440MB塞进33种语言,腾讯把翻译大模型「硬塞」进手机

腾讯混元开源手机端离线翻译模型 Hy-MT1.5-1.8B-1.25bit,通过极致量化压缩将 1.8B 参数模型压至 440MB,支持 33 种语言离线翻译,骁龙 865 即可运行,翻译质量超越谷歌翻译。
440MB 塞进 33 种语言,腾讯把翻译大模型「硬塞」进手机
腾讯混元团队今天开源了一个手机端离线翻译模型 Hy-MT1.5-1.8B-1.25bit。核心卖点很直接:440MB 的体积,33 种语言,不联网,下载到手机上就能跑。演示设备是一台搭载骁龙 865、8GB 内存的手机——这是 2020 年的旗舰芯片,放在今天基本是中端水平。
换句话说,你手里那台用了两三年的安卓机,大概率能跑得动。
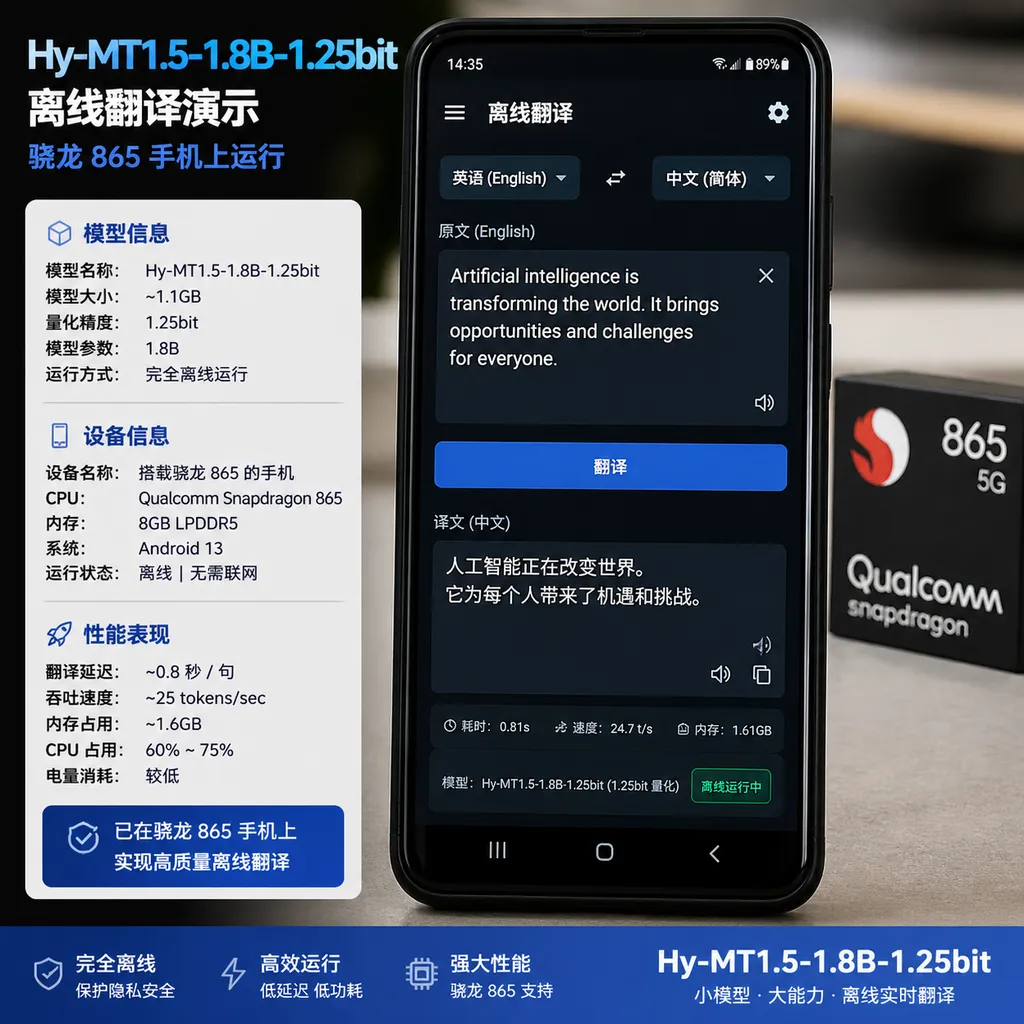
先说翻译能力:1.8B 参数打出 235B 的效果
这个模型的底座是腾讯混元的专业翻译大模型 Hy-MT1.5。参数量只有 1.8B,但腾讯给出的评测数据相当激进——在 FLORES-200 基准测试中,翻译质量不仅超过了谷歌翻译,还比肩 235B 级别的大模型和商业翻译 API。
1.8B 对 235B,参数量差了 130 多倍,翻译效果却能打平。这说明在翻译这个垂直任务上,模型架构和训练策略的优化空间远比「堆参数」大得多。翻译不像通用对话那样需要海量世界知识,它更依赖语言对之间的映射精度和上下文理解。腾讯显然在这个方向上做了大量针对性优化。
语言覆盖面也值得说一下:33 种语言、5 种方言(含民汉翻译)、1056 个翻译方向。从中英法日这些主流语种,到阿拉伯语、俄语,甚至藏语、蒙古语等少数民族语言都覆盖了。1056 个方向意味着这些语言之间可以两两互译,不需要以中文或英文为中转。
这对实际使用场景的意义很大。传统的多语言翻译系统通常采用「枢轴语言」策略——比如把泰语翻成英语,再从英语翻成日语。两次翻译,两次损耗。直接支持语言对之间的互译,翻译质量和速度都会好不少。
真正的技术亮点:怎么把 3.3GB 压到 440MB
1.8B 参数的模型在 FP16 精度下占 3.3GB 内存。对于手机来说,这个体积依然不现实——你的手机同时还要跑系统、跑微信、跑一堆后台服务,能留给一个翻译模型的内存空间非常有限。
所以核心问题变成了:怎么把模型压小,同时尽量不丢翻译质量。
腾讯给出了两套方案,对应两种使用场景。
方案一:2-bit 量化,574MB(中高端机型)
量化的基本原理不复杂:原本模型里每个参数用 16 位浮点数存储,量化就是把它降到更低的位数。16-bit 降到 2-bit,存储空间直接缩小 8 倍。
但粗暴地降低精度会严重损害模型效果。腾讯在 2-bit 方案中用了一种叫「拉伸弹性量化」(Stretched Elastic Quantization,SEQ)的技术。简单理解:它不是把参数均匀地映射到 {0, 1} 两个值,而是映射到 {-1.5, -0.5, 0.5, 1.5} 四个值。这四个值的间距经过精心设计,能更好地保留原始参数的分布特征。
再配合量化感知蒸馏——让量化后的小模型去「学习」原始大模型的输出行为——最终 574MB 的 2-bit 模型实现了几乎无损的翻译质量。
一个额外的加分项:在支持 Arm SME2 指令集的新款移动芯片上,2-bit 模型可以获得显著的推理加速。SME2 是 Arm 在 2023 年推出的矩阵运算扩展指令集,专门为低比特运算做了硬件级优化。这意味着随着新手机芯片的迭代,这个模型的运行速度还会继续提升。

方案二:1.25-bit 量化,440MB(全系机型)
2-bit 还不够极致。腾讯又推出了 1.25-bit 的版本,基于自研的 Sherry 极致压缩方案。
1.25-bit 是什么概念?常规的量化最低也就到 2-bit 或 1.58-bit(BitNet 方案)。1.25-bit 意味着平均每个参数只用 1.25 个比特来存储,比一个二进制位多不了多少。模型体积从 3.3GB 直接压到 440MB,压缩比接近 8 倍。
这个压缩率放在整个行业里都算激进的。作为对比,Meta 的 BitNet 方案做到 1.58-bit 已经被认为是极致量化的代表,腾讯这次直接把数字拉到了 1.25。
当然,压缩到这个程度,翻译质量不可能完全无损。但从腾讯公布的 FLORES-200 评测数据来看,1.25-bit 版本的翻译效果虽然比 2-bit 版本有所下降,但仍然保持在可用水平,对于「手机上随时能用的离线翻译」这个场景来说,这个 trade-off 是合理的。
440MB 是什么体量?大概相当于一个中等大小的手游安装包,或者你手机里存的几十张高清照片。下载一次,离线永久可用,不吃流量,不依赖服务器。
离线翻译为什么重要
你可能会问:现在到处都有 WiFi,在线翻译 API 又快又好,为什么还要折腾离线?
几个真实场景:
出境旅行。 你在东京地铁里、在曼谷的夜市、在伊斯坦布尔的老城区,手机信号时有时无,漫游流量贵得离谱。这时候一个 440MB 的离线翻译模型就是刚需。
隐私敏感场景。 企业内部文档、法律合同、医疗记录——这些内容你不一定想发到云端去翻译。离线模型意味着数据完全不出设备,隐私问题从根源上解决。
网络受限环境。 工厂车间、矿井、远洋船舶、偏远地区——这些场景下网络连接本身就是奢侈品。
成本。 对于需要大量翻译的应用开发者来说,每次调用在线翻译 API 都要付费。把模型部署在端侧,边际成本为零。
之前市面上的离线翻译方案要么体积太大(动辄几个 GB),要么质量太差(基于统计机器翻译的老方案),要么语言覆盖不全。腾讯这次把三个问题同时解决了,至少从公布的数据来看是这样。
对开发者意味着什么
这个模型已经在 Hugging Face 上开源,开发者可以直接下载使用。
从集成角度看,440MB 的模型体积对移动端应用来说是可以接受的。很多 App 本身的安装包就有几百 MB,额外打包一个翻译模型,或者做成按需下载的资源包,用户体验上不会有太大负担。
几个值得关注的集成方向:
- 旅行类 App: 内置离线翻译功能,不再依赖谷歌翻译 API,用户体验和成本都能优化
- 即时通讯工具: 聊天消息的实时翻译,数据不出设备
- 阅读类 App: 外文内容的本地翻译,响应速度比云端 API 更快
- IoT 和嵌入式设备: 智能翻译机、车载翻译系统等硬件产品
- 企业内部工具: 满足数据合规要求的本地化翻译方案
对于已经在做端侧 AI 的团队来说,这个模型的量化方案本身也很有参考价值。SEQ(拉伸弹性量化)和 Sherry 压缩方案的思路,理论上可以迁移到其他类型的端侧模型上——不只是翻译,语音识别、图像分类等任务的端侧部署都可能受益。
放在行业里看
端侧大模型是 2025 年以来最明确的趋势之一。苹果在 Apple Intelligence 里大量使用端侧模型,谷歌的 Gemini Nano 也在 Pixel 手机上跑了起来,高通和联发科的新芯片都在堆 NPU 算力。
但之前端侧模型的主要应用场景集中在通用对话、文本摘要这些「锦上添花」的功能上。腾讯这次选择翻译作为切入点,思路很清晰——翻译是一个高频、刚需、对延迟敏感的任务,天然适合端侧部署。
横向对比一下目前主流的移动端翻译方案:
| 方案 | 体积 | 语言数 | 是否离线 | 翻译质量 | |------|------|--------|----------|----------| | 谷歌翻译离线包 | 每语言约 40-50MB | 需逐个下载 | ✅ | 中等 | | Apple 翻译 | 系统内置 | 约 20 种 | ✅ | 中等偏上 | | Hy-MT1.5 1.25-bit | 440MB 全量 | 33 种 | ✅ | 官方称优于谷歌翻译 | | Hy-MT1.5 2-bit | 574MB 全量 | 33 种 | ✅ | 接近无损 |
谷歌翻译的离线模式需要逐个语言下载语言包,每个包 40-50MB,如果你需要 10 种语言就是 400-500MB,而且这些离线包的翻译质量明显不如在线版本。腾讯的方案用一个 440MB 的模型覆盖了 33 种语言的全部互译方向,从效率上看确实更优。
当然,腾讯公布的评测数据需要打个折扣来看。FLORES-200 是一个标准化的翻译评测基准,但实际使用中的翻译质量还受到很多因素影响:口语化表达、专业术语、长文本连贯性等等。「优于谷歌翻译」这个说法,在特定评测集上可能成立,但在所有真实场景下是否都成立,还需要更多实际使用反馈来验证。
一些待观察的问题
模型开源了,但几个关键问题还需要时间来回答:
实际翻译质量。 评测集上的分数和真实场景下的体验之间,往往存在不小的 gap。特别是 1.25-bit 这种极致压缩方案,在一些低资源语言对上的表现如何,需要社区的广泛测试。
推理速度。 官方演示用的是骁龙 865,但没有给出具体的 tokens/s 数据。对于翻译场景来说,用户期望的是接近实时的响应,如果翻译一句话要等好几秒,体验就会大打折扣。
长文本表现。 1.8B 参数的模型在处理长段落、长文档时,上下文理解能力和翻译连贯性是否能保持,这是小模型的天然短板。
社区生态。 开源模型的价值很大程度上取决于社区的参与度。如果有开发者基于这个模型做出好用的移动端翻译 App,或者把量化方案迁移到其他任务上,那这个项目的影响力会远超模型本身。
写在最后
440MB、33 种语言、离线可用、翻译质量超越谷歌翻译——如果这些数据都经得起验证,那腾讯这次确实在端侧翻译这个细分领域树立了一个新的标杆。
更重要的是,它展示了一种可能性:通过极致的量化压缩技术,大模型不一定非要跑在云端。一个 440MB 的模型能做到的事情,可能比很多人想象的要多得多。
对于正在做端侧 AI 的开发者来说,这个项目值得认真研究——不只是翻译模型本身,更是它背后的量化压缩思路。
参考来源
- IT之家:腾讯混元开源手机端离线翻译模型 Hy-MT1.5-1.8B-1.25bit,仅 440MB — 本文主要信息来源,含官方技术介绍
- Hugging Face:Hy-MT1.5-1.8B-1.25bit 模型页面 — 模型下载与技术文档
