NVIDIA端侧全能选手:Nemotron 3 Nano Omni来了

NVIDIA 发布 Nemotron 3 Nano Omni,一款面向端侧部署的长上下文多模态模型,原生支持文档、音频、视频理解,专为智能体场景设计,开源可商用。
NVIDIA 这两天放出了 Nemotron 3 家族的又一个重要成员——Nano Omni。这不是一个简单的版本迭代,而是把文档理解、音频处理、视频分析塞进了一个可以跑在端侧的模型里。对于正在做多模态智能体的开发者来说,这可能是目前开源阵营里最值得关注的选项之一。
先说清楚 Nemotron 3 家族的关系
去年 12 月,NVIDIA 正式推出了 Nemotron 3 系列,分三个规格:
- Nano:约 300 亿参数的混合推理模型,主打高吞吐、长上下文,面向端侧和边缘部署
- Super:约 1000 亿参数,每个 token 最多激活 100 亿参数,面向多智能体协作场景
- Ultra:更大规格,面向最复杂的推理任务
Nano 是最先发布的,Super 和 Ultra 计划在 2026 年上半年陆续放出。而这次的 Nano Omni,是在 Nano 基础上扩展了完整的多模态能力——不只是能看图,而是能看视频、听音频、读文档,并且这些能力是原生集成的,不是外挂 pipeline 拼起来的。
这个区别很重要。拼接式的多模态方案(比如先用 Whisper 转文字再喂给 LLM)会丢失大量上下文信息,延迟也高。Nano Omni 的做法是在架构层面就把视觉编码器、音频编码器和语言模型融合在一起,端到端处理。
架构:Mamba-2 + MoE + 少量自注意力
Nemotron 3 的架构设计是这次最有意思的技术点。它没有走纯 Transformer 的路线,而是采用了混合架构:
- Mamba-2 层负责处理长序列,线性复杂度,吞吐量高
- MoE(混合专家)层控制单 token 计算成本,让大参数量不等于大算力消耗
- 少量自注意力层穿插其中,保证关键位置的全局信息交互
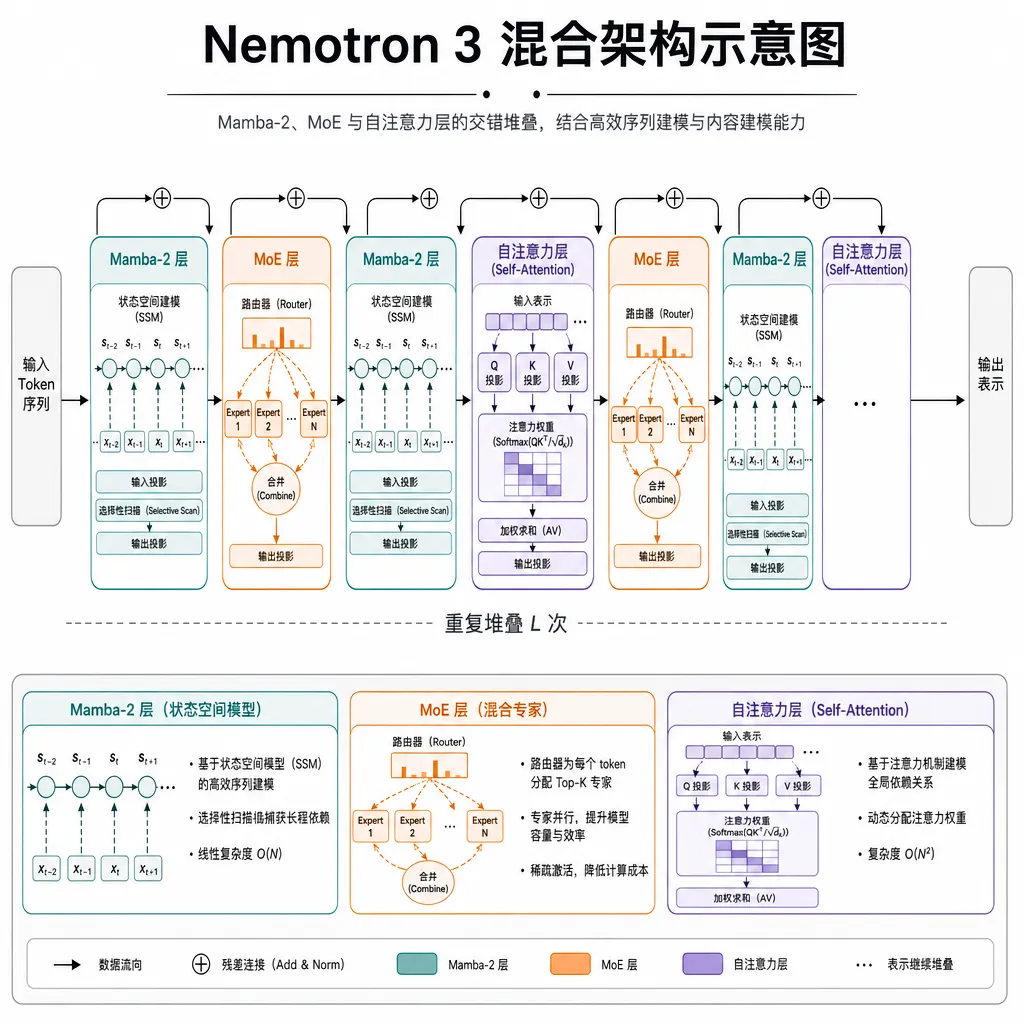
这种设计的直接好处是:模型可以处理 100 万 token 的上下文窗口,同时推理速度不会崩。对于智能体场景来说,这意味着你可以把一整份几百页的 PDF、一段 30 分钟的会议录音、或者一个监控视频片段直接丢进去,不需要自己做分块、摘要这些脏活。
传统的长上下文方案往往依赖「碎片化的分块启发式方法」——把长文档切成小块分别处理,再想办法拼回来。这种方式在 RAG 场景下勉强能用,但一旦涉及跨段落推理、时序理解(比如视频里前后事件的因果关系),就会出问题。Nano Omni 的 100 万 token 窗口配合 Mamba-2 的高效序列处理,理论上可以在单个上下文窗口里完成这些任务。
当然,「理论上」和「实际上」之间还有距离。100 万 token 的有效利用率、长距离信息的实际召回质量,这些还需要社区更多的测试验证。但至少从架构设计上,这个方向是对的。
多模态能力拆解
Nano Omni 的「Omni」不是营销话术,它确实覆盖了目前智能体最需要的几个感知维度:
文档理解
这里说的不是简单的 OCR + 文本理解。Nano Omni 可以直接处理文档的页面图像,理解表格、图表、流程图这些结构化和半结构化内容。配合 Nemotron 家族里的 Llama Nemotron Embed VL(17 亿参数的多模态嵌入模型)和 Llama Nemotron Rerank VL,可以搭建完整的视觉文档检索链路。
Embed VL 的做法比较巧妙:基于 Eagle 视觉语言模型(Llama 3.2 1B 主干 + SigLip2 400M 视觉编码器),用对比学习把页面图像和文本编码到同一个向量空间,支持 Matryoshka 嵌入(可以按需截断向量维度来换取速度)。在 ViDoRe V3 基准上,它占据了 Pareto 前沿——也就是在检索准确率和吞吐量的权衡上,目前没有更优的开放模型。
这对做企业文档智能的团队来说是个好消息。以前要处理混合了文字、表格、图表的复杂文档,往往需要一套很重的 pipeline:OCR → 版面分析 → 表格识别 → 文本提取 → 再喂给 LLM。现在可以大幅简化。
音频理解
Nano Omni 原生支持音频输入,不需要外挂 ASR 模块。这意味着它可以直接从音频波形中提取语义信息,包括语气、停顿、重音这些在纯文本转录中会丢失的信号。
在 Nemotron 3 家族里,还有一个专门的 VoiceChat 模型,已经进入了 Artificial Analysis 语音转语音排行榜的「右上角象限」——同时具备高对话动态性和强语音推理能力。Nano Omni 虽然定位不同(它是通用多模态,不是专门的语音对话),但音频理解能力可以和 VoiceChat 形成互补:Omni 负责「听懂」,VoiceChat 负责「说好」。
视频理解
视频是最吃上下文长度的模态。一段 1080p、30fps 的视频,每秒就是 30 帧图像。即使做了关键帧提取,一段 10 分钟的视频也很容易产生几十万 token 的输入。这正是 Nano Omni 的 100 万 token 窗口派上用场的地方。
具体的应用场景包括:视频内容审核、监控视频分析、会议录像摘要、教学视频理解等。以前这些任务要么依赖专门的视频模型(通常不具备语言推理能力),要么把视频切成帧再逐帧分析(丢失时序信息)。Nano Omni 提供了一个端到端的方案。
GUI 理解
这个能力容易被忽略,但对智能体来说可能是最实用的。Nano Omni 可以理解屏幕截图、应用界面,识别按钮、菜单、输入框等 UI 元素。这是构建「计算机使用」类智能体的基础能力——让 AI 像人一样操作软件界面。
训练方法:NeMo Gym + 强化学习
Nemotron 3 的后训练不是简单的 SFT(监督微调),而是在 NeMo Gym 中通过多环境强化学习完成的。NeMo Gym 是 NVIDIA 开源的 RL 环境构建库,可以模拟各种智能体任务场景。
这里的关键区别是:传统的 SFT 训练模型给出单次最佳回答,而 RL 训练模型执行连续动作序列。比如:
- 生成正确的工具调用链
- 编写可执行的代码
- 制定并执行多步骤计划
这种训练方式让 Nano Omni 天然适合智能体场景,而不只是问答。
另外值得一提的是精度方面的创新。Super 和 Ultra 模型采用 NVFP4(NVIDIA 自研的 4 位浮点格式)进行预训练,不是推理时量化,而是训练时就用低精度。这在 25 万亿 token 的预训练数据集上实现了稳定训练,同时大幅降低了训练和推理成本。Nano 虽然没有用 NVFP4 预训练,但这项技术为后续的模型压缩和端侧部署提供了更多可能性。
性能表现
在 Artificial Analysis Intelligence Index v3.0 上,Nemotron 3 Nano 拿到了 52 分,在同等规模(300 亿参数级别)的开放模型中领先。作为参考,这个分数和一些 70B 级别的模型(如 Qwen2.5、Llama-3.1 70B)处于同一梯队。
换句话说,用不到一半的参数量,达到了接近两倍大模型的智能水平。这就是混合架构 + MoE 的效率优势。
在开放性方面,Nemotron 3 Nano 在 Artificial Analysis Openness Index 上保持了和前代 Nemotron Nano V2 相同的分数,模型权重、训练方法、数据集都是开放的,采用 NVIDIA 开放模型许可证发布。
不过要注意,Nano Omni 作为 Nano 的多模态扩展版本,目前的基准测试数据主要还是针对 Nano 基座的。Omni 在各个多模态基准上的具体表现,还需要等更多第三方评测出来。
生态配套
NVIDIA 这次不只是丢出一个模型,而是给了一整套工具链:
- NeMo Gym:开源 RL 环境库,用于智能体行为训练
- NeMo Data Designer:数据生成和增强工具
- NeMo Evaluator:模型评估框架
- Nemotron 3 Content Safety:内容安全模型,可以对多模态输入、检索内容和输出进行审核
这套工具链的完整度在开源社区里算是比较少见的。大多数开源模型发布时只给模型权重和一个 README,NVIDIA 把训练、数据、评估、安全审核都配齐了。对于想要在生产环境中使用的团队来说,这些配套工具的价值可能不亚于模型本身。
特别是 Content Safety 模型,它可以在智能体的每一步进行内容审核——输入审核、检索内容审核、输出审核。在企业场景中,这是合规的硬性要求,很多团队在这上面花的时间比调模型还多。
和竞品比怎么样
在端侧多模态模型这个赛道上,目前的主要玩家包括:
- Qwen2.5-VL(阿里):视觉语言能力强,但不原生支持音频
- Phi-4-multimodal(微软):支持视觉和音频,但上下文窗口有限
- InternVL 3(上海 AI Lab):视觉理解能力突出,社区活跃
- Gemma 3(Google):轻量级,但多模态能力相对基础
Nano Omni 的差异化在于三点:
- 真正的全模态:视觉 + 音频 + 文档 + GUI,一个模型全覆盖
- 100 万 token 上下文:在同规模模型中几乎没有对手
- 智能体原生设计:从训练方法到工具链都围绕智能体场景
劣势也很明显:NVIDIA 做模型的时间不长,社区生态和微调经验不如 Qwen、Llama 这些老牌选手丰富。另外,Nano Omni 目前标注的是「即将推出」,还没有正式放出权重,具体的部署体验和实际效果还是未知数。
对开发者意味着什么
如果你在做以下方向,Nano Omni 值得重点关注:
- 企业文档智能:合同审查、财报分析、技术文档问答,特别是包含大量表格和图表的场景
- 音视频内容理解:会议纪要自动生成、视频内容审核、播客/直播内容分析
- 多模态 RAG:需要同时检索和理解文本、图像、音频内容的系统
- 桌面/移动端智能体:需要理解 GUI 并执行操作的自动化场景
- 边缘部署:需要在本地或边缘设备上运行多模态推理的场景
300 亿参数的规模意味着它可以在单张消费级 GPU(比如 RTX 4090)上运行,量化后甚至可能跑在更小的设备上。这对于有数据隐私要求、不能把数据发到云端的企业场景来说,是一个关键优势。
一些冷静的思考
说了这么多好的,也得泼点冷水。
第一,Nano Omni 目前还没有正式发布权重,NVIDIA 博客里写的是「即将推出」。在没有实际跑起来之前,所有的性能承诺都只是承诺。
第二,100 万 token 的上下文窗口听起来很美,但实际使用中的有效利用率是另一回事。很多号称支持长上下文的模型,在「大海捞针」测试中的表现并不理想,尤其是在中间位置的信息召回上。Nano Omni 的混合架构理论上有优势,但还需要实测验证。
第三,NVIDIA 的模型生态相比 Meta(Llama)、阿里(Qwen)还是年轻的。社区里的微调教程、部署经验、踩坑记录都比较少。如果你的团队没有足够的工程能力,上手成本可能比预期高。
第四,多模态模型的评测体系本身还不成熟。不同基准测试之间的结果经常打架,一个模型在 A 基准上领先、在 B 基准上落后是常态。不要只看官方放出的数字,等第三方评测和社区反馈。
总结
Nemotron 3 Nano Omni 代表了 NVIDIA 在开源模型领域的一个明确信号:不只是做基座模型,而是要做面向智能体的完整解决方案。从模型架构(混合 Mamba-Transformer)、训练方法(RL 驱动的智能体行为学习)、到工具链(NeMo 全家桶)、再到安全审核(Content Safety),这是一个系统性的布局。
对于开发者来说,现在可以做的是:关注 Nano Omni 的正式发布时间,先用已经可用的 Nano 基座模型熟悉 Nemotron 3 的架构和工具链,等 Omni 权重放出后第一时间上手测试。NVIDIA 的 GitHub 仓库和 Hugging Face 页面是获取最新信息的最佳渠道。
端侧多模态智能体这个方向,2026 年注定是卷出天际的一年。Nano Omni 能不能站住脚,最终还是要看社区用脚投票。
参考来源
- Introducing NVIDIA Nemotron 3 Nano Omni - Hugging Face Blog — NVIDIA 官方发布的 Nano Omni 技术博客,包含架构细节和能力介绍
- NVIDIA releases Nemotron 3 Nano - Reddit r/LocalLLaMA — 社区对 Nemotron 3 Nano 发布的讨论,包含性能对比和部署经验
- Nvidia just dropped Nemotron 3 - Reddit r/AgentsOfAI — 智能体开发者社区对 Nemotron 3 系列的讨论和评价
