阿里开源Qwen-Scope:给大模型装上X光机

阿里千问今日开源可解释性模块 Qwen-Scope,通过在 Qwen3/3.5 系列模型中插入稀疏自编码器(SAE),将黑箱参数转化为人类可理解的特征,覆盖推理控制、数据合成、训练优化和评测分析四大场景。
大模型终于可以被「看懂」了
4 月 30 日,阿里千问团队正式开源 Qwen-Scope——一套基于 Qwen3 和 Qwen3.5 系列模型训练的可解释性模块。简单说,它给大模型装了一台 X 光机:不改模型结构,不影响推理性能,但能把模型内部那些密密麻麻的参数运算,翻译成人类能理解的概念和规律。
这不是一个学术 demo。本次开源覆盖 7 个大模型、14 组稀疏自编码器(SAE)权重,横跨稠密模型和混合专家(MoE)模型,每组权重都用对应模型的预训练数据采样了 5 亿词元进行训练。阿里直接把工具、权重、技术报告一起放了出来,摆明了要让社区用起来。
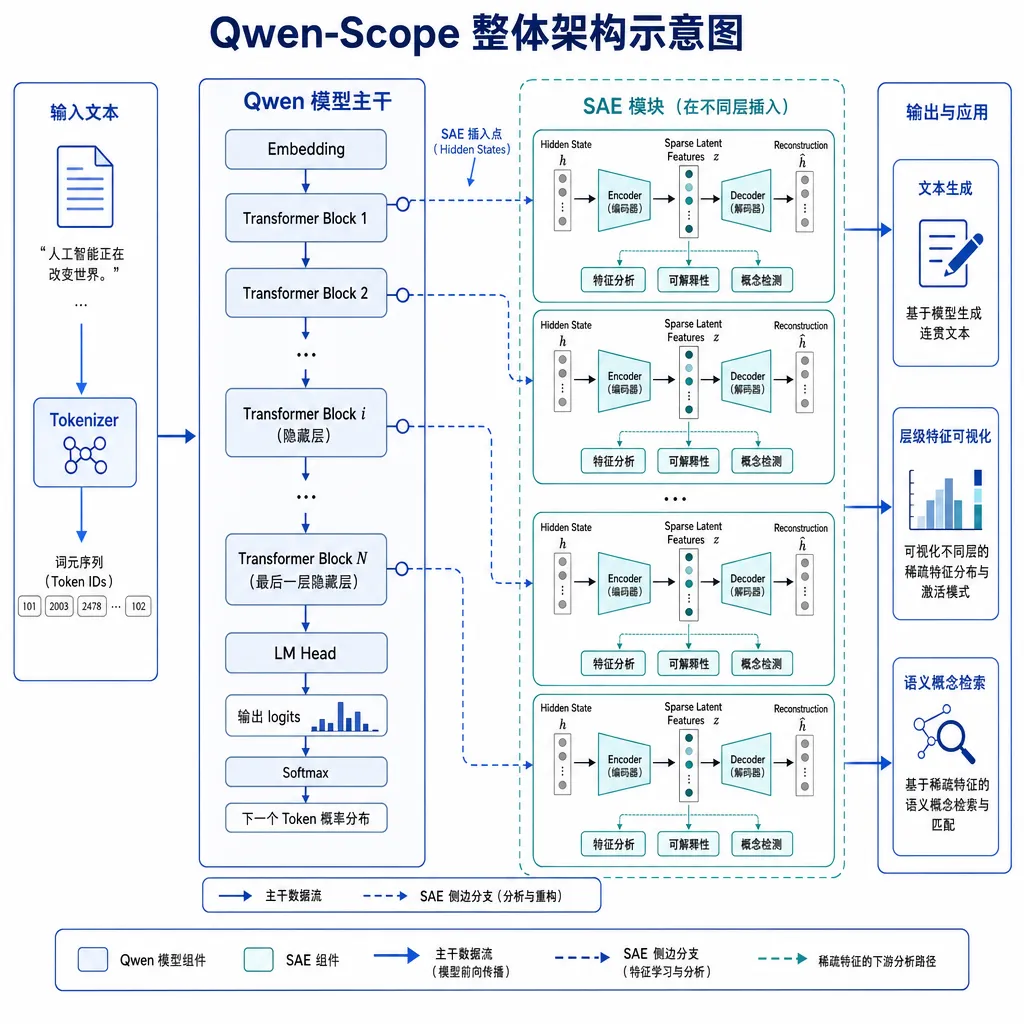
核心原理:用稀疏自编码器拆解黑箱
要理解 Qwen-Scope 在做什么,先得明白一个问题:大模型的隐藏层表示是高度纠缠的。一个 4096 维的向量里,可能同时编码了语言、情感、事实、逻辑等几十种信息,彼此叠加在一起,人类根本看不懂。
Qwen-Scope 的做法是在 Qwen 的隐藏层中插入稀疏自编码器(Sparse Autoencoder, SAE)。SAE 的核心思路并不复杂:
- 编码:把隐藏层的稠密向量映射到一个更高维的空间
- 施加稀疏约束:强制大部分维度为零,只保留少数激活的特征
- 解码:用这些稀疏特征重建原始向量
打个比方,原来模型内部的信息像一杯混合果汁,你知道它好喝但说不清里面有什么。SAE 做的事情就是把这杯果汁重新分离成苹果汁、橙汁、葡萄汁——每种成分单独可辨认,而且混在一起还能还原出原来的味道。
这种「稀疏性约束」带来的好处是:提取出的特征高度解耦、低冗余,每个特征往往对应一个明确的语义概念。比如某个特征可能专门在模型处理「中文古诗」时激活,另一个特征则在「代码生成」场景下亮起来。
这个方向并非阿里首创。Anthropic 在 2024 年就发表过用 SAE 解释 Claude 内部特征的研究,OpenAI 也做过类似工作。但 Qwen-Scope 的差异在于:它不只是一个研究工具,而是直接面向工程应用,提供了从分析到优化的完整链路。
四大应用场景:不只是「看懂」,更能「改进」
可解释性听起来像是学术界的事,但 Qwen-Scope 的野心显然不止于此。阿里给出了四个落地方向,每个都直指开发者的实际痛点。
1. 推理控制:不用写 prompt 就能改输出
这是最直观也最有想象力的场景。通过直接控制 SAE 特征的激活强度,可以在不修改输入 prompt 的情况下,定向改变模型的输出行为。
举几个例子:
- 语言切换:找到控制「中文输出」的特征,调高它的激活值,模型就会倾向于用中文回答,即使用户用英文提问
- 风格调整:激活「正式/学术」相关特征,输出风格就会从口语化变成书面化
- 实体替换:定位到特定实体的特征,可以引导模型在回答中提及或回避某些内容
这意味着什么?传统的 prompt engineering 本质上是在用自然语言「说服」模型,效果不稳定,还经常需要反复调试。而特征级别的控制是直接在模型内部「拧旋钮」,精度和可控性完全不在一个量级。
对于需要精细控制模型行为的场景——比如企业级应用中的合规输出、多语言客服系统的语言路由——这种能力非常有价值。
2. 数据分类与合成:用更少的标注做更多的事
数据标注贵、慢、质量不稳定,这是所有做模型训练的团队都头疼的问题。Qwen-Scope 提供了一个巧妙的替代思路。
数据分类方面,以毒性检测为例:只需要少量已标注的毒性样本作为种子数据,分析这些样本在 SAE 特征上的激活模式,就能筛选出与毒性高度相关的特征。之后用这些特征去扫描未标注数据,整个过程不需要额外训练分类器,标注和训练成本大幅下降。
数据合成方面更有意思。SAE 能发现模型中那些「未被充分激活」的特征——这些特征对应的往往是模型的能力盲区或长尾场景。根据这些信息,可以定向构造训练数据来补足短板,而不是盲目地堆数据量。
这就像是给模型做了一次全面体检,哪里弱一目了然,然后对症下药。比起传统的「先训练再评测再补数据」的循环,效率提升是显而易见的。
3. 训练优化:定位并修复模型的「坏习惯」
大模型在微调过程中经常出现一些顽固的低级错误,比如:
- 语言混用:回答中文问题时突然蹦出几个英文单词
- 重复生成:陷入循环,反复输出相同的句子
- 格式错乱:该输出 JSON 的时候格式不对
这些问题用传统方法很难定位根因。你知道模型「犯了错」,但不知道它为什么犯错,只能靠堆更多数据或者调超参来碰运气。
Qwen-Scope 可以直接分析出这些异常行为对应的特征激活模式。找到了「病灶」,就可以在监督微调(SFT)和强化学习(RLHF/DPO)阶段针对性地处理,降低这类回复出现的频率。
这对模型训练团队来说是一个实质性的效率提升。与其在黑箱里反复试错,不如先用 Qwen-Scope 做一次诊断,搞清楚问题出在哪,再动手修。
4. 评测分析:让 benchmark 不再「内卷」
现在大模型评测有个公开的秘密:很多评测集之间高度重叠,测来测去其实在测同一种能力。团队花了大量算力跑 benchmark,但信息增量很有限。
Qwen-Scope 可以计算不同样本、不同评测集之间的特征激活模式相似度,量化评测的冗余程度。这样就能:
- 从一堆 benchmark 中挑出真正互补的子集
- 用更少的评测覆盖更多的能力维度
- 降低评测成本的同时提升评测质量
对于资源有限的团队来说,这意味着可以把算力花在刀刃上,而不是重复验证已经知道的结论。
开源细节:覆盖面够广,诚意够足
本次 Qwen-Scope 开源的规模值得关注:
| 维度 | 覆盖范围 | |------|----------| | 模型系列 | Qwen3、Qwen3.5 | | 模型类型 | 稠密模型 + 混合专家模型(MoE) | | 模型数量 | 7 个 | | SAE 权重组数 | 14 组 | | 训练数据规模 | 每组 0.5B 词元(从预训练数据采样) |
14 组权重意味着每个模型在不同层都有对应的 SAE,开发者可以选择分析模型的浅层(更偏语法和词汇)还是深层(更偏语义和推理)。
训练数据直接从预训练语料采样,保证了 SAE 学到的特征分布与模型实际使用时一致,而不是在某个特定任务上过拟合。这个细节很重要——如果 SAE 的训练数据和模型的预训练数据分布不一致,提取出的特征就不可靠。
行业视角:可解释性为什么突然重要了
可解释性(Interpretability)在 AI 领域一直是个「重要但不紧急」的话题。大家都知道黑箱不好,但模型能力在飞速提升,谁有空停下来研究为什么?
但风向在变。几个推动力正在汇聚:
监管压力。欧盟 AI 法案已经生效,对高风险 AI 系统明确要求可解释性。国内的《生成式人工智能服务管理暂行办法》也在推动类似方向。企业要合规部署大模型,「能解释模型为什么这么输出」正在从加分项变成必选项。
工程需求。随着大模型从 demo 走向生产,开发者需要更精细的调试工具。prompt engineering 能解决 80% 的问题,但剩下 20% 的疑难杂症——模型幻觉、输出不一致、边界 case 失控——需要深入模型内部才能定位。
竞争格局。Anthropic 一直在可解释性上投入重兵,去年发布的 Claude 内部特征分析引发了广泛关注。OpenAI 也有相关研究。阿里选择在这个时间点开源 Qwen-Scope,既是技术积累的释放,也是在开源生态中卡位。
从竞品对比来看,Anthropic 的工作更偏研究性质,论文写得漂亮但工具链不够完整。Qwen-Scope 的优势在于直接面向工程场景,四个应用方向都有明确的落地路径。当然,劣势也很明显:它只能用于 Qwen 系列模型,通用性不如一个与模型无关的可解释性框架。
对开发者意味着什么
如果你正在用 Qwen 系列模型做开发,Qwen-Scope 值得认真看一看。几个具体的使用建议:
- 模型调试:下次遇到模型输出异常,先用 Qwen-Scope 分析一下特征激活,可能比盲目调 prompt 更高效
- 数据工程:如果你在做垂直领域微调,用 SAE 特征来分析训练数据的覆盖度,找出能力盲区,再定向补数据
- 产品功能:特征级别的输出控制可以做成产品功能,比如让用户自己调节回答风格,而不是靠 system prompt 硬编码
如果你用的不是 Qwen 系列,这个项目的价值更多在于方法论层面。SAE 用于模型可解释性的技术路线正在被多家头部实验室验证,未来大概率会成为大模型开发的标配工具。现在了解一下原理和应用场景,不亏。
写在最后
大模型发展到今天,「能力」不再是唯一的竞争维度。谁能让模型更可控、更可解释、更可信赖,谁就能在企业级市场拿到更多筹码。
Qwen-Scope 的开源,是阿里在这个方向上的一次明确表态。它不完美——只支持自家模型、社区生态还需要时间建设——但方向是对的,工程化程度也够用。
对于整个行业来说,当头部玩家开始把可解释性工具开源出来,而不是藏在论文里,这本身就是一个积极信号。大模型不应该永远是黑箱。
参考来源
- 看穿大模型的"小心思":阿里千问开源可解释性模块 Qwen-Scope - IT之家:IT之家对 Qwen-Scope 发布的详细报道,包含官方介绍全文
