商汤全面开源SenseNova U1:一个大脑搞定理解和生成

商汤科技发布并全面开源 SenseNova U1 系列多模态统一模型,基于自研 NEO-unify 架构,抛弃传统拼接式设计,8B 规格即可比肩部分闭源商业模型。
商汤全面开源 SenseNova U1:不拼接,不转译,一个模型统一理解与生成
4 月 28 日,商汤科技正式发布并开源了 SenseNova U1 系列模型。这是一个原生多模态统一模型——不是把视觉模块和语言模块拼在一起的那种"统一",而是从架构底层就把语言和视觉融进同一个表征空间。
这件事值得关注的原因很简单:当前多模态模型的主流做法,本质上还是"翻译"——图像先经过视觉编码器变成特征,再通过适配器喂给语言模型,生成图像时再反向走一遍 VAE 解码。每一次跨模态传递都有信息损耗,模型越大损耗越能被掩盖,但代价是算力开销也越大。商汤这次的思路是:干脆别翻译了。
NEO-unify 架构:到底改了什么
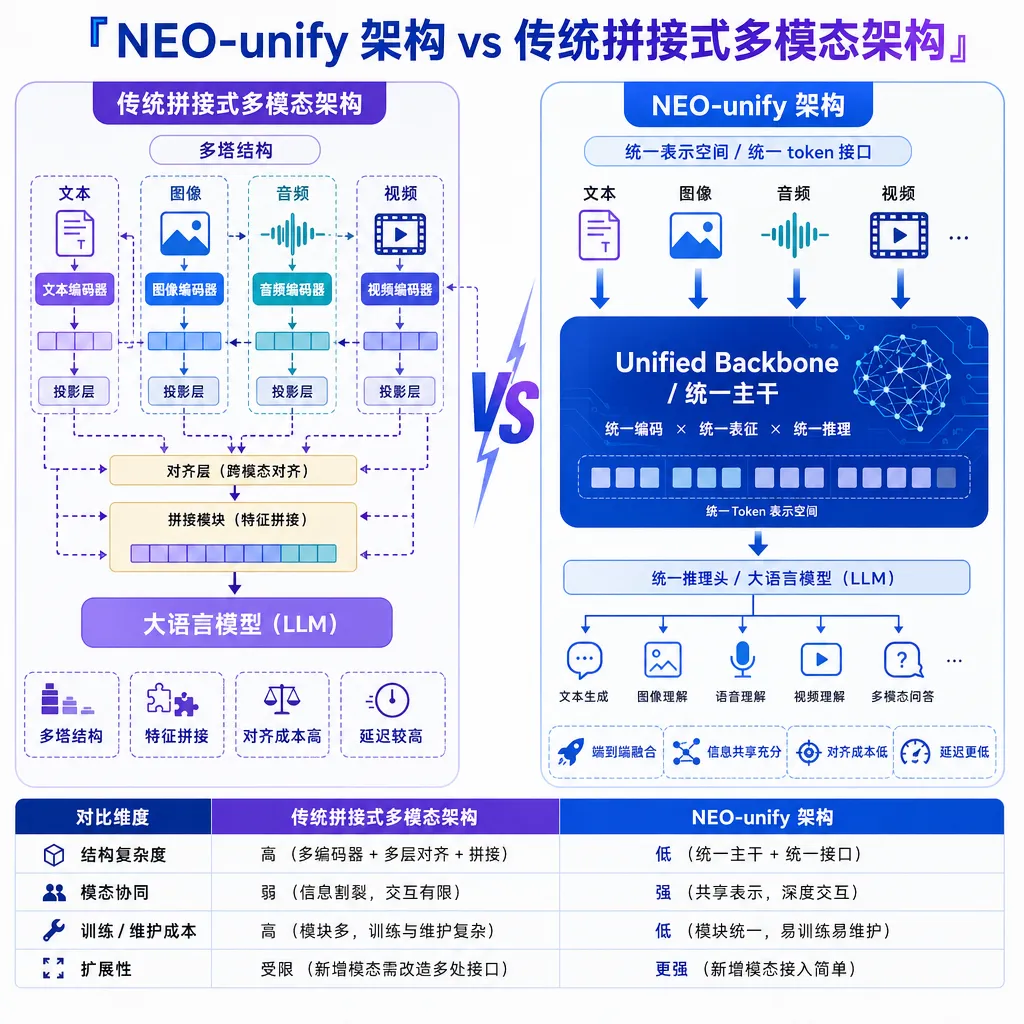
理解 SenseNova U1 的关键在于它底层的 NEO-unify 架构,这是商汤今年 3 月自研的技术方案。
传统多模态模型的架构可以拆成三块:视觉编码器(VE)负责把图像压缩成特征向量,语言模型负责理解和推理,变分自编码器(VAE)负责把特征还原成像素。三者之间通过适配层桥接。这就像一个跨国团队开会——有人只说英语,有人只说中文,中间得配个翻译。能沟通,但效率打折。
NEO-unify 的做法是把 VE 和 VAE 都去掉了。没有独立的视觉编码器,没有独立的图像解码器,语言 token 和视觉 token 在同一个表征空间里被直接建模。每一层 Transformer 计算都同时处理文本和图像信息,不存在"先理解文字再看图"或者"先看图再翻译成文字"的串行流程。
用更技术的话说:它构建了一个统一的表征空间,语言和视觉信号在这个空间里是同构的,模型对它们的处理方式没有本质区别。这不是在 LLM 外面套一个视觉壳子,而是让模型从第一层到最后一层都在同时"思考"文字和图像。
这带来几个直接的好处:
- 信息损耗更低:没有跨模态转译环节,语义在传递过程中不会被压缩或扭曲
- 参数效率更高:不需要靠堆参数来弥补模态间的信息丢失
- 推理速度更快:少了编码-解码的串行步骤,端到端延迟降低
开源了什么:两个轻量版模型
本次开源的是 SenseNova U1 的轻量版系列 U1 Lite,包含两个规格:
| 模型 | 骨干网络 | 特点 | |------|----------|------| | SenseNova-U1-8B-MoT | 稠密网络 | 全参数激活,8B 规模 | | SenseNova-U1-A3B-MoT | MoE(混合专家) | 激活参数约 3B,总参数更大但推理更轻 |
两个模型都已在 GitHub 和 Hugging Face 上开源,权重和代码均可获取。商汤表示后续会发布详细的技术报告,以及更大参数规模的 U1 系列模型。
这里有个细节值得注意:MoT(Mixture of Tokens)这个命名暗示了模型在 token 层面做了混合处理,而不仅仅是传统 MoE 在专家层面的路由。结合统一表征空间的设计,这意味着视觉 token 和语言 token 可能共享同一套专家路由机制,而不是各走各的通道。具体实现细节还需要等技术报告确认。
跑分:8B 打赢部分闭源大模型
商汤给出的 benchmark 结果覆盖了图像理解、图像生成与编辑、空间智能和视觉推理四个维度。结论是:U1 Lite 在同量级开源模型中全面 SOTA,而且 8B-MoT 这个"小个子"在部分任务上能打平甚至超过一些大型商业闭源模型。
具体来看几个关键对比:
- 图像生成质量:在通用图像生成测试中,U1 Lite 的生成质量比肩 Qwen-Image 2.0 Pro 和 Seedream 4.5 等闭源模型,同时推理响应速度更快
- 复杂信息图生成:这是开源模型一直做不好的领域——生成包含大量文字、表格、图表的信息图时,传统模型经常出现文字乱码、排版错乱。U1 Lite 在 BizGenEval 和 IGenBench 等信息图基准上表现出商业级水准
- 空间智能与视觉推理:模型能理解物理世界的复杂空间关系,这对于具身智能场景至关重要
当然,跑分归跑分,实际使用效果还需要社区验证。但从数据上看,统一架构在参数效率上的优势确实体现出来了——用更少的参数达到更好的效果,这正是 NEO-unify 架构的核心价值主张。
连续图文创作:不只是生成一张图
除了单次理解和生成,SenseNova U1 还有一个比较有意思的能力:连续性图文创作。
什么意思?传统的图文创作流程是这样的:先用语言模型生成文字,再把文字描述丢给图像生成模型出图,如果要生成多张图,每张图之间的风格一致性全靠 prompt 工程硬凑。这本质上是多个模型的串联调用,效率低,而且图与图之间的风格漂移几乎不可避免。
SenseNova U1 的做法是单次调用、单模型完成。因为图像和文本在同一个上下文窗口里被统一建模,前面生成的图像信息会自然地保留在上下文中,后续生成的图像可以直接"看到"前面的结果。这就像一个画家在同一张画布上连续创作,而不是每画一笔就换一个人。
商汤展示了两个案例:
案例一:五分熟牛排做法。模型先规划步骤,然后为每一步生成对应的图示。关键在于各步骤的图示风格高度一致——同样的厨房场景、同样的牛排外观、同样的光照风格,不会出现第一步是写实风、第三步突然变成卡通风的情况。
案例二:钢铁侠图案绘制。模型从一张草稿扫描开始,逐步细化,最终输出完成度很高的成品。每一步都精准保留了上一步的结构和细节,线条、比例、色彩在迭代过程中保持连贯。
这个能力的实际价值在于:它让"AI 图文创作"从"拼凑多个工具的输出"变成了"一个模型的连贯思考"。对于需要批量生成风格一致的图文内容的场景——比如产品说明书、教程、营销素材——这是一个实质性的效率提升。
技术判断:统一架构是不是正确方向?
坦率地说,"统一多模态架构"这个方向并不是商汤独家在做。Google 的 Gemini 从一开始就强调原生多模态,Meta 的研究团队也在探索类似思路。但在开源领域,大多数多模态模型——包括 LLaVA 系列、Qwen-VL、InternVL 等——仍然是拼接式架构。
拼接式架构的好处是工程上简单:拿一个现成的 LLM,接一个现成的视觉编码器,训练一个适配层就能跑。但它的天花板也很明显——模态之间的融合深度有限,信息在跨模态传递时必然有损耗,而且理解和生成往往需要不同的模块分别处理。
统一架构的难度在于训练。当你把视觉和语言放在同一个表征空间里,训练数据的配比、损失函数的设计、不同模态的学习速率平衡,都比拼接式架构复杂得多。这也是为什么之前大多数团队选择了更稳妥的拼接路线。
商汤这次的结果说明,统一架构在参数效率上的优势是真实存在的。8B 模型能打平部分闭源大模型,这不是靠数据量或训练时长堆出来的,而是架构本身带来的效率增益。如果这个结论能被社区复现验证,那它对整个多模态模型的发展方向会有比较大的影响。
不过也要看到局限性:目前开源的只是 Lite 版本,更大规格的模型还没放出来。统一架构在 scale up 时是否还能保持这种效率优势,是一个需要后续验证的问题。另外,技术报告尚未发布,架构的很多细节——比如训练策略、数据配比、token 化方案——还不清楚,社区要真正用起来还需要更多信息。
对开发者意味着什么
如果你在做多模态相关的应用开发,SenseNova U1 值得关注的点有几个:
1. 部署成本可能更低。8B 和 3B(激活参数)的规格意味着单卡就能跑,不需要多卡并行。对于中小团队来说,这是一个实际的门槛降低。
2. 图文一致性生成。如果你的场景需要生成多张风格一致的图片(教程、产品图、营销素材),U1 的连续创作能力可能比"LLM + 图像生成模型"的串联方案更好用。
3. 复杂信息图生成。这是一个长期以来的痛点——让 AI 生成包含准确文字、合理排版的信息图。U1 在这个方向上的表现如果确实如 benchmark 所示,那对很多 ToB 场景会有直接价值。
4. 具身智能的潜力。商汤提到 U1 未来可以作为机器人的"具身大脑",在单一模型内完成感知-推理-执行的闭环。这个方向目前还比较早期,但统一架构确实比拼接式架构更适合做这件事——因为机器人需要在视觉输入和动作输出之间做实时的、紧密耦合的推理。
想上手试试的话,代码和权重都在 GitHub 和 Hugging Face 上:
- GitHub:
https://github.com/OpenSenseNova/SenseNova-U1 - Hugging Face:
https://huggingface.co/collections/sensenova/sensenova-u1
商汤还开源了一套 SenseNova Skills 工具包,提供了信息图生成等场景的 Prompt 模板和样例,可以帮助快速上手。
竞争格局:开源多模态的新变量
把 SenseNova U1 放到当前的开源多模态格局里看:
- Qwen-VL 系列(阿里):目前开源多模态的标杆之一,但仍是拼接式架构
- InternVL 系列(上海 AI Lab):同样是拼接式,在理解任务上表现强劲
- DeepSeek-VL(DeepSeek):MoE 架构,侧重效率,但也是拼接式
- Janus 系列(DeepSeek):尝试了理解与生成的统一,但架构上仍保留了独立的视觉编码路径
SenseNova U1 是目前开源社区中,在"原生统一"这个方向上走得最彻底的模型之一。它不是在现有架构上做增量改进,而是提出了一个不同的架构范式。这种"另起炉灶"的做法风险更高,但如果成功,收益也更大。
从商汤自身的角度看,这次开源也是一个战略选择。商汤在大模型竞争中并不算第一梯队的玩家,但在多模态和视觉领域有深厚积累。选择在统一架构这个差异化方向上全面开源,既能建立技术品牌,也能借助社区力量加速迭代。
写在最后
多模态模型的发展正在经历一个从"拼接"到"统一"的范式转换。这个转换不会一夜之间完成,拼接式架构在工程成熟度和生态丰富度上仍有优势。但 SenseNova U1 的开源,至少证明了统一架构在效率和效果上的可行性。
对于开发者来说,现在多了一个值得认真评估的选项。建议等技术报告发布后,结合自己的具体场景做测试。跑分好看是一回事,实际用起来顺不顺手是另一回事。
商汤表示后续会继续 scale up,推出更大参数的 U1 模型。如果更大规格的模型也能保持这种参数效率优势,那统一架构的故事就会更有说服力。我们会持续关注。
参考来源
- 全面开源!商汤日日新SenseNova U1发布,迈向模型理解生成统一时代 - Linux.do — 社区讨论帖,包含完整发布信息
- SenseNova-U1 GitHub 仓库 — 模型代码与权重开源地址
- SenseNova U1 Hugging Face 合集 — Hugging Face 模型页面
