DeepSeek 缓存永久一折,API 价格再砍一刀

DeepSeek 宣布全系列模型 API 输入缓存命中价格永久降至首发价的 1/10,叠加此前 V4 Pro 的 2.5 折优惠,开发者调用成本再创新低。
DeepSeek 缓存永久一折,API 价格再砍一刀
DeepSeek 又降价了。
4 月 26 日,DeepSeek 官方更新 API 定价策略,将全系列模型的输入缓存命中价格永久下调至首发价格的 1/10。注意关键词:永久。这不是限时促销,不是错峰优惠,是写进价格表里的常驻调整。
就在昨天,DeepSeek 刚刚给 V4 Pro 系列搞了个限时 2.5 折的活动,开发者社区还在讨论「这波能薅多久」,今天缓存价格直接打到一折,而且没有截止日期。社区里有人调侃:「昨天限时二点五折,今天永久一折,你这样太客气,搞得人家都不好意思了。」
说实话,这个定价确实有点离谱。
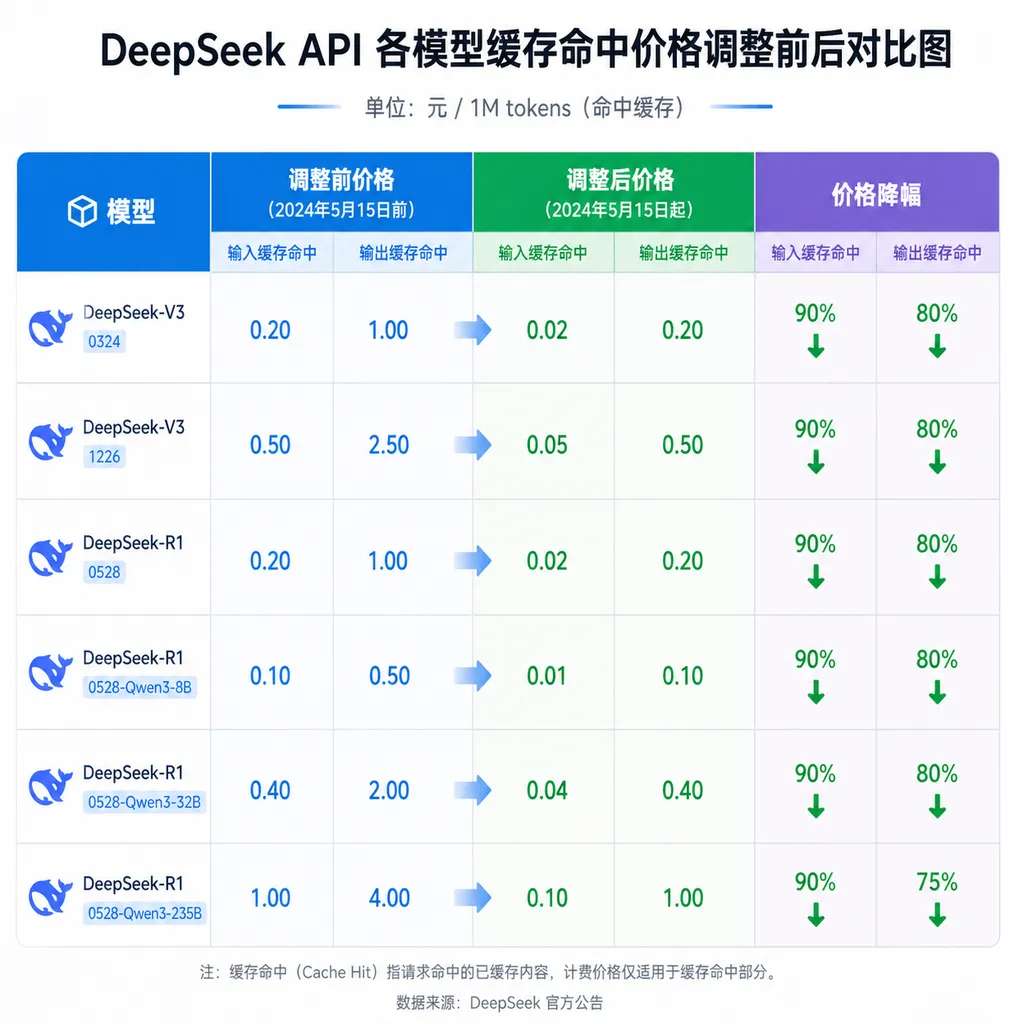
到底便宜了多少?
先把账算清楚。
DeepSeek 的 API 计费分三个部分:输入(缓存未命中)、输入(缓存命中)、输出。这次调整只动了中间那一项——缓存命中的输入 token 价格。
以 DeepSeek 此前公布的缓存命中基准价 1 元/百万 tokens 为参考,一折之后就是 0.1 元/百万 tokens。换算成美元大约是 $0.014/百万 tokens。
这是什么概念?
做个横向对比:
| 模型 | 输入价格(缓存命中) | 输入价格(无缓存) | |------|---------------------|--------------------| | DeepSeek V4 Pro(调整后) | ≈ 0.1 元/百万 tokens | 按首发价 | | GPT-4o | $1.25/百万 tokens(Cached) | $2.50/百万 tokens | | Claude 3.5 Sonnet | $1.50/百万 tokens(Cached) | $3.00/百万 tokens | | Gemini 1.5 Pro | $0.315/百万 tokens(Cached) | $1.25/百万 tokens |
即便考虑汇率差异,DeepSeek 的缓存命中价格也比主流闭源模型便宜了一到两个数量级。Gemini 1.5 Pro 的缓存价格已经算是业界较低的了,DeepSeek 这个价格大概是它的 1/30。
当然,模型能力不能只看价格。但 DeepSeek V4 Pro 在多个基准测试上已经展现出与 GPT-4o 级别模型竞争的实力,这个性价比确实没什么可挑的。
缓存命中为什么重要?
如果你只是偶尔调一次 API 玩玩,缓存命中率对你来说可能无感。但对于生产环境中的开发者来说,这个数字直接决定了月底账单的厚度。
在真实的 API 调用场景中,输入 token 的重复率远比你想象的高:
场景一:System Prompt 复用。 绝大多数应用都有一个固定的系统提示词,可能几百到几千 tokens。每次请求都要发送一遍,但内容完全相同。缓存命中后,这部分成本直接降到 1/10。
场景二:多轮对话。 这是缓存的主战场。一个 10 轮对话,第 10 轮请求需要把前 9 轮的内容全部重新发送。假设每轮平均 500 tokens,到第 10 轮时你的输入里有 4500 tokens 是重复的,只有最后一轮的用户输入是新的。缓存命中率轻松超过 80%。
场景三:RAG 应用中的文档引用。 很多 RAG 场景会把检索到的文档片段塞进 prompt,同一份文档被不同用户反复引用的概率很高。
场景四:批量处理。 用同一个 prompt 模板处理大量数据时,模板部分的 token 每次都在重复。
DeepSeek 官方此前的技术博客提到过一个极端案例:128K 输入且大部分重复的请求,首 token 延迟从 13 秒降到了 500 毫秒。这不光是省钱的问题,还直接改善了用户体验。
所以这次降价的实际影响,取决于你的应用缓存命中率有多高。对于多轮对话类应用,综合成本下降 50%-70% 是完全可能的。对于有大量固定 prompt 的批处理场景,降幅可能更大。
DeepSeek 的缓存机制:技术上怎么做到的?
要理解为什么 DeepSeek 敢把缓存价格压到这么低,得先看看它的缓存机制是怎么工作的。
DeepSeek 采用的是硬盘级 KV Cache 缓存,这在业界是比较独特的。大多数厂商的缓存是在 GPU 显存或内存中进行的,容量有限、成本高昂。DeepSeek 把缓存下沉到了分布式硬盘阵列,利用的是 MLA(Multi-head Latent Attention)架构的一个关键优势:KV Cache 体积极小。
传统 Transformer 的 KV Cache 随着上下文长度线性增长,存储和传输成本很高。而 DeepSeek V2 提出的 MLA 结构通过低秩压缩,将 KV Cache 的大小压缩了数倍,使得用相对廉价的硬盘存储来缓存变得可行。
从开发者的角度来看,这套缓存是完全透明的:
- 无需修改代码,无需更换接口
- 系统自动匹配前缀,自动命中缓存
- 按实际命中情况计费
- 缓存存储本身不收费
需要注意的一个限制:缓存匹配是从第 0 个 token 开始的前缀匹配。也就是说,只有两个请求的输入从头部开始完全相同,相同的部分才能被缓存命中。如果你在 prompt 中间插入了不同的内容,后面即使相同也无法命中。
这意味着,想要最大化缓存命中率,你需要把固定内容放在 prompt 的前面,变化内容放在后面。比如 system prompt 放最前,然后是历史对话,最后是当前用户输入。这本身也符合大多数应用的 prompt 组织习惯。
另外,缓存系统以 64 tokens 为最小存储单元,不足 64 tokens 的内容不会被缓存。官方也明确说了,缓存是「尽力而为」,不保证 100% 命中。
在 API 返回的 usage 字段中,你可以通过两个字段实时监控缓存情况:
prompt_cache_hit_tokens:缓存命中的 token 数prompt_cache_miss_tokens:缓存未命中的 token 数
这两个字段对于成本监控和 prompt 优化都非常有用。如果你发现命中率持续偏低,可能需要检查一下 prompt 的组织方式。
降价背后的逻辑
有人可能会问:DeepSeek 这么降价,到底图什么?
从商业角度看,有几个可能的解读。
第一,缓存命中的边际成本确实很低。 缓存命中意味着这部分 token 不需要经过 GPU 计算,只需要从硬盘读取 KV Cache。硬盘存储和读取的成本比 GPU 推理低了不止一个数量级,所以即使收 1/10 的价格,DeepSeek 在这部分依然有利润空间——或者至少不亏。
第二,低价策略是为了抢占开发者生态。 API 定价是一场心理战。当开发者评估一个新项目的技术选型时,成本是绕不过去的考量。DeepSeek 用极低的价格降低开发者的试用门槛,一旦开发者基于 DeepSeek 的 API 构建了应用,迁移成本就会形成粘性。
第三,这是对国内外竞品的持续施压。 国内市场上,通义千问、文心一言、GLM 等都在争夺 API 开发者。国际市场上,OpenAI、Anthropic、Google 的定价已经在持续下降。DeepSeek 选择在缓存这个维度上打到极致,等于是在说:你们跟不跟?
从 DeepSeek 过去一年的定价历史来看,降价已经成了某种常态:
- 2024 年 8 月,首次推出硬盘缓存,缓存命中价格为 0.1 元/百万 tokens
- 2025 年 2 月,推出错峰优惠,夜间时段 API 价格最高降 75%
- 2025 年 9 月,新模型上线带动整体 API 价格下降 50% 以上
- 2026 年 4 月,V4 Pro 限时 2.5 折 + 缓存永久一折
每次降价的幅度都不小,而且越来越频繁。这要么说明 DeepSeek 在推理效率上的优化速度确实很快,要么说明他们在用价格换市场份额——大概率两者兼有。
对开发者的实际影响
说点实在的。这次降价对不同类型的开发者影响不同。
对个人开发者和小团队: 影响有限但正面。如果你的月调用量在几百万 tokens 级别,账单本来就不高,降价后可能从几块钱变成几毛钱。心理上更爽,但不会改变你的技术决策。
对中型 SaaS 产品: 影响显著。假设你的产品日均处理 10 万次对话请求,每次请求平均 2000 tokens 输入,其中 70% 是缓存命中。降价前后的月成本差异可能在数千到数万元级别。这个幅度足以影响产品的定价策略和利润率。
对大型企业和高频调用场景: 影响最大。如果你在做智能客服、文档处理、代码辅助等高频场景,每天的 token 消耗可能在数十亿级别。缓存命中部分降到 1/10,月度成本节省可能达到六位数。
值得一提的是,这次降价也让 DeepSeek 在 Agent 和长链推理场景中的成本优势更加明显。Agent 应用通常涉及多步推理,每一步都需要把之前的上下文重新输入,缓存命中率天然就高。在这类场景中,DeepSeek 的综合调用成本可能只有 GPT-4o 的 1/50 甚至更低。
竞争格局:价格战还能打多久?
大模型 API 的价格战已经持续了一年多。从 2024 年年中开始,几乎每个月都有厂商宣布降价。DeepSeek 不是唯一在降价的,但它降得最狠、最频繁。
这场价格战的底层逻辑是推理成本的持续下降。更高效的模型架构(如 MLA、MoE)、更好的推理框架(如 vLLM、TensorRT-LLM)、更便宜的硬件(如国产 AI 芯片的逐步成熟),都在推动单位 token 的生产成本走低。
但价格战也有副作用。当 API 价格低到一定程度,厂商的收入可能无法覆盖研发投入。对于 DeepSeek 这样有幻方量化背景的公司来说,短期内可能不需要靠 API 收入盈利,但长期来看,可持续的商业模式仍然是个问题。
对开发者来说,价格战当然是好事。但也要注意一个风险:如果你的整个产品成本结构都建立在某家厂商的超低价格之上,一旦对方调整策略(涨价、限流、停服),你的商业模式可能会受到冲击。做好多模型适配、保留切换能力,始终是明智的。
目前主流模型的 API 都兼容 OpenAI 格式,像 OpenAI Hub 这类聚合平台也支持一个 Key 调用 DeepSeek 在内的多家模型,切换成本已经很低了。在享受低价的同时保持灵活性,是当下比较务实的策略。
总结
DeepSeek 这次缓存永久一折的调整,单独看是一个定价策略的更新,放在整个行业背景下看,是大模型 API 价格持续走低的又一个标志性事件。
对开发者来说,核心信息就一句话:如果你的应用有大量重复输入(多轮对话、固定 prompt、批量处理),现在用 DeepSeek 的成本又低了一大截。
至于「梁圣」什么时候再降价——按照这个节奏,可能用不了太久。
参考来源
- DeepSeek API 再次降价:缓存命中降至 1 折 — Linux.do 社区讨论,确认全系列模型缓存命中价格降至首发价 1/10
- 梁圣这是干什么?缓存永久一折啦! — 社区热议,指出缓存一折为永久性调整
- deepseek 官方优惠更新 缓存1折(更新:永久1折) — 最早发现并确认缓存永久降价的帖子
- DeepSeek V4 系列输入缓存价格降至首发价格 1/10 — 引用官方文档的社区讨论
- DeepSeek API价格砍半,惠及企业和个人用户 — 知乎专栏,回顾 DeepSeek 历次降价
- DeepSeek API 推出磁盘上下文缓存 — Reddit 社区对 DeepSeek 缓存技术的讨论
