有道云笔记押注AI知识管理,LLM-Wiki能跑通吗?

网易有道云笔记发布 LLM-Wiki 技能套件,主打零门槛将碎片笔记转化为结构化知识库,同步上架 OpenClaw 与 LobsterAI 技能市场。这是笔记工具向 AI 知识管理转型的又一次尝试。
有道云笔记押注 AI 知识管理,LLM-Wiki 能跑通吗?
4 月 27 日,网易有道云笔记正式推出 LLM-Wiki 技能套件,同步首发至 OpenClaw 和网易有道龙虾(LobsterAI)技能市场。官方给出的核心卖点很直接——零技术背景,5 分钟把你积攒多年的碎片笔记变成一个结构化知识库。
听起来很诱人。但这件事到底是真需求还是伪命题,值得拆开来看。
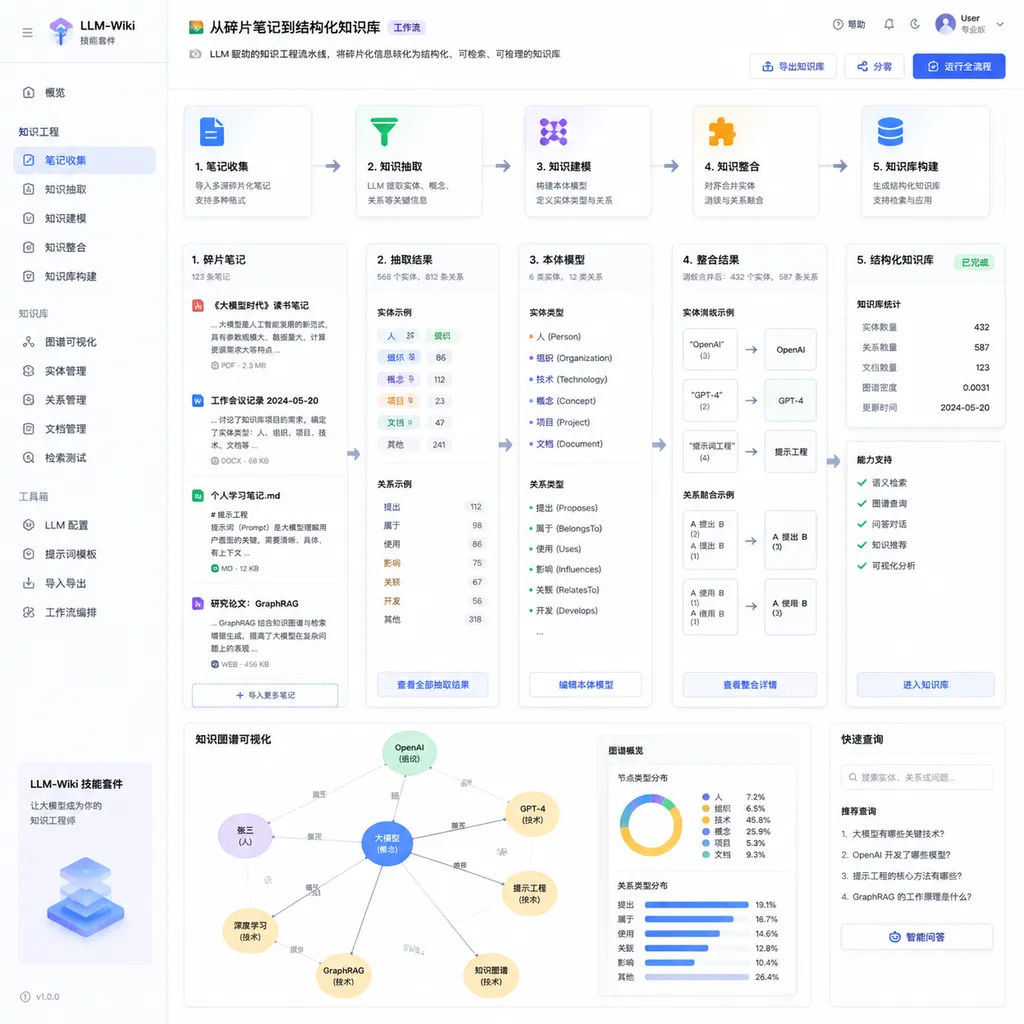
先说清楚它在解决什么问题
做开发的人大概都有这个体会:你的笔记工具里躺着几百上千条内容,有从网页剪藏的技术文章,有自己随手写的 debug 记录,有会议纪要,有读论文时的批注。它们分散在不同的文件夹、标签、甚至不同的笔记本里。
时间一长,这些内容就变成了「数字垃圾」——你知道自己记过,但找不到;找到了,也很难把相关的内容串起来。
传统的解决方案是什么?手动整理。建目录、打标签、写索引。勤快的人能维护一段时间,但绝大多数人坚持不了三个月。
后来出现了双链笔记(Obsidian、Logseq、Roam Research),试图用链接关系自动构建知识图谱。思路是对的,但门槛也不低——你得改变记笔记的习惯,主动建立链接,而且最终的知识图谱质量完全取决于你投入的精力。
有道云笔记这次的 LLM-Wiki,本质上是想用大模型来替代「人工整理」这个环节。你不需要手动分类、打标签、建链接,AI 帮你读完所有笔记,自动提取主题、归纳结构、生成一个类似 Wiki 的知识库。
这个方向不新鲜。Notion AI、Mem、Reflect 都在做类似的事。但有道云笔记的切入角度有点不一样——它不是在笔记工具里内嵌一个 AI 助手,而是把这个能力做成了一个独立的「技能套件」,发布到技能市场上。
「技能套件」这个形态意味着什么
这里需要解释一下背景。
有道云笔记把 LLM-Wiki 发布到了两个平台:OpenClaw 和 LobsterAI(龙虾)技能市场。这两个平台的定位类似于 GPTs Store 或者 Coze 的插件市场——开发者或产品团队把基于大模型的能力封装成「技能」,用户可以直接调用。
选择这种形态而不是直接做成有道云笔记的内置功能,背后的考量可能有几层:
第一,降低试错成本。作为一个独立技能发布,如果市场反馈不好,调整或下架都很灵活,不会影响主产品的稳定性。
第二,触达更多用户。不是所有人都用有道云笔记,但如果你用其他笔记工具,理论上也可以通过技能市场调用 LLM-Wiki 的能力来处理你导出的内容。这比绑死在自家产品里,想象空间更大。
第三,试水技能生态。网易有道显然在押注 AI Agent 生态,LobsterAI 技能市场就是这个战略的一部分。LLM-Wiki 既是一个产品,也是一个「样板间」——向其他开发者展示:你看,我们自己的团队就在用这个平台发布技能。
不过话说回来,技能市场这个形态目前整体还处于早期。OpenAI 的 GPTs Store 上线一年多,爆款寥寥;国内的各种插件市场、技能市场也大多不温不火。LLM-Wiki 选择这个渠道,能获得多少自然流量,要打个问号。
「5 分钟建知识库」到底靠不靠谱
官方宣传的核心场景是这样的:用户提一个问题或给一个指令,AI 就能把你的数百篇零散收藏自动整理成结构化的 Wiki 页面。
这个「5 分钟」的说法,大概率指的是用户侧的操作时间——你只需要选择要处理的笔记范围,输入一个指令,然后等结果。真正的处理时间取决于笔记数量和模型推理速度。
从技术实现的角度,这件事并不神秘。拆解一下,大致是这么几步:
- 内容提取与清洗:把不同格式的笔记(富文本、Markdown、网页剪藏、图片 OCR 等)统一转成纯文本
- 主题聚类:用 Embedding 模型对所有笔记做向量化,然后通过聚类算法(比如 K-Means 或层次聚类)把相关内容归到一起
- 结构生成:用 LLM 对每个聚类生成摘要、标题、层级关系,组装成 Wiki 的目录结构
- 内容填充:对每个 Wiki 条目,从原始笔记中提取关键信息,由 LLM 改写成连贯的知识条目
- 交叉引用:识别不同条目之间的关联,自动建立内部链接
这套流程在技术上是成熟的,每一步都有现成的方案。难点在于效果的稳定性——
聚类的粒度怎么控制?太粗了,把不相关的内容混在一起;太细了,一个小知识点就单独成页,碎片化问题没解决反而加重了。
LLM 改写的准确性怎么保证?你的原始笔记里可能有错误信息、过时内容、甚至互相矛盾的记录。模型是原样保留还是会「自作主张」地修正?如果修正了,用户怎么知道哪些是原始内容、哪些是 AI 生成的?
还有一个很现实的问题:知识库生成之后怎么维护?你每天还在记新笔记,知识库是自动增量更新,还是需要手动重新生成?如果是前者,技术复杂度会高很多;如果是后者,用户很快就会懒得操作,知识库又变成了一个「生成一次就吃灰」的东西。
这些问题,目前公开的信息里都没有提到。
放在行业里看:笔记工具的 AI 转型焦虑
有道云笔记做这件事,不是心血来潮,而是整个笔记工具赛道都在面临同一个问题:大模型时代,笔记工具的价值在哪里?
过去十年,笔记工具的核心价值是「存储」和「组织」。你把信息存进来,用文件夹、标签、搜索来管理。但现在,当你可以随时问 AI 任何问题并得到即时回答时,「存储信息」这件事本身的价值就被稀释了。
为什么还要费劲把一篇技术文章存到笔记里?下次遇到问题直接问 ChatGPT 不就行了?
笔记工具厂商当然意识到了这个威胁。所以我们看到了一波集体转型:
- Notion 推出了 Notion AI,把大模型能力嵌入到文档编辑、数据库查询、内容生成的各个环节
- Obsidian 社区涌现了大量 AI 插件,做本地知识库问答、自动打标签、智能链接推荐
- 印象笔记(Evernote)被 Bending Spoons 收购后也在加 AI 功能,虽然动作慢了不少
- 飞书文档、语雀等国内产品同样在整合 AI 能力
有道云笔记的 LLM-Wiki,本质上也是这波转型浪潮中的一个动作。它试图回答的问题是:你存在我这里的那些笔记不是垃圾,AI 可以帮你把它们变成有价值的知识资产。
这个叙事是成立的。但能不能做好,取决于执行层面的很多细节。
对开发者来说,有什么值得关注的
如果你是开发者,LLM-Wiki 这个产品本身可能对你的吸引力有限——大多数开发者已经有了自己的知识管理方案,不管是 Obsidian + Git、Logseq、还是纯 Markdown 文件。
但它背后的几个趋势值得留意:
1. AI 技能市场的生态正在成型
OpenClaw、LobsterAI 这类技能市场虽然还早期,但方向是清晰的——把 AI 能力模块化、可组合、可分发。如果你在做 AI 相关的产品或工具,这些平台可能是一个值得关注的分发渠道。
2. 「非结构化数据 → 结构化知识」是一个通用需求
LLM-Wiki 做的是笔记场景,但同样的技术路径可以迁移到很多地方:企业内部文档整理、客服知识库构建、技术文档自动生成、甚至代码仓库的文档化。如果你在做 ToB 产品,这个方向值得想想。
3. 端侧知识管理 vs 云端知识管理
有道云笔记是云端产品,你的笔记数据存在网易的服务器上。LLM-Wiki 的处理大概率也是在云端完成的。这对于个人隐私敏感的用户来说是个顾虑。
相比之下,Obsidian + 本地 LLM(比如用 Ollama 跑一个小模型)的方案虽然折腾,但数据完全在本地。对于开发者来说,这可能是更有吸引力的选择。
当然,本地方案的问题是模型能力有限。用一个 7B 或 13B 的模型做知识整理,效果和 GPT-4 级别的模型差距还是很明显的。这是一个 trade-off。
几个没回答的问题
作为一个产品发布,LLM-Wiki 目前披露的信息还是太少了。有几个关键问题,决定了这个产品到底能不能用起来:
底层用的什么模型? 是有道自研的子曰大模型,还是调用了第三方的 API?模型的选择直接影响知识整理的质量上限。
支持多大规模的笔记处理? 5 分钟处理几百篇笔记,如果我有几千篇呢?几万篇呢?Token 限制和成本怎么控制?
生成的知识库格式是什么? 是只能在有道云笔记里查看,还是可以导出为 Markdown、HTML 等通用格式?如果锁死在自家生态里,对用户来说就是一个新的数据孤岛。
定价模式是什么? 免费还是付费?如果付费,是按次收费还是订阅制?对于一个「技能套件」来说,定价策略直接决定了用户的尝试意愿。
隐私和数据安全怎么处理? 笔记里可能包含非常私密的信息——工作笔记、个人日记、账号密码。这些数据在处理过程中是否会被用于模型训练?有没有明确的隐私承诺?
这些问题不回答清楚,开发者群体很难真正买单。
说点直接的判断
有道云笔记做 LLM-Wiki 这件事,方向没问题,时机也对。笔记工具不拥抱 AI 就是等死,这一点行业已经有共识。
但「5 分钟建知识库」这个卖点,更像是一个营销话术而不是一个产品承诺。知识管理从来不是一个「一键搞定」的事情,它需要持续的维护和迭代。如果 LLM-Wiki 只能做到「一次性生成」而没有后续的增量更新、人工校正、版本管理等能力,那它的实际价值会大打折扣。
另外,选择技能市场作为首发渠道,说明有道云笔记团队对这个功能的定位还比较谨慎——它更像是一个实验性质的探索,而不是一个 All-in 的战略级产品。
对于普通用户来说,如果你本身就是有道云笔记的重度用户,试试无妨。5 分钟的时间成本不高,看看 AI 能把你的笔记整理成什么样,至少能帮你重新审视一下自己的知识积累。
对于开发者来说,与其关注这个产品本身,不如关注它背后的技术思路。「非结构化内容的自动结构化」是一个有广泛应用场景的能力,不管是用现成的技能套件还是自己搭一套 RAG pipeline,这个方向都值得投入时间研究。
笔记工具的 AI 化才刚刚开始,LLM-Wiki 不会是最后一个尝试。谁能真正解决「知识管理的最后一公里」问题,谁就能在这个赛道里跑出来。目前来看,还没有人做到。
本文不构成任何产品推荐或投资建议。
