DeepSeek缓存一折永久生效,价格战卷到地板

DeepSeek宣布全系列模型API输入缓存命中价格永久降至首发价1/10,从限时优惠直接转为常驻定价,再次刷新国产大模型API价格下限。
DeepSeek 缓存命中永久一折:梁文锋又把价格打到了地板上
就在所有人以为大模型 API 涨价潮已成定局的时候,DeepSeek 又反着来了。
4 月 25 日,DeepSeek 悄然更新了官方 API 定价页面:全系列模型(包括最新的 V4 Pro)输入缓存命中价格降至首发价格的 1/10,且为永久生效,不是限时优惠。
消息一出,开发者社区直接炸了。Linux.do 论坛上相关帖子在几小时内涌出近十个,标题画风从"梁圣这是干什么"到"有钱真不赚啊",充满了一种被甲方反向补贴的荒诞感。
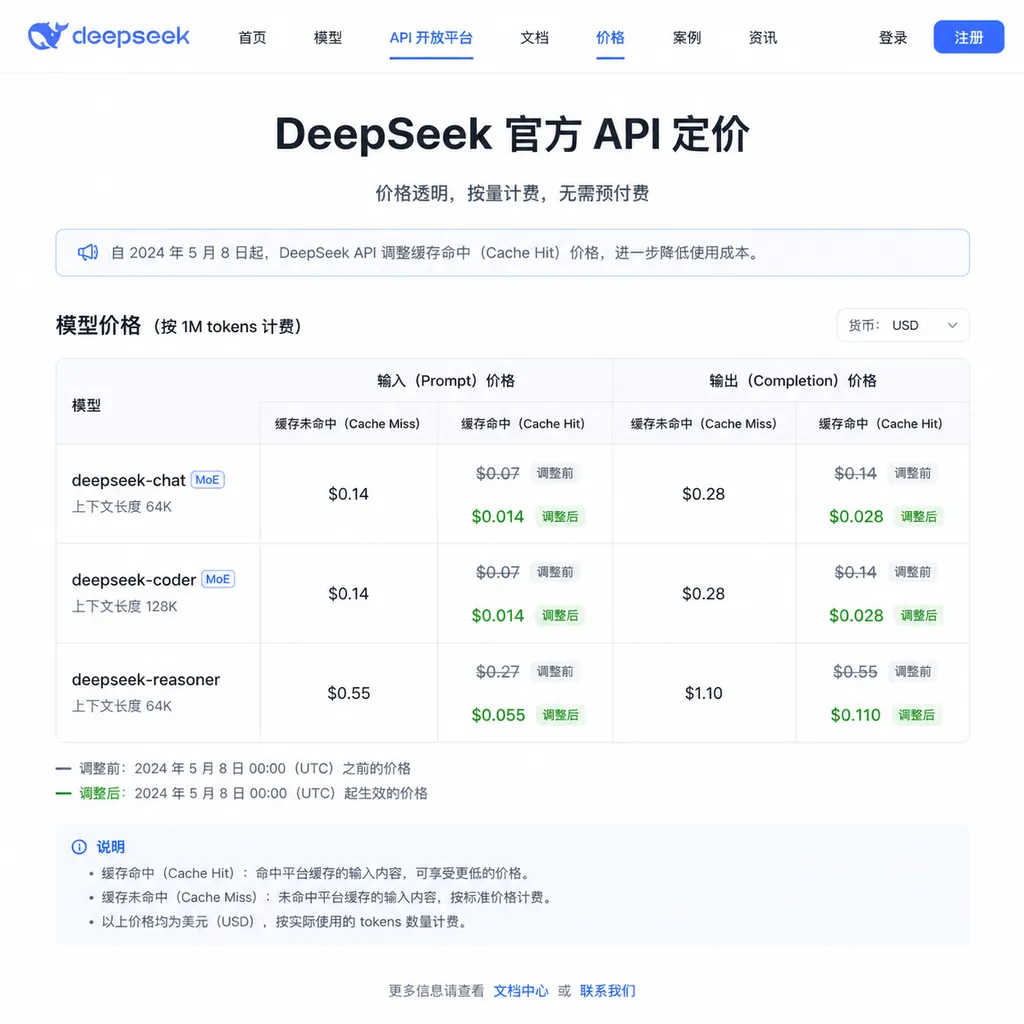
到底降了多少?算一笔账
先把数字摆清楚。
以 DeepSeek V4 Pro 为例,此前的价格体系大致是这样的:
| 计费项 | 调整前价格(元/百万 tokens) | 调整后价格(元/百万 tokens) | |---|---|---| | 输入(缓存未命中) | 维持不变 | 维持不变 | | 输入(缓存命中) | 首发价 × 1 | 首发价 × 0.1 | | 输出 | 维持不变 | 维持不变 |
关键在于"缓存命中"这四个字。DeepSeek 从 V2 时代就开始做硬盘 KV Cache——当你的请求和之前的请求有相同的前缀内容时(比如 system prompt、多轮对话的历史上下文),重复部分直接从缓存读取,不需要重新计算。命中缓存的部分,价格本来就比未命中的低很多,现在再打一折。
什么概念?如果你的应用场景中缓存命中率能到 80%(这在多轮对话、Agent 调用、RAG 等典型场景中很常见),你的实际输入成本会被压到一个极低的水平。对于那些 system prompt 很长、上下文复用率高的应用来说,输入成本几乎可以忽略不计。
更值得注意的是时间线:昨天(4 月 24 日)DeepSeek 刚宣布了限时 2.5 折优惠,今天就直接把缓存命中改成永久一折。 一天之内连降两次,而且后一次比前一次更狠、更持久。论坛里有用户吐槽"昨天用了一天,亏了"——虽然是玩笑话,但足以说明这个降价速度让人措手不及。
为什么 DeepSeek 敢这么定价?
要理解这次降价的底气,得回到 DeepSeek 的技术架构上。
MLA 架构的成本红利
DeepSeek 从 V2 开始引入的 MLA(Multi-head Latent Attention)结构,是它能在缓存上做文章的根本原因。传统 Transformer 的 KV Cache 体积巨大,存储和传输成本都很高。MLA 通过对注意力头进行潜空间压缩,将 KV Cache 的大小压缩了数倍甚至一个数量级。
这意味着什么?同样的硬盘空间能缓存更多的上下文,同样的带宽能传输更多的缓存数据。当缓存的边际成本足够低时,把价格打下来就不是在烧钱,而是在用技术优势换市场份额。
硬盘缓存的规模效应
DeepSeek 是全球最早在 API 服务中大规模采用硬盘 KV Cache 的厂商之一。硬盘相比 GPU 显存和内存,成本低了好几个数量级。而且 DeepSeek 的缓存系统设计得相当激进——缓存时间比其他厂商长得多。
论坛上有开发者专门对比过:某些竞品的缓存有效期短到需要你像"赛博监工"一样时刻盯着,防止缓存过期后成本飙升。而 DeepSeek 的缓存保留时间要宽裕得多,开发者不需要为了维持缓存命中率而刻意设计请求频率。
这一点在实际开发中非常重要。如果缓存窗口太短,你要么得频繁发送"保活"请求(浪费钱),要么就得接受缓存频繁失效带来的成本波动(不可控)。DeepSeek 的长缓存时间配合一折价格,让开发者可以更从容地设计应用架构,而不是围着缓存策略转。
行业背景:别人在涨价,它在降价
把这次降价放到整个大模型 API 市场的大背景下看,反差更加强烈。
2025 年下半年开始,国产大模型 API 市场出现了一轮明显的涨价潮。DeepSeek 自己在去年 V3.1 发布时也调过一次价——取消夜间五折优惠,输出价格从 8 元涨到 12 元/百万 tokens。当时 36 氪和《IT时报》都做过报道,讨论的核心问题是:大模型价格战是不是结束了?
智谱的 GLM-4.5-X 优惠结束后输入价格高达 16 元/百万 tokens,月之暗面的 Kimi K2 高速版恢复原价后输出价格达到 64 元/百万 tokens。整个行业的定价趋势是往上走的。
逻辑也很简单:算力贵、人才贵、数据贵,前期的价格战是烧钱换市场,不可能一直烧下去。OpenAI 今年单月营收突破 10 亿美元,但 Sam Altman 说未来要投入上万亿美元建数据中心。连行业龙头都在为成本发愁,其他人凭什么能一直低价?
但 DeepSeek 偏偏在这个节点选择了反向操作。
这不是简单的"用亏损换增长"。从技术角度看,缓存命中的部分确实不需要消耗多少 GPU 算力——数据从硬盘读取,跳过了最昂贵的计算环节。所以缓存命中的边际成本本来就远低于正常推理。把这部分价格打到极低,对 DeepSeek 的利润影响可能没有外界想象的那么大,但对开发者的心理冲击是巨大的。
对开发者意味着什么?
这次降价对不同类型的开发者影响不同,取决于你的应用场景中缓存命中率有多高。
高受益场景
- 多轮对话应用:每一轮对话都要把历史上下文重新发送,前缀重复率天然就高。缓存命中率轻松到 70%-90%。
- Agent / Function Calling:Agent 类应用通常有很长的 system prompt 和工具描述,这些在每次调用中都是固定的,缓存命中率极高。
- RAG 应用:如果你的检索结果相对稳定(比如同一个知识库被不同用户反复查询),前缀部分的缓存复用率也很可观。
- 批量处理:用相同的 prompt 模板处理大量数据时,模板部分每次都能命中缓存。
低受益场景
- 单轮短请求:没有上下文复用,缓存命中率低,这次降价对你影响不大。
- 每次请求内容完全不同:比如纯翻译、纯摘要等一次性任务,前缀没有重复,缓存基本用不上。
实际优化建议
如果你想最大化利用这次降价,有几个实操层面的建议:
-
把固定内容放在请求的最前面。DeepSeek 的缓存是前缀匹配——只有从第 0 个 token 开始连续相同的部分才能命中。所以 system prompt、工具定义、固定指令这些不变的内容,一定要放在 messages 的最前面。
-
避免在前缀中插入动态内容。比如有些开发者喜欢在 system prompt 里插入当前时间戳,这会导致每次请求的前缀都不同,缓存完全失效。把动态内容挪到 user message 里。
-
注意 64 tokens 的最小缓存单元。DeepSeek 的缓存系统以 64 tokens 为一个存储单元,不足 64 tokens 的内容不会被缓存。所以你的固定前缀至少要有 64 tokens 才能享受缓存优惠。
-
利用长缓存窗口。不需要像使用某些竞品那样频繁发送请求来"保活"缓存。DeepSeek 的缓存保留时间足够长,正常使用频率下缓存不会过期。
价格战的终局在哪里?
回到更宏观的问题:DeepSeek 这种定价策略可持续吗?
我的判断是:在缓存命中这个具体环节上,可持续性比看起来要强。
原因很简单——缓存命中的成本结构和正常推理完全不同。正常推理需要 GPU 做大量矩阵运算,这是大模型 API 最大的成本项。而缓存命中只需要从硬盘读取预计算好的 KV Cache,消耗的主要是存储和带宽,不占用宝贵的 GPU 算力。
对 DeepSeek 来说,MLA 架构带来的 KV Cache 压缩优势让存储成本进一步降低。所以缓存命中一折的定价,可能确实接近甚至已经覆盖了边际成本。这不是赔本赚吆喝,而是技术优势的直接变现。
但这也给其他厂商出了一道难题。如果你的模型架构没有类似 MLA 的 KV Cache 压缩能力,你的缓存成本就是比 DeepSeek 高,你跟不跟?跟了可能亏钱,不跟可能丢客户。
从更长远的视角看,大模型 API 的定价正在走向精细化。早期是简单粗暴的"输入 X 元、输出 Y 元",现在开始按缓存命中/未命中、不同上下文长度、不同速度档位来差异化定价。这说明行业在成熟——厂商开始根据实际的成本结构来设计价格体系,而不是一刀切。
DeepSeek 这次的操作,本质上是在说:我在缓存这个环节有结构性的成本优势,所以我把这个优势直接让给开发者。 这比单纯的"全场五折"要聪明得多,因为它精准地打击了竞争对手的弱点,同时自己的利润损失可控。
写在最后
2024 年的大模型价格战,大家比的是谁更敢亏钱。2025 年的涨价潮,大家开始面对现实。而 2026 年的 DeepSeek,似乎在用行动证明一个朴素的道理:真正的低价不是靠补贴,是靠技术。
当你的架构能让某个环节的成本比别人低一个数量级,你就可以在那个环节把价格打到别人跟不了的程度,同时自己还有利润。这才是健康的、可持续的"价格战"。
对于开发者来说,现在是重新审视自己应用架构的好时机。如果你的应用还没有针对缓存做优化,这次降价就是一个强信号:把固定内容前置、最大化缓存命中率,不再是可选的优化项,而是直接影响成本的核心策略。
至于梁文锋是不是"圣人",这个问题留给论坛去讨论。但有一点可以确定:在技术驱动降本这条路上,DeepSeek 目前确实走在最前面。如果你在用 OpenAI Hub 这类 API 聚合平台,现在也可以直接体验到 DeepSeek 最新的定价——一个 Key 调所有主流模型,国内直连,省去折腾的时间。
价格已经到了这个份上,接下来比的就是谁能把便宜的 tokens 用出更大的价值了。
参考来源
- DeepSeek API 再次降价:缓存命中降至 1 折 — Linux.do 社区讨论,汇总了官方降价信息
- 梁圣这是干什么?缓存永久一折啦! — 开发者社区对永久降价的热议
- deepseek 官方优惠更新 缓存1折(更新:永久1折) — 最早发现降价并确认为永久优惠的帖子
- DeepSeek V4 系列输入缓存价格降至首发价格 1/10 — 引用官方文档的价格确认
- deepseek这个缓存一折,貌似没写限时啊 — 社区对"永久"性质的讨论
- DeepSeek 恢复V3 模型API 价格相关讨论 — 知乎上关于 DeepSeek 历史定价变动的讨论
