小米 MiMo-V2.5 开源:30 天撒 100 万亿 Token

小米今日凌晨宣布 MiMo-V2.5 系列全球开源,采用 MIT 协议允许商用和微调。同步启动「创造者百万亿 Token 激励计划」,30 天内发放 100T Token 权益,单用户最高可获价值 659 元的 16 亿 Credits。
小米 MiMo-V2.5 开源:30 天撒 100 万亿 Token
小米今天凌晨宣布 MiMo-V2.5 系列模型全球开源,同步启动「MiMo Orbit 计划」——30 天内向全球开发者发放 100 万亿 Token,单用户最高可获 16 亿 Credits(价值 659 元)。这是国内大模型厂商在开源策略上的又一次激进尝试。
模型权重和推理代码已全量开放,采用 MIT 协议,允许商用、二次训练和微调,无需额外授权。这个许可证比 Meta 的 Llama 社区协议更宽松,也比阿里 Qwen 的「禁止用于军事用途」条款更彻底。
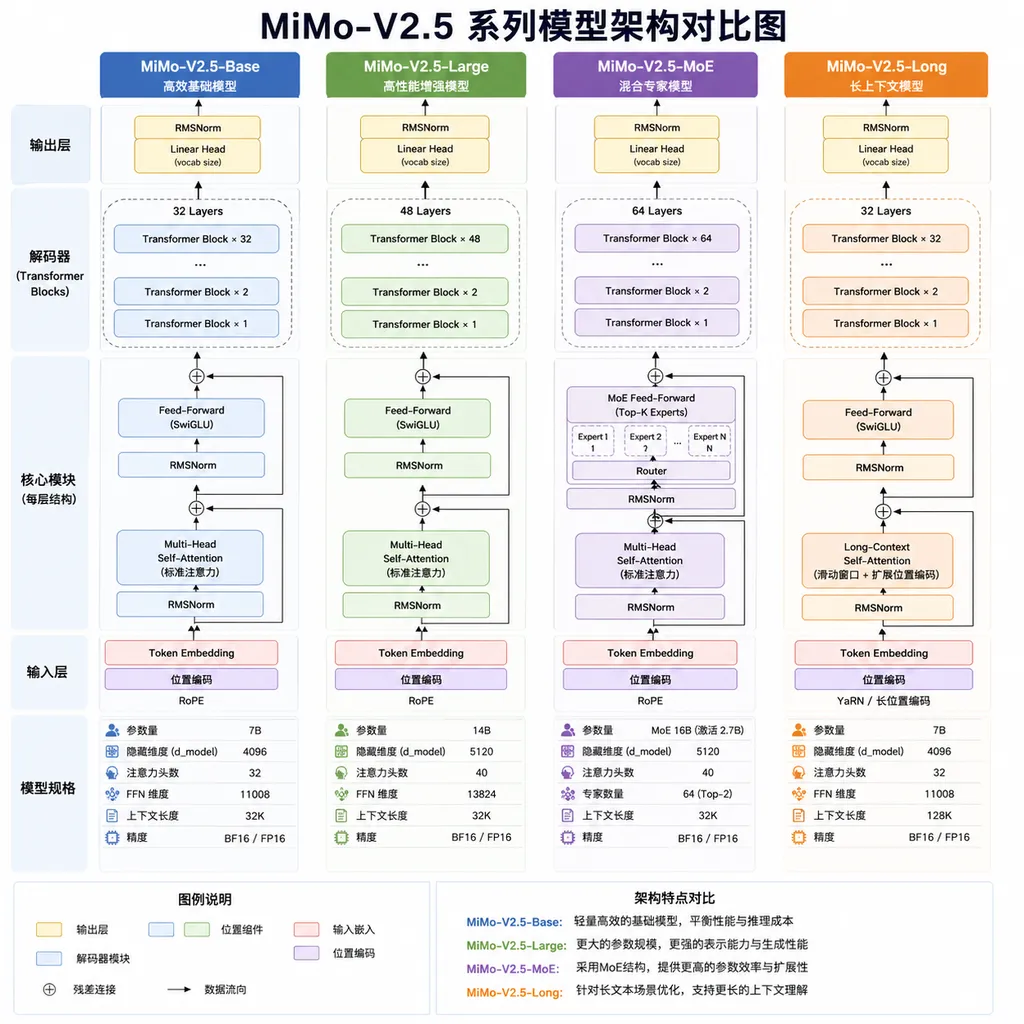
两个版本,各有侧重
MiMo-V2.5 系列包含两款模型,都支持 100 万 Token 上下文窗口:
- MiMo-V2.5-Pro:面向复杂任务场景,深度适配 Agent 和 Coding 应用。在 GDPVal-AA 和 ClawEval 榜单上位列全球开源模型第一
- MiMo-V2.5:原生全模态模型,支持文本、图像、视频和音频理解,具备强大的 Agent 能力
小米技术团队强调,模型的真正价值不在于榜单排名,而在于能否高效帮助开发者解决实际问题。在 Claw-Eval 榜单上,MiMo-V2.5 位列任务完成率与 Token 效率的最优前沿。
这个说法有实际数据支撑。官方披露,在达到相同 Agent 评测分数下,MiMo-V2.5-Pro 相比 Kimi K2.6 节省 42% Token,MiMo-V2.5 相比 Muse Spark 节省 50% Token。对于需要大量调用的 Agent 应用来说,这个效率差异直接影响成本。
100 万亿 Token 怎么领
「创造者百万亿 Token 激励计划」从今天(4 月 28 日)零点开始,持续到 5 月 28 日,采取申请制。申请通过的用户最高可获得 Max 档位的 Token Plan,包含 16 亿 Credits,官方标价 659 元。
申请流程:
- 访问 100t.xiaomimimo.com 填写表单
- 等待审核通过邮件(建议提前绑定小米开发者账号)
- 在开发者控制台「订阅管理」中查看下发的 Token Plan
需要注意的是,这 100 万亿 Token 是总池子,赠完即止。按单用户最高 16 亿 Credits 计算,理论上可以支持约 6.25 万名开发者。实际上大部分用户不会拿到 Max 档位,所以覆盖人数会更多。
这个规模在国内大模型厂商中算是比较激进的。对比来看,DeepSeek 的免费额度是每天 5000 万 Token,阿里 Qwen 的免费额度是每月 100 万 Token。小米这次直接把额度前置,用申请制筛选真正有需求的开发者。
Agent 生态共建计划
MiMo Orbit 计划的另一部分是「Agent 生态共建计划」,面向 Agent 框架团队提供专项支持。小米将为 Agent 框架提供 MiMo Token 限免支持,让框架的用户可以零门槛接入并体验 MiMo 系列模型。
这个策略很明确:通过框架层面的集成,让 MiMo 模型成为开发者的默认选项之一。类似 Anthropic 和 OpenAI 在 LangChain、LlamaIndex 等框架中的深度集成。
如果你是 Agent 框架开发者或厂商,可以联系 business-mimo@xiaomi.com 申请合作。
Day-0 适配:硬件生态已就位
MiMo-V2.5-Pro 在开源首日就完成了多个芯片厂商的接入适配,这个速度在国内开源模型中比较少见。适配名单包括:
- 平头哥真武 810E:依托全栈自研 AI 软件栈,实现深度适配
- 亚马逊云科技 Trainium2:基于自研芯片与 Neuron SDK + vLLM 推理框架,完成深度适配。下一代 3nm 制程 Trainium3 将进一步释放模型 Agentic 性能潜能
- AMD:依托 ROCm 开源软件栈,提供 Day-0 适配及全面优化支持
- 燧原科技 L600:依托自研驭算 TopsRider 软件栈进行深度优化,实现高吞吐、低延迟的稳定运行
- 天数智芯:依托全栈自研软硬件,打造高质量算力,适配高效且易迁移
此外,MiMo-V2.5 系列模型也同步完成了 SGLang 和 vLLM 两大主流推理框架的 Day-0 适配。
这个硬件生态的覆盖速度说明小米在开源前做了充分准备。对比 Meta 的 Llama 系列,通常需要社区花几周时间才能完成各种硬件平台的适配。小米这次直接在开源首日就把主流硬件平台打通,降低了开发者的部署门槛。
定价策略调整:取消上下文窗口倍率
在 4 月 23 日开启公测时,小米还对 Token Plan 定价方案进行了优化。最重要的变化是取消了 1 Token = 4 Credits 的计费方式,Token Plan 不再区分 256k 和 1M 上下文窗口的 Credit 倍率。
这个调整对长上下文应用很友好。之前很多模型厂商会对长上下文收取更高费用,比如 OpenAI 的 GPT-4 Turbo 在 128k 上下文时的价格是标准版的 2 倍。小米直接把这个倍率取消,意味着开发者可以放心使用 100 万 Token 的上下文窗口,不用担心成本暴增。
此外,小米还新增了「连续包月」和「包年」的订阅模式,进一步降低长期使用成本。
开源策略的商业逻辑
小米这次开源策略的激进程度超出预期。MIT 协议 + 100 万亿 Token 免费额度 + Day-0 硬件适配,这三个动作组合起来,目标很明确:快速占领开发者心智,建立生态护城河。
对比国内其他大模型厂商:
- 阿里 Qwen:开源但有使用限制,免费额度较少
- 百度文心:主要走闭源路线,开源版本功能受限
- 字节豆包:闭源为主,API 价格战打得激烈
- DeepSeek:开源 + 低价 API,但硬件生态支持相对薄弱
小米的策略更像是 Meta 的 Llama 路线:通过开源建立生态,通过免费额度吸引开发者,通过硬件适配降低部署门槛。但小米比 Meta 更激进的地方在于,直接用 MIT 协议放弃了所有限制,也没有像 Llama 那样要求大规模商用需要单独授权。
这个策略的风险在于,如果模型能力不够强,开发者拿了免费额度也不会真正用起来。但从目前的榜单表现和 Token 效率数据来看,MiMo-V2.5 系列至少在 Agent 和长上下文场景下有竞争力。
对开发者的实际影响
如果你是 AI 应用开发者,这次开源和免费额度值得关注的点:
- 成本优势明显:16 亿 Credits 的免费额度足够支撑中小型项目跑很长时间。即使用完免费额度,MiMo 的 API 定价也比 GPT-4 和 Claude 便宜
- 长上下文场景友好:100 万 Token 上下文 + 不区分窗口大小的计费方式,适合做 RAG、长文档分析、代码库理解等场景
- Agent 能力突出:在 ClawEval 榜单上的表现说明 MiMo-V2.5-Pro 在复杂任务规划和执行上有优势,适合做智能体应用
- 部署灵活:MIT 协议 + 多硬件平台支持,可以选择云端 API 或本地部署
需要注意的是,100 万亿 Token 的总池子是有限的,建议尽早申请。另外,申请时最好提前绑定小米开发者账号,审批通过后 Token Plan 会直接下发到账户中。
目前 MiMo-V2.5 系列已经可以通过 OpenAI Hub 等 API 聚合平台调用,兼容 OpenAI 格式,迁移成本很低。
