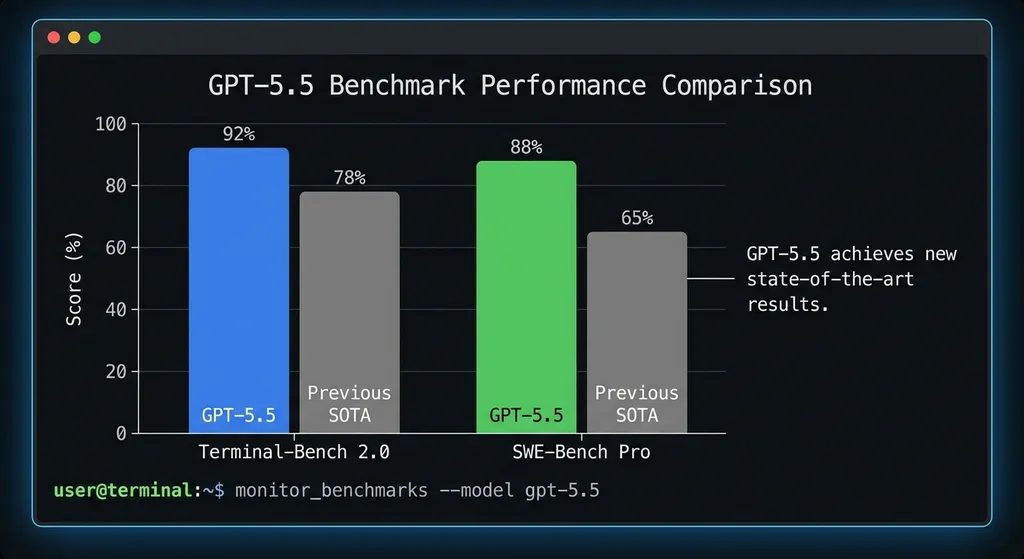
跑分:该卷的地方没落下
数字层面,GPT-5.5 交出的成绩单相当扎实:
- Terminal-Bench 2.0:82.7% 准确率
- SWE-Bench Pro(评估 GitHub issue 解决能力):58.6%
- Expert-SWE 等长周期任务:全面超越 GPT-5.4
- Artificial Analysis Coding Index:以竞品一半的成本达到 SOTA 水平
- GeneBench 基因数据分析、BixBench 生物信息学基准:均取得领先成绩
其中 SWE-Bench Pro 的 58.6% 值得单独说一下。这个 benchmark 测的是模型解决真实 GitHub issue 的能力——不是那种精心构造的考试题,而是开发者日常遇到的、带有模糊描述和复杂上下文的真实 bug。能在这个测试上拿到接近六成,说明 GPT-5.5 的代码理解和修复能力已经到了一个实用门槛。
更有意思的是科研方向的突破。OpenAI 称 GPT-5.5 协助发现了关于 Ramsey Numbers(拉姆齐数)的新证明。如果你对这个名字有印象的话——去年 GPT-5.2 Pro 破解埃尔德什猜想的时候,陶哲轩亲自认证过。这条线上 OpenAI 一直在推进,5.5 又往前走了一步。
真正的杀手锏:成本
模型更强不稀奇,每一代都更强。真正让这次发布值得关注的是成本结构的变化。
GPT-5.5 的 API 输入定价是每百万 Token 5 美元。作为参考,这个价格和 Google Gemini 2.5 的基础订阅价格持平。但更关键的数字来自英伟达那边——配合新一代芯片,运行 GPT-5.5 这类前沿模型的每 Token 成本可以压缩到此前的 1/35。
1/35,不是 1/3.5。
这个降幅意味着什么?举个例子:如果你之前跑一个 Agent 工作流,让 GPT-5.4 处理一个复杂的代码审查任务,Token 消耗可能在 10 万左右,成本大约 1 美元。同样的任务交给 GPT-5.5,首先模型本身完成任务所需的 Token 就更少(OpenAI 明确说了「完成相同任务减少 Token 消耗」),再叠加基础设施层面的降本,实际花费可能只有原来的几十分之一。
对个人开发者来说这是省钱,对企业来说这是战略级的变化。过去很多公司不是不想用大模型,而是算过账之后发现 Token 成本会随着使用量指数级膨胀,IT 预算根本扛不住。现在这个经济模型被重写了。
英伟达企业计算副总裁 Justin Boitano 的说法更直白:GPT-5.5 可以在企业内部扮演「幕僚长」的角色,为已经在跑的 AI Agent 提供能力支撑。英伟达和 OpenAI 还联合制定了一套部署蓝图,帮企业更快落地。
速度:没有变慢
这一点值得单独拎出来说,因为过去几代模型的一个普遍规律是「更强 = 更慢」。GPT-5.5 打破了这个规律——尽管模型更大、能力更强,但每个 Token 的延迟与 GPT-5.4 持平。
怎么做到的?OpenAI 没有公开技术细节,但从 System Card 和社区讨论来看,5.5 大概率进行了全新的预训练(社区对「Spud 是否是全新预训练」的讨论基本倾向于是),而不是在 5.4 基础上做增量优化。这意味着架构层面可能有调整,而不仅仅是数据和训练策略的变化。
对开发者来说,「不变慢」这件事的实际意义可能比「变更强」还大。因为在生产环境中,延迟直接决定了用户体验和系统吞吐量。一个又强又不慢的模型,才是真正能上生产的模型。
实际落地:OpenAI 自己先吃了狗粮
OpenAI 给了一组内部数据:超过 85% 的员工每周使用 Codex(基于 GPT-5.5),财务团队用它审核了超过 7 万页税务文件。
7 万页税务文件——这不是写个 demo 跑个 benchmark,这是真金白银的生产级使用。财务文件的审核对准确率要求极高,容错空间几乎为零。OpenAI 敢把自己的税务文件交给模型处理,本身就是一种信号。
外部合作伙伴的反馈也值得关注。英伟达称 GPT-5.5 将调试时间从「数天缩短至数小时」。英伟达有 3 万工程师,部分员工已经参与了数周的测试,随后将全员开放。一家拥有顶级工程团队的公司愿意全面部署,说明这不是 PR 话术。
获得早期试用权限的团队还反馈了一些更细节的场景:
- 对带有「情绪色彩」的创意性工作进行校验(比如营销文案的 tone 检查)
- 批量审阅额外数千份文档
- 每周节省最多 10 小时的工作时间
一个值得注意的使用细节
社区里有开发者做了一个有趣的观察:如果你想让 GPT-5.5 写文档或做深度分析,最好在 prompt 里加上「深度思考这个问题」这几个字。否则即使你把推理等级设到最高(xhigh),模型也倾向于快速完成任务而不是深入思考。
这其实反映了 5.5 的一个设计哲学——默认模式是「高效执行」而非「深度推理」。对于大多数 Agent 场景来说这是对的,因为你不希望一个自动化工作流在每个步骤上都花大量时间思考。但如果你的场景确实需要深度推理,需要显式地告诉模型。
记住这个技巧,可能会帮你省不少调试时间。
开放节奏与 API 接入
GPT-5.5 今天起面向 Plus、Pro 用户在 ChatGPT 和 Codex 中开放。API 版本即将上线,OpenAI 表示需要先完成额外的网络安全防护措施部署。
API 定价:
| 类型 | 价格(每百万 Token) | |------|---------------------| | 输入 | $5 | | 输出 | 待公布(参考 GPT-5 的 $10) |
对于已经在用 OpenAI API 的开发者,接入 GPT-5.5 基本是改一个 model 参数的事。如果你通过 OpenAI Hub 这类聚合平台调用,切换会更简单——通常在模型上线后很快就能支持,一个 Key 就能调。
以下是一个基本的调用示例,展示如何通过兼容 OpenAI 格式的 API 接入 GPT-5.5:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.openai-hub.com/v1" # OpenAI Hub 聚合接口,国内直连
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{
"role": "system",
"content": "你是一个资深软件工程师,擅长代码审查和架构分析。请深度思考这个问题。"
},
{
"role": "user",
"content": "分析这个 Python 项目的依赖关系,找出潜在的循环引用问题,并给出重构建议。"
}
],
temperature=0.3,
max_tokens=4096
)
print(response.choices[0].message.content)
注意 system prompt 里的「深度思考这个问题」——前面提到的社区经验,在 API 调用中同样适用。
如果你要跑 Agent 工作流,可以利用 5.5 的工具调用能力:
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{
"role": "user",
"content": "查看项目中最近 3 天的 GitHub Issues,分析哪些是 bug、哪些是 feature request,按优先级排序并生成周报。"
}
],
tools=[
{
"type": "function",
"function": {
"name": "search_github_issues",
"description": "搜索 GitHub 仓库的 Issues",
"parameters": {
"type": "object",
"properties": {
"repo": {"type": "string", "description": "仓库名称"},
"since": {"type": "string", "description": "起始日期,ISO 格式"},
"state": {"type": "string", "enum": ["open", "closed", "all"]}
},
"required": ["repo"]
}
}
}
],
tool_choice="auto"
)
这种「甩一个模糊需求、让模型自己拆解执行」的用法,正是 GPT-5.5 Agent 能力的核心场景。
竞争格局:价格战正式开打
把 GPT-5.5 放到整个行业里看,有几个值得关注的信号。
第一,发布时间。距离 Anthropic 最新模型发布仅一周。OpenAI 内部此前将 Anthropic 的快速崛起形容为「红色警报」和「警钟」,这次的快速跟进显然是有意为之。
第二,定价策略。输入 $5/百万 Token 的价格直接对标 Gemini 2.5,而不是像过去那样走高端定价路线。再加上英伟达新芯片带来的 1/35 成本压缩,OpenAI 显然在释放一个信号:大模型的价格战,正式开打。
第三,企业转向。Brockman 在发布会上提了一个很宏大的概念——「由算力驱动的经济」。但剥开修辞看本质,OpenAI 的战略重心正在从 C 端消费者转向 B 端企业客户。GPT-5.5 的 Agent 能力、与英伟达的联合部署蓝图、以及「幕僚长」的定位,都指向同一个方向:让企业把 AI 当基础设施用,而不是当玩具用。
这对开发者意味着什么?意味着围绕大模型构建 Agent 和工作流的需求会加速爆发。模型能力到了,成本降了,企业愿意买单了——接下来缺的就是能把这些能力落地到具体业务场景的人。
冷静看几个问题
当然,也不是所有事情都那么美好。
首先,API 还没正式上线。OpenAI 说要先部署安全防护措施,具体时间没给。对于等着用 API 做集成的开发者来说,这个「即将」可能意味着几天,也可能意味着几周。
其次,社区测试中发现 GPT-5.5 在某些逻辑推理题上的表现并不稳定。有开发者用一道组合数学题(从袋子里摸糖果的概率问题)测试,发现模型的回答质量波动较大。这说明在纯数学推理方面,5.5 的提升可能没有在代码和 Agent 场景上那么显著。
最后,「默认快速执行」的设计哲学是一把双刃剑。对于需要深度分析的场景,如果用户不知道要显式触发深度思考模式,可能会得到一个看起来完整但实际上浅尝辄止的回答。这个交互设计上的取舍,值得 OpenAI 在后续版本中优化。
写在最后
GPT-5.5 不是一个「更会聊天的模型」,而是一个「更会干活的模型」。这个定位的转变,可能比任何一个 benchmark 数字都重要。
当模型从「对话工具」进化成「执行引擎」,当 Token 成本降到企业可以大规模使用的水平,当英伟达和 OpenAI 联手推出企业部署蓝图——我们正在看到的,不是又一次模型迭代,而是 AI 从「能用」到「好用」到「必须用」的临界点。
对开发者来说,现在是认真研究 Agent 工作流的时候了。模型能力已经不是瓶颈,成本也不再是瓶颈。瓶颈是你能不能想清楚,在你的业务场景里,哪些工作可以交给一个「实践派的 AI 同事」来做。
参考来源:
- IT之家:OpenAI 最智能 AI 模型 GPT-5.5 登场 — 详细的发布信息、跑分数据和定价
- Linux.do:GPT-5.5 发布复盘 — 社区对 Spud 代号和预训练方式的讨论
- Linux.do:关于 GPT-5.5 个人测试 — 开发者实测反馈和使用技巧
