阿里HappyHorse 1.0灰测:音视频同生的黑马来了

阿里巴巴视频生成模型 HappyHorse 1.0 于 4 月 27 日开启灰测,凭借原生多模态架构实现音视频一次性联合生成,此前已登顶 Artificial Analysis 双榜第一,直接叫板 Seedance 2.0 和 Kling。
一匹「黑马」正式跑进赛道
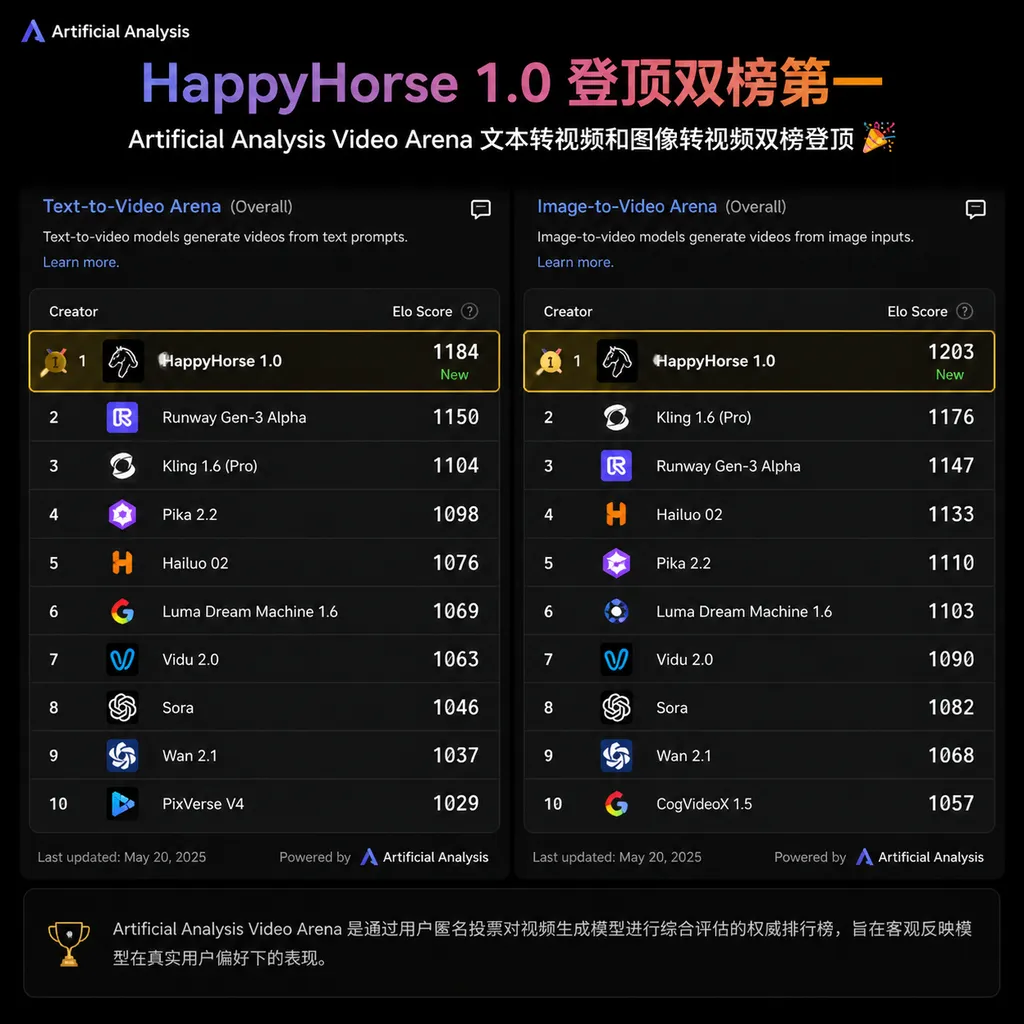
4 月 27 日,阿里巴巴视频生成模型 HappyHorse 1.0 正式开启灰度测试。这个名字对关注 AI 视频生成的开发者来说并不陌生——早在 4 月初,一个身份不明的模型突然空降 Artificial Analysis AI Video Arena 排行榜,在文本转视频(Text-to-Video)和图像转视频(Image-to-Video)两个赛道同时登顶,业内一度猜测它来自「亚洲某 AI 实验室」,与阿里的 WAN 系列模型有技术关联。
现在谜底揭开了。HappyHorse 1.0 就是阿里的手笔,而且它带来的不只是排行榜上的数字,而是一种和当前主流方案截然不同的视频生成思路。
核心卖点:音视频不是拼出来的,是一起「长」出来的
先说最关键的一点,也是 HappyHorse 1.0 和市面上绝大多数视频生成模型最本质的区别——它不是先生成视频,再配音。
目前主流的 AI 视频生成工作流,基本都是「视频归视频,音频归音频」。你用一个模型生成画面,再用另一个模型或工具去配音效、对口型、加环境音。这套流程能跑通,但痛点很明显:口型对不上、脚步声和动作不同步、环境音和画面割裂。做过短视频后期的人都知道,光是音画同步这一件事就能吃掉大量时间。
HappyHorse 1.0 走了一条不同的路。阿里称之为「原生多模态架构」,具体来说就是采用音视频联合生成方案——在一次前向推理(single forward pass)中,模型同时输出视频帧和对应的音频流。对话语音、环境音、脚步声、Foley 音效,都在同一个去噪过程中生成,天然对齐。
这意味着什么?
举个具体场景:你给模型一段提示词,描述「一个女孩在雨中的东京街头撑伞走路,背景有霓虹灯和车流声」。传统方案下,你会拿到一段无声视频,然后需要自己去找雨声素材、车流音效、脚步声,手动铺到时间轴上。HappyHorse 1.0 直接给你一段带声音的成片——雨滴打在伞面上的声音、远处的车流、鞋底踩水的节奏,都和画面动作一一对应。
这不是「锦上添花」的功能,而是生产效率上的质变。对于广告、电商、短剧这些对产出速度有极高要求的场景,省掉音频后期这一环,意味着单条内容的制作周期可能直接砍掉 30%-50%。
技术细节:150 亿参数,统一 Token 去噪
从已公开的技术信息来看,HappyHorse 1.0 的参数规模在 150 亿级别。它的架构核心思路是「大一统」——把视频帧和音频信号统一编码为 token 序列,在同一个扩散模型框架下进行联合去噪。
这和当前业界的「模块化拼接」思路形成了鲜明对比。大多数竞品的做法是:视频生成模块和音频生成模块各自独立训练,推理时串行或并行执行,最后在后处理阶段做对齐。这种方案的好处是各模块可以独立迭代,坏处是音画之间的语义关联天然就弱——两个模型各干各的,同步全靠后期硬凑。
HappyHorse 1.0 的统一架构则让音频和视频在生成阶段就共享上下文信息。模型在去噪每一步时,视频 token 和音频 token 之间可以互相「看到」对方,这从根本上解决了同步问题。代价是训练复杂度更高、数据要求更苛刻,但效果确实立竿见影。
另一个值得关注的能力是多语言唇形同步。HappyHorse 1.0 原生支持英语、中文等多种语言的口型生成,不需要额外的口型对齐工具。这对做多语言内容的团队来说是个实打实的利好——以前要做一条中英双语的产品宣传视频,口型适配本身就是个大工程。
排行榜成绩:不是小幅领先,是断层式领先
数据层面,HappyHorse 1.0 在 Artificial Analysis AI Video Arena 的盲测排行榜上表现相当强势:
- 文本转视频(T2V):Elo 1333,排名第一
- 图像转视频(I2V):Elo 1392,排名第一,领先第二名超过 50 分
50 分的 Elo 差距在这个量级的排行榜上是什么概念?大致相当于一个选手在盲测中赢另一个选手的概率超过 57%。考虑到参与排名的都是 Seedance 2.0、Kling、Runway Gen-4 这个级别的模型,这个差距已经不算小了。
尤其是图像转视频这个赛道,Elo 1392 的成绩说明 HappyHorse 1.0 在「把静态图片变成动态视频」这件事上,运动自然度、物理合理性、细节保持度都明显优于竞品。这对电商场景特别有价值——商品主图转视频是一个巨大的需求池,而这个场景对「动起来之后别变形」的要求极高。
当然,排行榜成绩要理性看待。Artificial Analysis 的盲测主要评估的是视觉质量和提示词遵循度,实际生产中还有生成速度、稳定性、API 可用性等一堆因素。灰测阶段的表现能否在大规模调用下保持,还需要时间验证。
定价:不算便宜,但逻辑说得通
灰测阶段,HappyHorse 1.0 官网公布的刊例价:
| 分辨率 | 价格 | |--------|------| | 720P | 0.9 元/秒 | | 1080P | 1.6 元/秒 |
这个价格贵不贵?看跟谁比。
如果单纯和纯视频生成模型比,这个价格确实偏高。市面上一些竞品的 720P 生成价格已经打到了 0.3-0.5 元/秒的区间。但 HappyHorse 1.0 的定价逻辑不太一样——它输出的是带音频的成片,不是无声视频。如果你把「视频生成 + 音效生成 + 音画对齐」这套组合拳的总成本算进来,0.9 元/秒反而可能是省钱的。
对于短剧、广告这类场景,一条 15 秒的 1080P 视频成本是 24 元。如果质量过关能直接用,省掉的后期人工成本远不止这个数。
不过,灰测阶段的定价往往不是最终价格。随着模型推理效率优化和竞争加剧,降价几乎是必然的。
开源:已经放出来了
HappyHorse 1.0 已经宣布开源,这一点和阿里在大模型领域一贯的策略一致——通义千问系列、WAN 系列都走了开源路线。开源意味着开发者可以本地部署、二次开发、自由定制,不被 API 绑定。
对于有 GPU 资源的团队来说,本地部署可以把边际成本压到极低。150 亿参数的模型规模,在当前的硬件条件下,用几张 A100 或同级别显卡就能跑起来,门槛不算离谱。
但要注意,开源的是模型权重和推理代码,训练数据和完整的训练流程大概率不会公开。这在业内是常规操作,不影响使用,但如果你想从头复现或做深度魔改,还是会受到一定限制。
它在解决什么问题?
退一步看,HappyHorse 1.0 瞄准的核心痛点其实很清晰:AI 视频生成的「最后一公里」不是画质,而是可用性。
过去两年,AI 视频生成模型在画质上的进步有目共睹——从 Sora 到 Kling 到 Runway Gen-4,生成的画面越来越像真实拍摄。但在实际生产中,一段无声的、需要大量后期处理的视频片段,离「可用的内容」还有很远的距离。
音画同步、口型对齐、音效匹配——这些看似「小事」的后期工作,实际上占据了内容制作流程中相当大的比例。HappyHorse 1.0 试图用端到端的方式一次性解决这些问题,让模型输出的东西更接近「成品」而不是「半成品」。
这个方向是对的。AI 视频生成的竞争正在从「谁的画质更好」转向「谁的输出更能直接用」。画质是基础分,可用性才是加分项。
面向的场景
从阿里官方的定位来看,HappyHorse 1.0 主要面向四类场景:
- 广告创意:快速生成带音效的广告片段,缩短从创意到成片的周期
- 电商内容:商品主图转视频、商品展示动画,带环境音和背景音乐
- 短剧制作:对话场景的音视频同步生成,省掉配音和口型对齐
- 社媒创意:短视频、Reels、TikTok 内容的快速批量生产
这四个场景有一个共同特点:对产出速度的要求远高于对极致画质的要求。一条电商短视频,720P 够用,但如果要等两天做后期,那就不够用了。HappyHorse 1.0 的音视频一体化生成,恰好切中了这个需求。
同时,官方还提到了「从智能生成到编辑的一体化创作能力」,这意味着 HappyHorse 1.0 不只是一个生成模型,还会配套提供编辑工具链。具体的编辑能力有多强,还要等灰测进一步开放后才能评估。
竞争格局:视频生成赛道越来越挤了
2026 年的 AI 视频生成赛道,用「卷」来形容已经不够了。
国际上,Runway Gen-4、Pika 2.0 持续迭代;国内,快手的 Kling、字节的 Seedance 2.0、智谱的 CogVideo 都在快速推进。每隔几周就有新模型刷榜,Elo 分数像通胀一样往上涨。
HappyHorse 1.0 的差异化在于「音视频原生联合生成」这个技术路线。目前市面上真正做到一次推理同时输出音视频的模型屈指可数,大多数竞品还是视频和音频分开处理。如果阿里能在这个方向上持续迭代,建立起技术壁垒,那 HappyHorse 系列有机会在赛道中占据一个独特的生态位。
但风险也很明显:其他玩家不会坐视不管。音视频联合生成的技术路线并不是什么秘密,一旦被验证可行,竞品跟进只是时间问题。先发优势的窗口期可能只有几个月。
写在最后
HappyHorse 1.0 的灰测开放,标志着 AI 视频生成正式进入「音视频一体化」的新阶段。它不是第一个尝试这个方向的模型,但它是目前做得最好的——至少排行榜数据是这么说的。
对开发者来说,现在值得关注的几个点:灰测阶段的 API 稳定性如何、实际生成速度能不能满足生产需求、开源版本的部署门槛有多高。这些问题的答案,会决定 HappyHorse 1.0 到底是一个漂亮的 demo,还是一个真正能用起来的生产力工具。
如果你在做视频相关的应用,建议尽早申请灰测资格试一试。毕竟,看排行榜不如自己跑几条片子来得实在。
参考来源
- 阿里 HappyHorse 1.0 技术解析与排行榜表现 - 知乎 — HappyHorse 1.0 的 150 亿参数架构、音视频同构技术路线深度分析
