自建中转池接通GPT-5.5:一场关于性能与成本的硬核实验

一位开发者在物理机上自建API中转池并成功接入GPT-5.5,我们从这个案例出发,拆解自建中转、开源网关、聚合平台三条路径的真实成本与工程代价。
有人在 LINUX DO 论坛发了个帖子,说自己拿物理机搭了个中转池,把 GPT-5.5 接通了,顺手搞了个抽奖送额度。帖子不长,36 个人参与,看起来就是个人折腾的小项目。
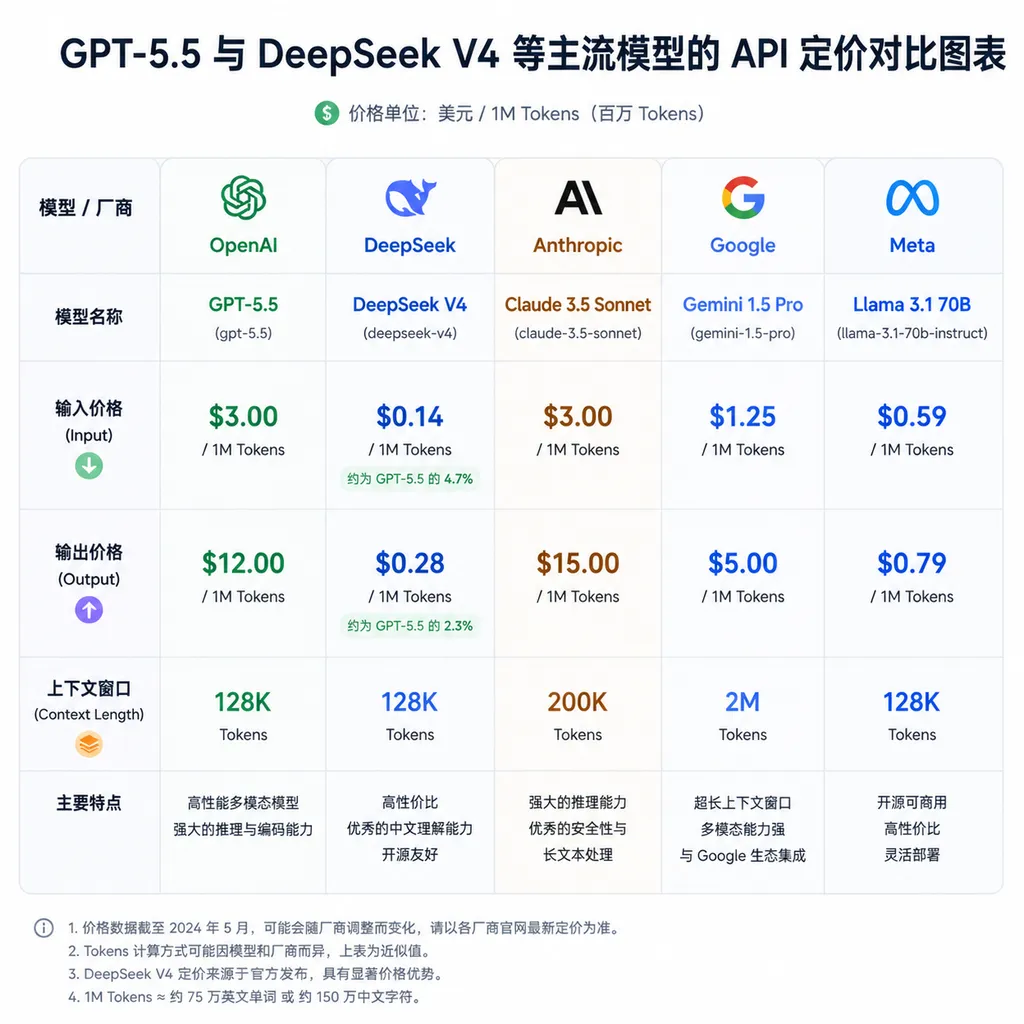
但这件事背后藏着一个越来越普遍的开发者困境:GPT-5.5 发布后,API 定价再次刷新天花板——输出端每百万 Token 的价格已经逼近 1230 元人民币。对于想在生产环境跑 Agent 工作流的独立开发者来说,这个数字足以劝退大多数人。
自建中转池,本质上是在官方 API 和终端调用之间插入一层自己控制的代理网关。目的很直接:降低延迟、统一接口、在多个 Key 之间做负载均衡,顺便把成本摊薄一点。
这不是什么新鲜事。但 GPT-5.5 的到来,让这件事的工程复杂度和经济账都变了。
为什么现在大家都在折腾中转
先说清楚背景。
2026 年的大模型 API 市场,格局已经和两年前完全不同。GPT-5.5 在推理能力上确实有质的飞跃——它是 OpenAI 明确定位为「智能体原生大脑」的模型,在 Lean 形式化验证、生物信息学辅助、多步推理等场景上的表现远超前代。官方宣称 Token 效率提升了 30%,意思是同样的任务用更少的 Token 就能完成。
但价格也翻了倍。
与此同时,DeepSeek V4-Flash 的输出价格只有 1.91 元/百万 Token,和 GPT-5.5 Pro 之间差了 643 倍。这个价差不是打折和原价的区别,是两个完全不同的量级。
所以开发者面临的选择很现实:要么咬牙用官方 API 承受高成本,要么想办法在中间环节做优化。自建中转池就是后者的一种实现方式。
自建中转池到底在建什么
这位论坛老哥没有公开具体的技术栈(为了遵守版规,连站点链接都没放),但从帖子的描述和社区讨论中可以还原出大致的架构。
一个典型的自建中转池包含以下几层:
- 反向代理层:Nginx 或 Caddy 做入口,处理 TLS 终止和基本的流量调度
- 网关逻辑层:负责鉴权、请求改写、模型路由、Key 轮转
- 上游连接池:维护多个 API Key 的连接,做负载均衡和限流规避
- 计费与日志:记录每个请求的 Token 消耗,方便分摊成本
用大白话说,就是你在自己的服务器上跑一个程序,它对外暴露一个兼容 OpenAI 格式的 API 端点,对内持有多个官方 API Key,请求进来后自动选一个可用的 Key 转发出去。
这个思路并不复杂。真正的难度在细节里。
Key 轮转与限流规避
OpenAI 对每个 API Key 有严格的速率限制(RPM 和 TPM)。GPT-5.5 的限制比前代更紧,尤其是 Pro 级别的端点。单个 Key 在高并发场景下很容易触发 429 错误。
自建中转池的核心价值之一,就是在多个 Key 之间做智能轮转。最简单的实现是 Round Robin,但实际生产中你需要更精细的策略:
import time
import threading
from dataclasses import dataclass, field
@dataclass
class KeySlot:
key: str
rpm_remaining: int = 60
tpm_remaining: int = 800000
last_reset: float = field(default_factory=time.time)
cooldown_until: float = 0.0
class KeyPool:
def __init__(self, keys: list[str]):
self.slots = [KeySlot(key=k) for k in keys]
self.lock = threading.Lock()
def acquire(self, estimated_tokens: int = 1000) -> KeySlot | None:
now = time.time()
with self.lock:
for slot in self.slots:
# 每分钟重置计数
if now - slot.last_reset >= 60:
slot.rpm_remaining = 60
slot.tpm_remaining = 800000
slot.last_reset = now
# 跳过冷却中的 Key
if now < slot.cooldown_until:
continue
if slot.rpm_remaining > 0 and slot.tpm_remaining >= estimated_tokens:
slot.rpm_remaining -= 1
slot.tpm_remaining -= estimated_tokens
return slot
return None # 所有 Key 都不可用
def report_429(self, slot: KeySlot):
"""收到 429 后让该 Key 冷却 30 秒"""
slot.cooldown_until = time.time() + 30
这段代码展示的是最基础的 Key 池管理逻辑。实际部署中你还得处理 Key 失效、额度耗尽、不同模型不同限额等情况。每多一个边界条件,代码复杂度就上一个台阶。
延迟优化
自建中转池的另一个核心诉求是降低延迟。
GPT-5.5 的推理集群部署在北美,国内直连的网络路径跳数多、跨洋链路抖动概率高。根据掘金上一篇多模型 API 接入的复盘文章,直连 OpenAI 官方 API 的 P50 延迟在 1.8 秒左右,P99 可以飙到 5.2 秒。晚高峰时段(和北美工作时间重叠)更是灾难。
自建中转池如果部署在网络条件好的机房,理论上可以通过以下方式优化:
- 连接复用:维持与上游的长连接,省掉每次请求的 TLS 握手开销
- 就近接入:如果物理机在香港或日本,到 OpenAI 端点的 RTT 本身就短很多
- 预热与缓存:对于相同 prompt 的请求做结果缓存(当然这在 LLM 场景下命中率很低)
但这里有个现实问题:一台物理机的网络条件是固定的。你不可能像专业的聚合平台那样在全球多个节点部署边缘代理。所以自建方案在延迟优化上的天花板是明确的。
三条路径的真实对比
自建中转池只是解决多模型调用问题的路径之一。把市面上的方案摊开来看,开发者大致有三条路可以走。
路径一:纯自建,从零搭起
就是这位论坛老哥做的事。自己买机器、自己写网关逻辑、自己管理 Key 池。
优点很明显:完全可控,没有中间商,数据不经过第三方。对于安全性要求极高的场景(比如处理敏感数据的企业内部工具),这可能是唯一的选择。
代价也很明显:
- 初始投入:物理机成本、带宽成本、域名和证书
- 持续维护:每次上游 API 变更都要跟进适配。OpenAI 在过去一年里至少改了三次接口规范
- 稳定性风险:单点故障没有兜底。凌晨三点机器挂了,你的所有下游服务都跟着挂
适合谁?有运维能力、对数据隔离有硬性要求、调用量大到能摊薄固定成本的团队。
路径二:开源网关,站在前人肩膀上
社区里已经有不少成熟的开源方案。最近比较火的是 Sub2API,一个拿了 15K Star 的开源 AI 网关项目。
Sub2API 的核心思路是把 AI 订阅变成可共享的 API。你把自己的 Claude Max、GPT Pro 等订阅账号接入网关,平台自动做负载均衡和计费,然后通过生成 API Key 的方式分发给多个用户。
技术栈是 Go 后端 + Vue 3.4 前端,部署门槛不算高。它有几个设计上的亮点:
- Sticky Session:同一用户的连续请求路由到同一个上游账号,避免上下文丢失。这对 Claude Code 这种长会话场景很关键
- 自动限流切换:一个账号触发速率限制时,自动切到下一个
- 兼容主流工具:Claude Code、Cursor、Codex CLI 改个 Base URL 就能用
但 Sub2API 解决的问题和纯自建中转池不完全一样。它更偏向「拼车」场景——几个人合买一个 Max 订阅,公平分账。而不是面向生产环境的高可用 API 网关。
用它来跑 GPT-5.5 的 Agent 工作流?可以,但你得自己处理高可用、监控告警、故障恢复这些生产级的需求。开源项目给你的是 80% 的功能,剩下 20% 的生产化工作往往占掉 80% 的时间。
路径三:聚合平台,花钱买时间
第三条路是直接用商业化的 API 聚合平台。这类平台的共同特点是:统一接口格式(通常兼容 OpenAI SDK)、单一 Key 调用多个模型、国内网络优化。
根据掘金那篇复盘文章的实测数据,聚合平台的延迟表现相当亮眼:
| 指标 | 直连官方 API | 自建 Fallback | 聚合平台 | |------|-------------|--------------|----------| | P50 延迟 | ~1.8s | ~2.0s | ~300ms | | P99 延迟 | ~5.2s | ~3.5s | ~800ms | | 维护成本 | 低(但不稳定) | 高 | 几乎为零 |
300ms 的 P50 延迟,和直连的 1.8 秒比,差了 6 倍。这个差距在交互式应用里是用户体感层面的区别——前者感觉「秒回」,后者感觉「在转圈」。
聚合平台能做到这个延迟,核心原因是它们在靠近上游 API 端点的位置部署了边缘节点,国内用户的请求先到国内节点,再通过优化过的专线到达上游。这种基础设施投入不是个人开发者能复制的。
像 OpenAI Hub 这类平台就是走的这个路线——一个 Key 覆盖 GPT、Claude、Gemini、DeepSeek 等主流模型,接口格式统一兼容 OpenAI SDK,国内直连。对于独立开发者来说,省掉的不只是网络优化的工程量,还有每次上游 API 变更时的适配成本。
当然,代价是你的所有请求都经过第三方。数据安全和服务商锁定是需要评估的风险。
成本账怎么算
抛开技术细节,最终决定走哪条路的往往是一笔经济账。
假设你是一个独立开发者,每天跑 GPT-5.5 大概消耗 50 万 Token(输入输出合计),一个月大约 1500 万 Token。
直连官方 API 的成本:
GPT-5.5 Pro 的输出价格约 1229 元/百万 Token。假设输入输出比例 3:1,输入价格按输出的 1/4 估算,月成本大约在 6000-8000 元区间。这还没算偶尔的重试和浪费。
自建中转池的成本:
API 费用不变(你还是在调官方接口),额外加上:
- 物理机或云服务器:500-2000 元/月(取决于配置和机房位置)
- 带宽:200-500 元/月
- 你自己的时间:无价(或者说,很贵)
自建中转池不会帮你省 API 费用。它省的是延迟和稳定性带来的隐性成本——比如因为超时导致的重试、因为 429 导致的请求失败。如果你的 Key 池够大,通过轮转可以把有效吞吐量提上去,间接降低单位成本。
开源网关(拼车模式)的成本:
如果你和 4 个朋友合买一个 GPT-5.5 Pro 的高额度套餐,用 Sub2API 做分发,人均成本可以降到原来的 1/5。但前提是你们的使用时间错开,不会同时打满限额。
这个模式的风险在于:一旦某个人的用量暴增,其他人的体验就会受影响。而且合买账号在 OpenAI 的 ToS 里处于灰色地带。
聚合平台的成本:
通常在官方价格基础上加一个服务费比例(各平台不同)。但考虑到延迟优化带来的重试减少、统一接口带来的开发效率提升,综合成本未必更高。尤其是当你需要同时调用多个模型时——自己维护 OpenAI + Anthropic + Google 三套 SDK 的适配层,光是工程时间就够你多付好几个月的服务费了。
一个容易被忽略的问题:接口碎片化
这位论坛老哥只接了 GPT-5.5 一个模型。但现实中,大多数开发者的工作流不会只用一个模型。
典型的多模型场景:GPT-5.5 做复杂推理、Claude 做代码审查、Gemini 处理多模态、DeepSeek 跑性价比任务。四个模型,四套 API 规范,四种鉴权方式:
- OpenAI:Bearer Token
- Anthropic:
x-api-key头部 - Google:OAuth 或特定端点格式
- DeepSeek:兼容 OpenAI 格式(但有自己的扩展字段)
每新增一个模型,就是一套独立的适配代码。掘金那篇文章的作者说得很直白:「独自维护多套 SDK 的适配层对独立开发者而言负担过重。每当某家厂商迭代 API 版本,就得同步跟进修改,这种工程消耗已偏离了业务开发的主线。」
自建中转池如果要覆盖多个模型,工程量会指数级增长。这也是为什么很多人最终还是选择了聚合方案——不是因为自建做不到,而是因为做到之后还要持续维护,这个持续成本才是真正的杀手。
实操建议
如果你看完这些还是想自己搭一个中转池,以下是一些实操层面的建议:
机器选择:优先考虑香港或日本的轻量云服务器,到 OpenAI 端点的 RTT 通常在 50-80ms,比国内直连好很多。物理机的优势在于带宽稳定,但运维成本高。如果不是对延迟有极致要求,云服务器够用。
网关框架:不要从零写。OpenResty(基于 Nginx + Lua)或者直接用 Go 写一个轻量网关是比较主流的选择。如果你熟悉 Python,FastAPI + httpx 的异步方案也能跑,但在高并发下性能不如前两者。
Key 管理:至少准备 5 个以上的 API Key 做轮转。GPT-5.5 的 RPM 限制比较紧,单 Key 在并发场景下很容易触顶。建议实现一个带健康检查的 Key 池,自动剔除失效或欠费的 Key。
监控:Prometheus + Grafana 是标配。重点监控指标:每个 Key 的 429 触发频率、P50/P99 延迟、Token 消耗速率。没有监控的中转池就是在裸奔。
容灾:至少做一个模型级别的 Fallback。GPT-5.5 挂了自动切到 GPT-5.4 或 Claude,总比整个服务不可用强。
# 一个简化的中转池配置示例
upstream:
models:
- name: gpt-5.5
endpoint: https://api.openai.com/v1/chat/completions
keys:
- sk-key1
- sk-key2
- sk-key3
max_rpm_per_key: 60
max_tpm_per_key: 800000
fallback: gpt-5.4
- name: gpt-5.4
endpoint: https://api.openai.com/v1/chat/completions
keys:
- sk-key4
- sk-key5
max_rpm_per_key: 120
max_tpm_per_key: 2000000
server:
listen: 0.0.0.0:8080
tls: true
cert: /etc/ssl/certs/gateway.pem
key: /etc/ssl/private/gateway.key
rate_limit:
strategy: token_aware # 根据预估 Token 数选择 Key
cooldown_on_429: 30s
health_check_interval: 60s
这件事的本质
回到那个论坛帖子。36 个人参与抽奖,奖品是一些 GPT-5.5 的调用额度。规模不大,但它代表了一个真实的趋势:越来越多的开发者不满足于当 API 的纯消费者,开始在中间层做文章。
这和几年前大家折腾 VPS 搭梯子的逻辑很像——官方通道太贵或太慢,就自己建一条。区别在于,AI API 中转的技术门槛更高,维护成本也更高。
对于大多数独立开发者,我的判断是:除非你有明确的数据隔离需求或者纯粹享受折腾的乐趣,否则自建中转池的 ROI 并不高。你花在维护网关、适配接口、处理故障上的时间,完全可以用来多写两个功能、多跑几个实验。
选择哪条路,最终取决于你把自己的时间定价多少。
如果你的时间值 200 块一小时,而自建方案每周要多花你 5 小时维护,那一个月就是 4000 块的隐性成本。这个数字,可能已经超过了聚合平台的服务费。
工具是为人服务的,不是反过来。
参考来源:
- LINUX DO 论坛:自建中转池接通 GPT-5.5 实测分享 — 原始帖子,包含自建中转池的背景和社区讨论
- 掘金:多模型 API 接入的工程困境复盘 — 详细对比了直连、自建 Fallback、聚合平台三种方案的延迟与稳定性数据
- 掘金:Sub2API 开源 AI 网关介绍 — 15K Star 的开源项目,实现 AI 订阅共享和负载均衡
