文心一言5.1预览版悄然登场,百度在憋什么?

百度文心一言5.1预览版近日现身LMSYS Chatbot Arena排行榜,官网也同步上线了相关入口,疑似即将开放公测。从竞技场排名来看,目前位列第13,表现尚可但缺乏惊喜。
文心一言5.1预览版悄然登场,百度在憋什么?
文心一言5.1的预览版出现在了LMSYS Chatbot Arena上,排名第13。与此同时,百度官网也悄悄上线了相关页面入口。没有发布会,没有李彦宏的PPT,甚至没有一篇官方博客——百度这次选择了一种非常低调的方式来试水下一代模型。
这件事本身不大,但信号很明确:文心5.1离正式发布不远了。
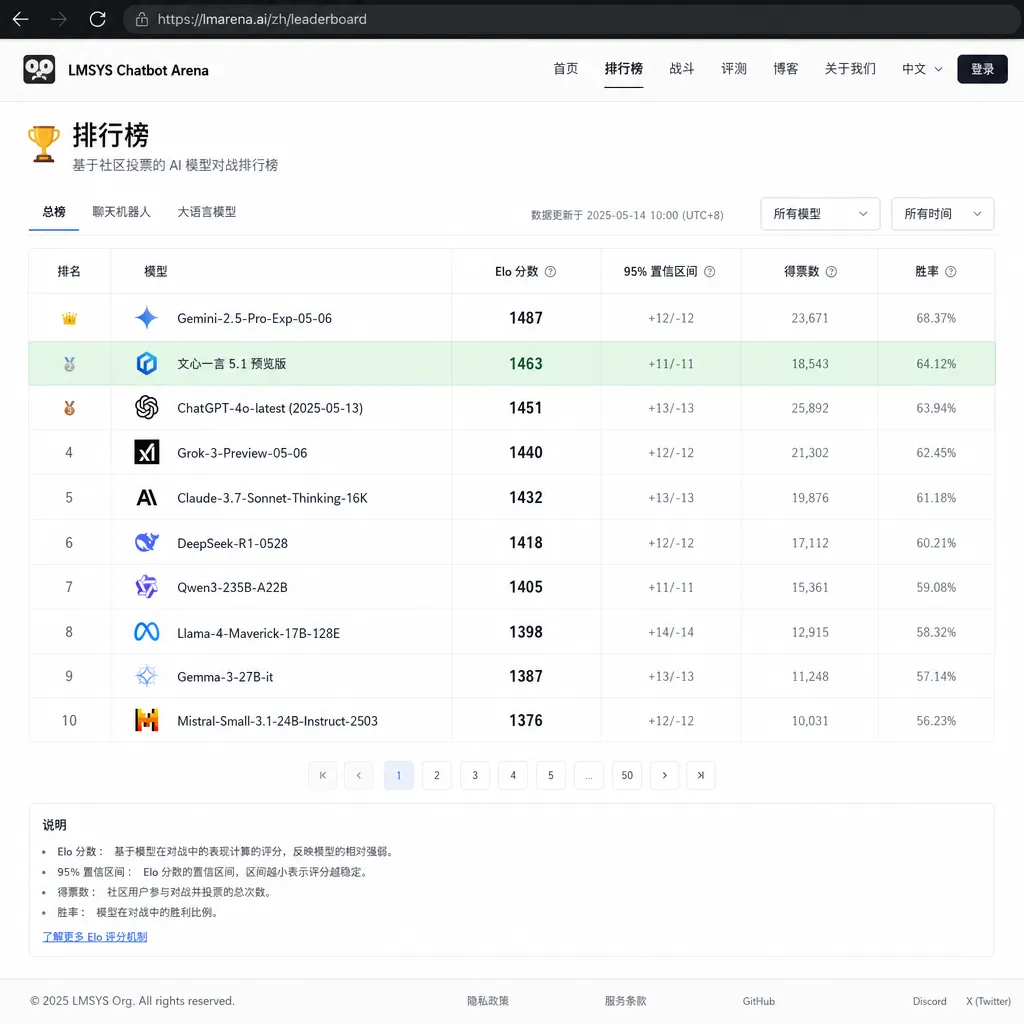
竞技场排名第13,什么水平?
先说数据。LMSYS Chatbot Arena是目前业内公认最有参考价值的大模型盲测排行榜,用户在不知道模型身份的情况下对两个模型的回答进行投票,排名完全由真实用户偏好驱动,不是跑benchmark刷出来的分数。
文心一言5.1预览版目前排在第13位。
这个名次怎么看?说好听点,稳居第一梯队尾部;说难听点,在当前这个竞争烈度下,第13名很难让人兴奋。排在它前面的,是GPT-4o、Claude 3.5 Sonnet、Gemini系列这些老面孔,也有近期势头凶猛的Grok、DeepSeek等新锐。
不过有一个关键信息目前缺失:我们不知道这个预览版的模型规模。
这很重要。如果文心5.1预览版是一个相对轻量的版本——比如对标GPT-4o-mini或Claude 3.5 Haiku这个级别——那第13名的成绩其实相当不错,说明百度在效率和性能的平衡上找到了一个好的点位。但如果这是百度倾尽全力的旗舰大杯,那这个排名就有点尴尬了。
从"预览版"这个命名来推测,大概率不是最终形态。百度很可能还在调优,竞技场上的表现更多是一次摸底测试,而非正式亮相。
从5.0到5.1,百度的迭代节奏
回顾一下时间线。
文心大模型5.0正式版在今年早些时候发布,号称拥有2.4万亿参数,在百度千帆平台开放了API调用,并接入了文心一言官网、百度慧播星、文心助手等一系列百度自家产品。5.0的发布声量不小,百度在参数规模上做足了文章。
但参数量这个叙事在2026年已经不太好使了。
过去一年,行业的共识已经从"谁的模型更大"转向了"谁的模型更聪明、更高效、更便宜"。DeepSeek用相对精简的架构打出了惊人的性价比,Google的Gemma 4系列刚刚证明了开源小模型也能在推理任务上硬刚大模型,OpenAI的o系列则把"思考"这件事变成了产品卖点。
在这个背景下,文心5.1如果只是5.0的参数量微调升级,意义不大。市场需要看到的是:百度在推理能力、多模态理解、长上下文处理、以及最关键的——中文场景深度优化上,到底做到了什么程度。
从5.0到5.1,版本号只跳了0.1,这通常意味着架构没有大改,更多是训练数据、对齐策略、推理效率上的优化。类似于OpenAI从GPT-4到GPT-4 Turbo的那种升级——不是换代,是打磨。
百度为什么选择"静默上线"?
这次文心5.1预览版的露面方式很有意思:先在第三方竞技场上跑分,官网同步挂出入口,但没有任何官方宣传。
社区的反应也很真实。在Linux.do论坛上,有开发者发帖指出了这个发现,但讨论热度并不高,帖子里甚至有人配了一张"无人在意.jpg"的表情包。7个帖子,7位参与者——这个数据本身就说明了一些问题。
百度选择低调,可能有几个原因:
第一,预览版确实还没准备好大规模曝光。 竞技场排名会随着投票数增加而波动,现在的第13名未必是最终位置。如果高调宣布后排名下滑,公关压力会很大。先悄悄放上去,等排名稳定了再做文章,是更稳妥的策略。
第二,百度可能在等一个更好的发布窗口。 最近大模型领域的新闻密度极高,Google刚发了Gemma 4,各家都在密集更新。在这个时间点硬蹭热度,很容易被淹没。不如等竞争对手的声浪过去,再找一个相对安静的窗口期集中发力。
第三,也是最现实的一个原因:百度需要先确认模型在真实用户场景下的表现。 竞技场的盲测是最好的试金石,比内部评测可靠得多。先拿到真实反馈,再决定正式版的调优方向,这是一个工程上很合理的做法。
国产大模型的竞技场困境
把视角拉远一点,文心5.1的竞技场表现其实折射出国产大模型的一个共同困境:在英文为主的评测体系里,中文模型天然吃亏。
LMSYS Chatbot Arena的用户群体以英文用户为主,评测任务也偏向英文场景。对于文心一言这种在中文场景下深度优化的模型来说,竞技场排名并不能完全反映它的真实实力。
这不是为百度找借口。事实上,DeepSeek在同样的评测体系下取得了更好的成绩,说明"中文模型在英文评测中吃亏"这个说法只能解释一部分差距,不能解释全部。
但这确实提出了一个值得思考的问题:我们是否需要一个更侧重中文能力的权威评测平台?
目前国内也有一些评测榜单,比如SuperCLUE、C-Eval等,但它们的公信力和影响力远不及LMSYS。原因很简单——LMSYS的盲测机制足够透明,用户基数足够大,而国内的评测平台要么样本量不够,要么评测方法不够透明,很难让开发者信服。
这是整个中文AI生态需要补的课。
对开发者意味着什么?
如果你是一个正在选型的开发者,文心5.1预览版的出现意味着几件事:
短期:观望为主
预览版不等于正式版。在百度正式开放API之前,不建议基于预览版的表现做任何技术决策。竞技场排名会变,模型能力也可能在正式版中有显著调整。
中期:关注千帆平台的动态
参考5.0的发布路径,文心5.1大概率会首先在百度千帆平台开放调用。如果你的业务已经在千帆平台上,可以关注平台的更新公告,争取第一时间拿到测试资格。
长期:多模型策略是正解
2026年的大模型市场,没有哪个模型能在所有场景下都是最优解。GPT在通用能力上依然强势,Claude在长文本和代码生成上有独到优势,DeepSeek在性价比上一骑绝尘,文心在中文理解和百度生态整合上有自己的护城河。
对于开发者来说,更务实的做法是搭建一个多模型调度架构,根据不同任务路由到最合适的模型。这也是为什么像OpenAI Hub这样的API聚合平台越来越受欢迎——一个接口对接所有主流模型,在模型之间切换的成本几乎为零。当文心5.1正式开放后,这类平台大概率也会第一时间接入。
百度AI的真正挑战不在模型
说句可能会得罪人的话:百度在大模型技术上并不差,但它的问题从来不是技术。
文心大模型从1.0到5.1,迭代速度不慢,技术投入不小,在中文NLP领域的积累也是实打实的。但百度的AI产品始终缺少一个"杀手级应用"——一个能让普通用户和开发者都离不开的东西。
对比来看:
- OpenAI 有ChatGPT,月活用户数以亿计,开发者生态也围绕GPT API建立了庞大的应用层
- Anthropic 有Claude,在企业级市场和开发者群体中口碑极好,尤其是代码和长文本场景
- Google 有Gemini深度整合进搜索、Gmail、Docs等十亿级用户产品
- DeepSeek 虽然没有C端爆款,但凭借开源策略和极致性价比,在开发者社区中建立了强大的品牌认知
百度呢?文心一言的C端产品存在感不强,千帆平台在开发者中的渗透率也远不及预期。模型能力是基础设施,但基础设施之上需要有足够强的应用层和生态来承接。
文心5.1能不能改变这个局面?坦率地说,仅靠模型升级很难。百度需要的是在产品体验、开发者工具链、定价策略上做出更有竞争力的选择。
一个值得关注的细节
最后提一个容易被忽略的点。
文心5.1选择在LMSYS竞技场上线预览版,这个动作本身就值得玩味。要知道,不是所有国产模型都愿意把自己放到国际竞技场上去比。这需要一定的自信,也需要一定的勇气。
在过去,国产大模型更倾向于在自己的主场——国内评测榜单、自家发布会、合作伙伴背书——来展示实力。主动去LMSYS这种"客场"接受全球用户的盲测检验,说明百度对文心5.1的能力有一定底气。
当然,第13名的排名也说明这个底气还不够硬。但至少方向是对的。
在大模型这场马拉松里,敢于把自己放到最透明的评测体系下接受检验,比关起门来自说自话要好得多。
接下来看什么?
几个值得持续关注的节点:
- 竞技场排名变化:随着投票数增加,文心5.1预览版的排名是上升还是下滑,会直接反映真实用户的偏好
- 官方正式公告:百度什么时候发布官方博客或召开发布会,会透露更多技术细节,包括模型规模、架构改进、训练数据等
- 千帆平台API开放:对开发者来说,这是最实际的里程碑。能调API了,才能真正评估模型在自己业务场景下的表现
- 定价策略:在DeepSeek把API价格打到地板的今天,文心5.1的定价会直接影响它的市场竞争力
百度在AI上的投入毋庸置疑,但投入和产出之间还隔着产品力、生态和市场认知。文心5.1是一个新的起点,但远不是终点。
让我们等正式版出来,再做最终判断。
参考来源
- 文心一言5.1预览版上竞技场了 - Linux.do(社区开发者发现文心5.1预览版出现在LMSYS排行榜的讨论帖)
- 2.4万亿参数!百度发布文心大模型5.0正式版 - 知乎(文心大模型5.0正式版发布详情及千帆平台开放调用信息)
