蚂蚁万亿模型 Ling-2.6-1T:用"快思考"挑战 GPT-5.4

蚂蚁百灵发布万亿级模型 Ling-2.6-1T,摒弃主流"慢思考"路线,以极低 Token 开销实现高效推理,综合能力对标 GPT-5.4 非推理版,已上线 API 并将开源。
蚂蚁万亿模型 Ling-2.6-1T:用"快思考"挑战 GPT-5.4
蚂蚁百灵今天发布了万亿参数级旗舰模型 Ling-2.6-1T,核心卖点是"快思考"——在行业普遍追求 o1、o3 式多步推理的当下,蚂蚁选择了一条截然相反的路:用极低的 Token 开销直接给出答案,而不是让模型在内部反复推演。这个技术路线在万亿参数量级的大模型里相当罕见,也让人好奇:在 DeepSeek-R1、GPT-o3 们把"慢思考"卷到极致的时候,"快思考"还能打吗?
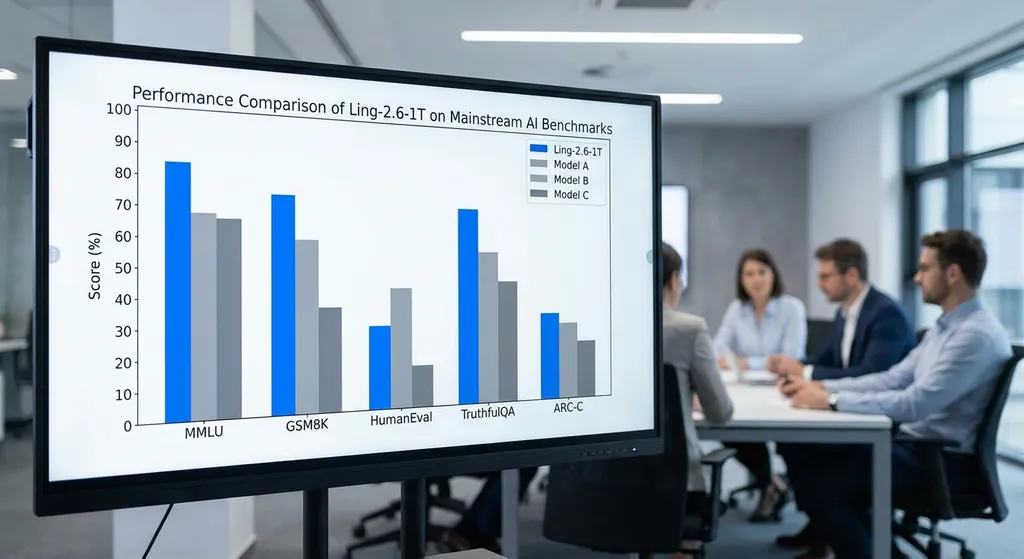
从实测数据看,答案是肯定的。Artificial Analysis 的评测显示,Ling-2.6-1T 的综合智能水平已经和 GPT-5.4(非推理模式)处于同一档次。在高难度数学推理任务 AIME2026 上,它显著领先其他非思考型模型;在 SWE-bench Verified、TAU2-Bench、BFCL-V4 等 Agent 执行榜单中也稳居前列。这意味着,至少在不需要长链推理的场景里,"快思考"的效率优势足以抵消"慢思考"的精度增益。
技术路线:MLA + Linear Attention 的混合架构
"快思考"不是简单地砍掉推理步骤,而是在架构层面做了针对性优化。Ling-2.6-1T 采用了 MLA(Multi-head Latent Attention)与 Linear Attention 的混合设计。MLA 是 DeepSeek 在 V2 和 V3 中用过的技术,核心思路是把多头注意力的 KV Cache 压缩到低秩潜在空间,降低显存占用和计算开销;Linear Attention 则进一步把注意力机制的复杂度从 O(n²) 降到 O(n),让长上下文推理的成本不再随序列长度爆炸式增长。
这两个技术的组合,本质上是在用架构效率换推理深度。传统的"慢思考"模型会在内部生成大量中间 Token(比如 o1 的思维链可能长达几千 Token),然后再输出最终答案;而 Ling-2.6-1T 的策略是让模型在前向传播时就尽可能"想清楚",减少不必要的中间步骤。这种设计在处理明确任务(比如代码生成、API 调用、指令执行)时优势明显,但在需要探索性推理的开放问题上可能不如 o1、R1 那样稳健。
蚂蚁的选择其实很务实:他们的前代旗舰 Ling-1T 就已经在"受限输出 Token"条件下拿到过多个榜单的 SOTA,说明在很多实际场景里,用户并不需要模型输出冗长的思维链,而是希望它快速、准确地完成任务。Ling-2.6-1T 把这个思路推到了极致——既然大部分任务不需要慢思考,那就把架构彻底优化成"快思考"专用。
性能表现:对标 GPT-5.4,Agent 能力突出
从公开的评测数据看,Ling-2.6-1T 的综合能力确实达到了 GPT-5.4(非推理模式)的水平。这里需要注意的是"非推理模式"这个限定——GPT-5.4 如果开启推理模式(类似 o1 的多步思考),性能会更强,但成本和延迟也会显著增加。Ling-2.6-1T 的定位就是对标这个"快速版"的 GPT-5.4,在不牺牲太多精度的前提下,把速度和成本优势拉满。
具体到各个基准测试:
- AIME2026(高难度数学竞赛题):Ling-2.6-1T 在非思考型模型中表现最好,虽然比不上 o1、R1 这种专门为推理优化的模型,但已经超过了 GPT-4o、Claude 3.5 Sonnet 等同类产品。
- SWE-bench Verified(真实软件工程任务):这个榜单考验的是模型理解代码库、定位 bug、生成修复代码的完整能力。Ling-2.6-1T 位居前列,说明它在 Agent 场景下的执行稳定性很强。
- TAU2-Bench 和 BFCL-V4(复杂 API 调用和工具使用):这两个榜单更接近实际应用场景,比如让模型调用多个 API 完成一个复杂任务。Ling-2.6-1T 的表现同样优秀,这对开发者来说是个好消息——意味着它可以直接集成到现有的 Agent 框架里,不需要太多适配工作。
- IFBench(指令遵循测试):这个榜单考验模型在多重约束条件下的执行准确率。Ling-2.6-1T 的高分说明它在理解复杂指令、保持逻辑一致性方面做得不错。
另外,Ling-2.6-1T 支持 256K 超长上下文,这在处理大型代码库、长文档分析时很有用。虽然 256K 在当下已经不算特别突出(Gemini 1.5 Pro 支持 2M,Claude 3.5 Sonnet 支持 200K),但对于大部分实际任务来说已经够用了。
"快思考" vs "慢思考":两条路线的权衡
过去一年,AI 行业的主旋律是"慢思考"。OpenAI 的 o1、o3,DeepSeek 的 R1,都在用更长的推理时间换更高的精度。这个路线在数学、编程、科学推理等需要严密逻辑的任务上效果显著,但也带来了两个问题:
- 成本高:o1 的推理 Token 可能是普通模型的 10 倍甚至更多,对于高频调用的应用来说,成本压力很大。
- 延迟长:多步推理意味着更长的响应时间,在需要实时交互的场景(比如客服、代码补全)里体验不好。
蚂蚁的"快思考"路线本质上是在赌:大部分实际任务并不需要那么深的推理链。比如写一个 API 调用代码、修复一个明显的 bug、根据用户指令生成一段文案,这些任务的逻辑路径相对清晰,模型不需要在内部反复试错,直接给出答案就行。
这个判断有一定道理。从 SWE-bench、BFCL 这些榜单的结果看,Ling-2.6-1T 在明确任务上的表现并不比"慢思考"模型差多少,但成本和速度优势明显。当然,在需要探索性推理的开放问题上(比如"设计一个分布式系统架构"),"快思考"可能就不如"慢思考"那样全面了。
所以这两条路线不是非此即彼,而是各有适用场景。对于开发者来说,理想的状态是根据任务类型选择合适的模型:需要深度推理的用 o1、R1,需要快速执行的用 Ling-2.6-1T。蚂蚁也在产品矩阵里保留了不同规模的版本(Ling-Lite、Ling-Plus),以及专门做推理的 Ring 系列,给用户更多选择空间。
API 已上线,即将开源
Ling-2.6-1T 目前已经上线 API 服务,开发者可以通过蚂蚁官方平台或 OpenRouter 调用。从兼容性角度看,它和主流 Agent 框架(比如 LangChain、AutoGPT)保持高度兼容,集成成本不高。
更值得关注的是,蚂蚁透露这个模型将在近期开源。这对开发者来说是个好消息——万亿参数级的模型开源案例并不多(DeepSeek-V3 算一个,Llama 3.1 405B 算一个),而且 Ling-2.6-1T 的"快思考"架构在开源社区里还比较少见,可以给研究者提供新的优化思路。
开源之后,开发者可以基于 Ling-2.6-1T 做本地部署和二次开发。考虑到它的架构设计(MLA + Linear Attention)对显存和计算资源的要求相对较低,在消费级硬件上跑起来的门槛可能比传统万亿参数模型要低一些。当然,具体的部署成本还得等开源后才能确认。
蚂蚁的模型策略:效率优先
从 Ling-2.6-1T 的发布可以看出,蚂蚁在大模型上的策略是"效率优先"。这和他们的业务场景有关——支付宝、蚂蚁金服的很多应用都是高频、低延迟的,用户不会等你慢慢推理,而是希望立刻得到结果。在这种场景下,"快思考"比"慢思考"更实用。
这个策略也体现在他们的产品矩阵里。除了 Ling-2.6-1T 这个万亿级旗舰,还有 Ling-Lite(轻量版)、Ling-Plus(增强版)等不同规模的版本,以及专门做推理的 Ring 系列。这种分层设计让开发者可以根据任务需求选择合适的模型,而不是用一个"大而全"的模型硬撑所有场景。
从竞争格局看,Ling-2.6-1T 的对手主要是 GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro 这些"快速版"的闭源模型,以及 DeepSeek-V3、Qwen2.5 这些开源模型。在性能上,它已经达到了 GPT-5.4 非推理版的水平;在成本上,"快思考"的架构优势可以进一步压低推理开销;在开放性上,即将开源的承诺也是个加分项。
当然,蚂蚁在海外市场的影响力还比较有限,Ling-2.6-1T 能不能在国际上站稳脚跟,还得看后续的生态建设和开发者反馈。但至少在国内市场,这个模型已经具备了和主流产品正面竞争的实力。
写在最后
"快思考"和"慢思考"的路线之争,本质上是效率和精度的权衡。蚂蚁用 Ling-2.6-1T 证明了,在很多实际场景里,"快"比"慢"更重要。这个模型的发布,也给行业提供了一个新的参考点:大模型不一定要往"更深的推理"方向卷,在架构效率上做文章,同样可以打出差异化。
对于开发者来说,Ling-2.6-1T 是个值得关注的选择——尤其是在需要高频调用、低延迟响应的场景里。API 已经上线,开源也在路上,可以先试试看效果如何。至于它能不能真正挑战 GPT-5.4,还得看实际应用中的表现。但至少从现在的数据看,蚂蚁这次交出的答卷还是挺有诚意的。
参考来源
- 蚂蚁百灵万亿旗舰模型 Ling-2.6-1T 发布:主打"快思考",对标 GPT-5.4 非推理版 - IT之家
IT之家对 Ling-2.6-1T 发布的详细报道,包含技术架构、性能数据和产品定位
