苹果LaDiR:让大模型学会「多线程思考」

苹果联合UCSD发布LaDiR框架,将扩散模型的并行探索能力嫁接到LLM推理阶段,让模型同时走多条推理路径再择优输出,在数学和代码生成任务上显著超越现有方法。
苹果LaDiR:让大模型学会「多线程思考」
苹果今天放出了一篇值得认真读的论文。
联合加州大学圣迭戈分校(UCSD),苹果在新版论文《LaDiR: Latent Diffusion Enhances LLM Text Reasoning》中提出了一个通用推理增强框架——LaDiR。核心想法不复杂:让大语言模型在给出最终答案之前,先并行探索多条推理路径,然后再用自回归方式输出最优结果。
这不是又一个新模型。它是一个可以叠加在现有模型之上的框架,改变的是模型「怎么想」,而不是「用什么想」。
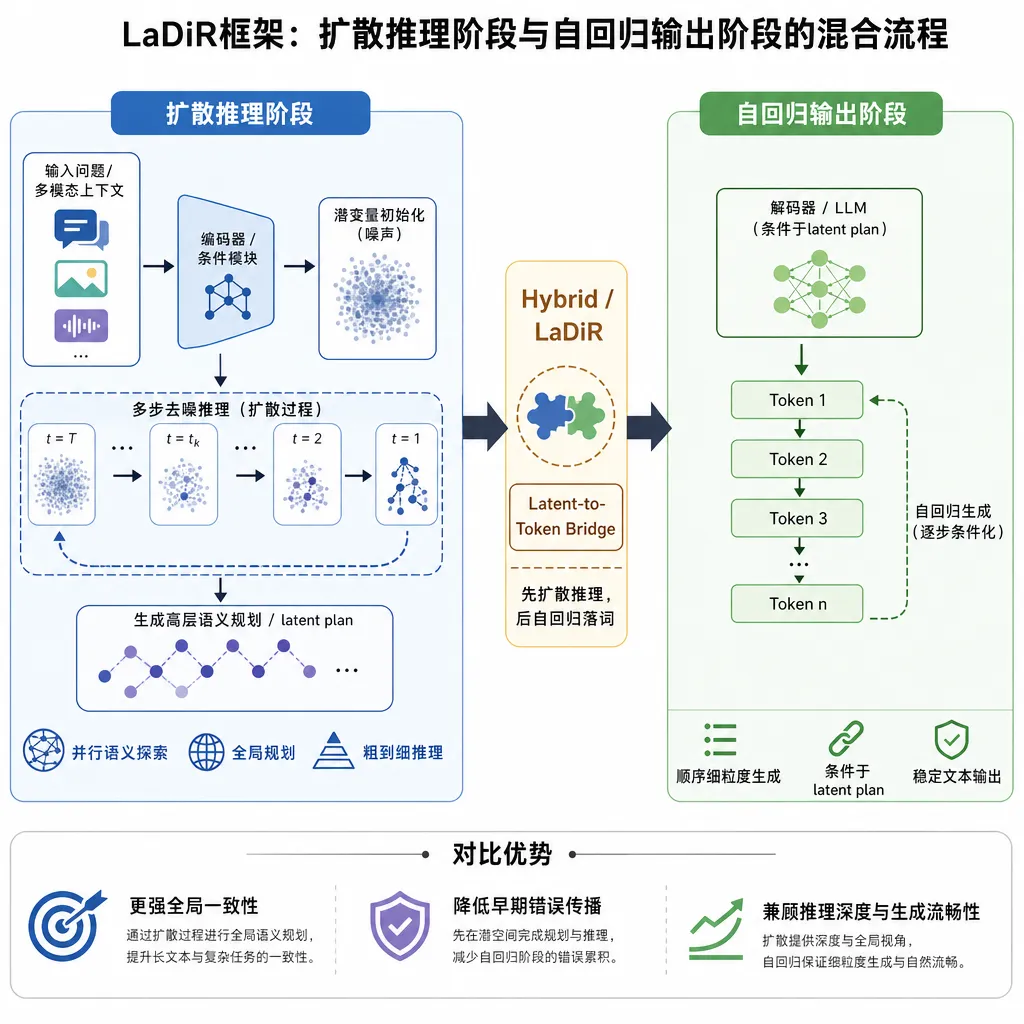
先说清楚问题出在哪
当前主流LLM的推理方式,本质上是「单线程」的。
自回归生成的机制决定了模型只能一个token接一个token地往下走。遇到复杂数学题或多步推理任务时,模型一旦在早期步骤走偏,后面基本没有纠错的机会——它只能沿着已经选定的路径继续生成。这就像在迷宫里只允许你走一条路,走错了不能回头。
业界当然有应对方案。Chain-of-Thought(CoT)让模型把推理过程写出来,Best-of-N采样让模型生成多个答案再挑最好的,Tree-of-Thought则尝试在推理过程中做分支搜索。但这些方法有一个共同的局限:它们要么是在输出层面做文章(生成多个完整答案再选),要么是串行地逐步展开推理树,计算开销随分支数指数增长。
换句话说,现有方法要么不够深入(只在结果层面做多样性),要么不够高效(串行搜索太慢)。
LaDiR想解决的就是这个问题:能不能让模型在推理阶段真正并行地探索多条路径,而且这些路径之间还能保持足够的多样性?
LaDiR的核心设计:扩散做推理,自回归做输出
框架的设计思路可以用一句话概括:推理阶段用扩散模型的方式来做,输出阶段用自回归模型的方式来做。
这是一个相当聪明的组合。
为什么推理阶段要用扩散?
扩散模型(Diffusion Model)在图像生成领域已经证明了自己的能力。它的核心优势在于:从随机噪声出发,通过迭代去噪,逐步逼近目标分布。这个过程天然支持并行——你可以同时从不同的噪声起点出发,得到不同的生成结果。
把这个思路搬到文本推理上:每条推理路径从一个随机噪声向量开始,在潜在空间(latent space)中通过多步去噪,逐渐演化成一条连贯的推理链。多条路径可以同时进行,互不干扰。
这比自回归方式的串行搜索高效得多。自回归模型要探索N条路径,就得串行生成N次;扩散模型可以一次性并行处理。
为什么输出阶段还是用自回归?
因为自回归模型在文本生成的连贯性和流畅性上,目前仍然是最强的。扩散模型在潜在空间里做推理规划很擅长,但要把推理结果转化成高质量的自然语言文本,自回归解码器更靠谱。
这就像是:扩散模型负责「想清楚怎么解题」,自回归模型负责「把解题过程写出来」。各司其职。
具体怎么工作?
LaDiR的工作流程分为几个关键步骤:
- 编码阶段:将输入问题通过编码器映射到潜在空间
- 扩散推理阶段:从随机噪声出发,启动多条并行的推理路径,每条路径通过迭代去噪逐步形成推理方案
- 多样性保持:通过排斥机制(repulsion mechanism)防止多条路径收敛到同一个解
- 择优与解码:从候选推理路径中选择最优方案,交给自回归解码器生成最终文本输出
其中第三步是整个框架最关键的设计之一,值得展开说说。
多样性鼓励机制:防止「殊途同归」
并行推理听起来很美好,但有一个现实问题:如果多条路径最终都收敛到同一个答案,那并行就失去了意义。这就像让五个人同时解一道题,结果五个人用的都是同一种方法——你并没有真正扩大搜索空间。
LaDiR引入了一种排斥机制来解决这个问题。在扩散去噪的过程中,框架会计算不同路径之间的相似度,当两条路径在潜在空间中靠得太近时,会施加一个「排斥力」,把它们推开。
这个设计的灵感可能来自物理学中的粒子排斥——同性电荷之间的库仑力会阻止它们聚集在一起。在LaDiR中,这种排斥力确保了每条推理路径都在探索不同的解题思路,最终生成一个真正多样化的候选答案池。
这比简单的温度采样(通过调高temperature来增加随机性)要优雅得多。温度采样增加的是「随机性」,而LaDiR增加的是「多样性」——前者可能让模型胡说八道,后者则是让模型系统性地探索不同的合理路径。
实验结果:数学和代码上的表现
研究团队在两个基座模型上做了测试:Meta的LLaMA 3.1 8B和阿里的Qwen3-8B-Base。选择8B参数量级的模型,显然是为了证明框架在中等规模模型上就能生效,不需要动辄几百B的大模型。
数学推理
在标准数学基准测试上,LaDiR取得了比现有方法更高的准确率。更值得关注的是在分布外(out-of-distribution)任务上的表现——也就是那些训练时没见过的、更难的题目。
这说明LaDiR带来的不只是「刷分」式的提升,而是模型推理能力的实质性增强。在分布内任务上,各种方法的差距可能不大;但在分布外任务上,能不能真正「想明白」就拉开差距了。并行探索多条路径的优势在这里体现得最明显:当问题足够难、正确路径足够隐蔽时,多路径搜索找到正确解的概率自然更高。
代码生成
在HumanEval代码生成基准上,LaDiR生成的代码更加可靠,尤其在难题上的表现明显优于标准微调方法。
代码生成是一个很好的测试场景,因为代码的正确性是可以客观验证的——要么能跑通测试用例,要么不能。LaDiR在这个任务上的优势,说明并行推理路径确实帮助模型找到了更多正确的实现方案。
谜题规划
在谜题规划任务中,LaDiR能探索更广泛的解空间,找到正确解的概率高于所有通用基准模型。
但论文也诚实地指出了一个局限:在单次尝试准确率(pass@1)上,LaDiR仍然略逊于那些专门针对特定任务优化的专用模型。这其实不意外——通用框架追求的是广泛适用性,而专用模型可以把所有优化都集中在一个任务上。这是一个经典的通用性vs专精性的权衡。
技术上的几个值得注意的点
它是框架,不是模型
这一点怎么强调都不过分。LaDiR不需要从头训练一个新模型,而是可以叠加在现有的LLM之上。这意味着:
- 已有的模型投资不会浪费
- 随着基座模型的升级,LaDiR的效果理论上也会跟着提升
- 部署成本相对可控,不需要替换整个推理栈
对于已经在生产环境中部署了LLM的团队来说,这种「即插即用」的特性比一个全新的模型更有吸引力。
潜在空间推理 vs 文本空间推理
传统的CoT推理是在文本空间中进行的——模型把每一步推理都写成自然语言。LaDiR的推理则发生在潜在空间中,这带来了两个好处:
- 效率更高:潜在空间的表示比文本更紧凑,计算量更小
- 灵活性更强:不受自然语言表达的限制,可以表示更抽象的推理关系
当然,这也意味着推理过程的可解释性可能会下降——你没法像读CoT那样直接看到模型在「想什么」。这是一个值得关注的权衡。
推理成本的考量
并行多路径推理必然带来额外的计算开销。论文中没有特别详细地讨论推理延迟和计算成本的增加幅度,但可以合理推测:路径数量越多,计算成本越高。
在实际部署中,这意味着需要在推理质量和推理成本之间找到平衡点。对于简单问题,可能一条路径就够了;对于复杂问题,多路径探索的收益才能覆盖额外的成本。如何动态调整路径数量,可能是后续工程化需要解决的问题。
放在更大的背景下看
苹果发布LaDiR,放在当前AI推理能力竞赛的大背景下看,有几层意味。
第一,推理增强正在成为新战场。 OpenAI的o系列模型、DeepSeek-R1、Anthropic的Claude在推理上的持续投入,都说明业界已经意识到:单纯靠扩大模型规模来提升推理能力的路径正在遇到瓶颈,需要在推理方法论上做创新。LaDiR是苹果在这个方向上的一次重要尝试。
第二,扩散模型正在从图像领域向文本领域渗透。 过去两年,扩散模型在图像和视频生成上大放异彩,但在文本领域的应用一直比较有限。LaDiR证明了扩散模型的核心思想——从噪声到信号的迭代优化——在文本推理中同样有价值。这可能会启发更多将扩散思想应用于NLP的研究。
第三,苹果的AI策略越来越清晰。 苹果在大模型领域一直被认为是「慢半拍」的玩家,但从Apple Intelligence到现在的LaDiR,可以看到苹果的路线:不追求训练最大的模型,而是在推理效率和推理质量上做文章。这与苹果一贯的「端侧优先」策略是一致的——如果能用更小的模型配合更好的推理框架达到大模型的效果,那在iPhone和Mac上部署AI就更现实了。
第四,混合架构可能是未来方向。 纯自回归、纯扩散都有各自的局限,LaDiR的混合方案提供了一个新思路:不同的生成范式可以在不同阶段发挥各自的优势。这种「组合式创新」可能比单一范式的极致优化更有前景。
对开发者意味着什么
如果你在做LLM应用开发,LaDiR目前还处于论文阶段,短期内不会直接影响你的工作流。但有几个趋势值得关注:
- 推理时计算(inference-time compute)的重要性在上升。 越来越多的研究表明,在推理阶段投入更多计算资源,比单纯增大模型参数更有性价比。LaDiR是这个方向的又一个证据。
- 多路径推理可能成为标配。 未来的LLM API可能会提供类似「推理路径数量」的参数,让开发者根据任务难度动态调整。
- 框架层面的创新值得关注。 不是所有进步都来自更大的模型。像LaDiR这样的框架级创新,可能会以更低的成本带来显著的能力提升。
对于关注前沿模型能力的开发者,各家基于LaDiR思路优化后的新模型一旦上线,通过 OpenAI Hub 这类聚合平台可以第一时间接入测试,省去逐个对接的麻烦。
局限与展望
客观地说,LaDiR目前还有一些需要解决的问题:
- 单次准确率仍有差距:在pass@1指标上不如专用模型,说明框架在「一次就答对」的能力上还有提升空间
- 推理成本:多路径并行带来的额外计算开销需要更详细的量化分析
- 可解释性:潜在空间推理的黑箱程度比文本空间推理更高
- 工程化挑战:从论文到生产部署,还需要解决大量工程问题
但方向是对的。让模型在回答之前「多想几条路」,这个直觉上就合理的思路,现在有了一个系统性的技术方案。接下来就看苹果和社区能把它推进到什么程度了。
参考来源
- 苹果发布 AI 框架 LaDiR:突破单一思维,并行探索多条推理路径 - IT之家(首发报道,包含框架核心机制与实验结果详解)
- 弥补LLM自回归推理缺陷!苹果联合提出LaDiR:潜在扩散增强文本推理 - 知乎(技术细节深度解读,包含排斥机制与多样性推理分析)
