DeepSeek让模型边想边"指"

DeepSeek联合北大清华发布「视觉原语思考」框架,将坐标点和边界框嵌入思维链,让多模态模型在推理时能直接"指向"图像位置,在拓扑推理等任务上大幅超越GPT-5.4、Claude Sonnet 4.6等前沿模型。
DeepSeek 发布视觉原语思考框架:让多模态模型边推理边"指"
DeepSeek 联合北京大学、清华大学发布了一篇名为《Thinking with Visual Primitives》的论文,并同步开源了完整代码仓库。这个框架做了一件听起来简单但此前没人做好的事——让多模态模型在推理过程中,像人用手指着图说话一样,直接"指向"图像中的具体位置。
不是先看完图再回答,而是边想边指。
核心思路:坐标就是思考的一部分
过去的多模态推理模型,处理图像的方式大多是"看一眼,记住,然后用文字推理"。图像信息在进入语言推理链之后,就变成了纯文本描述,空间信息在这个过程中大量丢失。你让模型数一数图里有几个红色方块,它可能数错;你让它判断 A 在 B 的左边还是右边,它可能靠猜。
视觉原语思考(Thinking with Visual Primitives)的做法是:把空间标记——具体来说是坐标点(points)和边界框(bounding boxes)——直接提升为思维链中的最小思考单元。
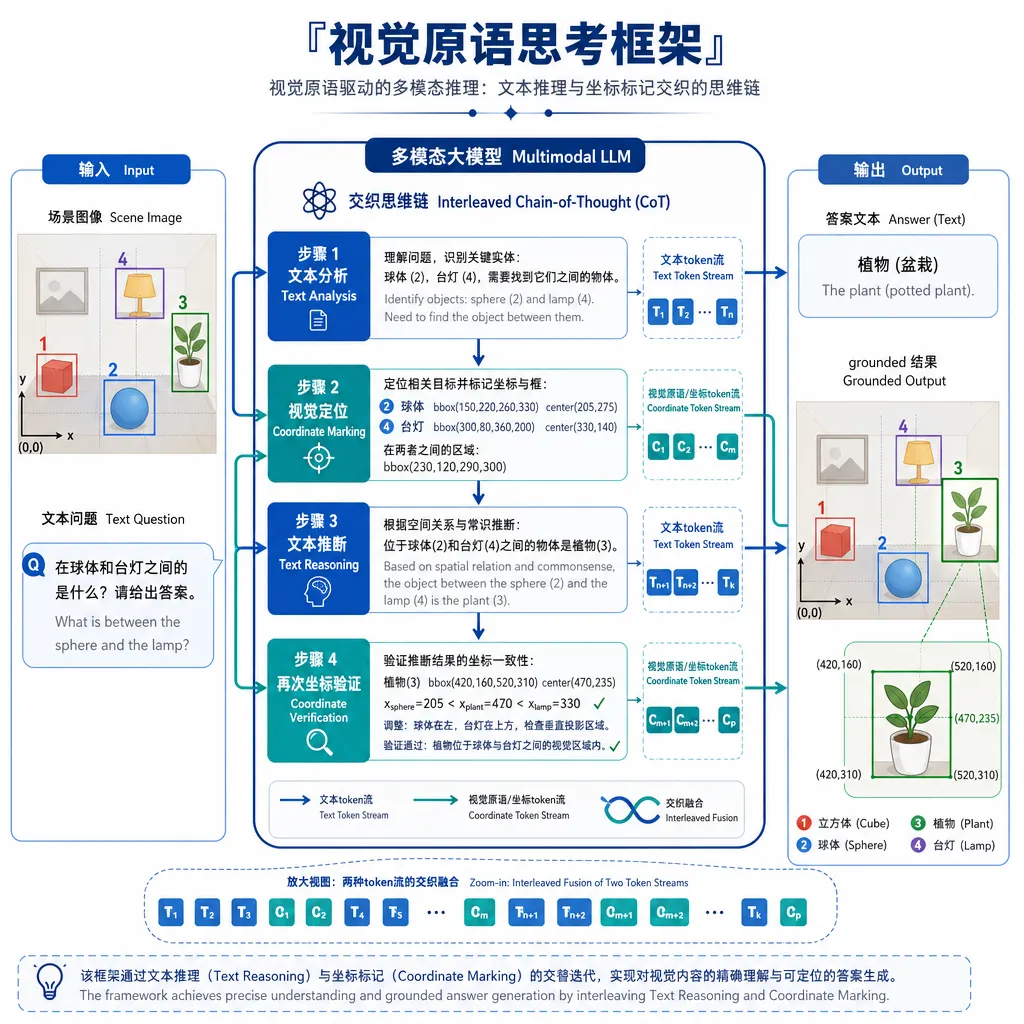
什么意思?传统的 Chain-of-Thought 推理是这样的:
思考步骤1: 图中有三个物体,分别是...
思考步骤2: 红色方块在蓝色圆形的右侧...
思考步骤3: 所以答案是...
视觉原语思考的推理链则是这样的:
思考步骤1: 我看到一个物体 [point: (234, 156)],它是红色方块
思考步骤2: 另一个物体 [bbox: (45, 89, 120, 200)],是蓝色圆形
思考步骤3: [point: (234, 156)] 在 [bbox: (45, 89, 120, 200)] 的右侧
思考步骤4: 所以答案是...
坐标不再是推理结束后的输出,而是推理过程中的锚点。模型每一步思考都可以"指"回图像,确认自己在说的到底是哪个东西、在什么位置。这个设计直觉上很合理——人在分析复杂图像时,也是边看边指边想,而不是闭上眼睛回忆。
技术实现:怎么让模型学会"指"
框架的技术实现分几个关键层面。
视觉原语的定义
论文定义了两种视觉原语:
- 坐标点(Point):图像中的单个位置,用 (x, y) 表示,适合标记物体中心、关键特征点
- 边界框(Bounding Box):用 (x1, y1, x2, y2) 表示的矩形区域,适合框定物体范围
这两种原语覆盖了绝大多数空间推理场景。坐标点解决"在哪"的问题,边界框解决"多大范围"的问题。
训练策略
模型并不是天生就会在思维链里插入坐标的。论文采用了一套专门的训练流程,核心是构建包含视觉原语标注的推理数据。训练数据中,每一步推理都可能包含对图像位置的显式引用,模型通过学习这些数据,逐渐掌握了"在思考过程中引用空间位置"的能力。
值得注意的是,当前版本的视觉原语思考能力需要通过显式触发词来激活。也就是说,你需要在 prompt 中告诉模型"请使用视觉原语进行推理",它才会启用这个能力。模型还不能自主判断什么时候该用、什么时候不用。这是论文明确指出的局限之一。
与现有架构的兼容
框架并没有对模型架构做大刀阔斧的改动,而是在现有多模态模型的基础上,通过扩展 token 词表和调整训练数据来实现。坐标信息被编码为特殊 token 序列,与文本 token 在同一个序列中处理。这意味着它可以相对容易地迁移到其他多模态模型上。
评测结果:拓扑推理上拉开断层差距
论文在 7 项公开基准和 4 项自建基准上做了评测,对比对象包括 GPT-5.4、Claude Sonnet 4.6、Gemini 3 Flash 等当前最强的多模态模型。
整体结果:平均得分 77.2%,所有被测模型中最高。
但真正有意思的不是平均分,而是具体任务上的表现差异。
常规任务:稳定领先
在计数(counting)和空间推理(spatial reasoning)这两类任务上,视觉原语思考模型表现稳定领先。这并不意外——当模型能在推理过程中精确标记每个物体的位置时,数数和判断空间关系自然更准确。
想象一下,让你数一张密密麻麻的图里有多少个红点。如果你能边数边用笔标记已经数过的,准确率肯定比纯靠记忆高。视觉原语思考做的就是这件事。
拓扑推理:断层式领先
最值得关注的是拓扑推理任务。论文自建了迷宫导航(Maze Navigation)和路径追踪(Path Tracing)两项基准:
| 任务 | 视觉原语思考 | GPT-5.4 | Claude Sonnet 4.6 | Gemini 3 Flash | |------|-------------|---------|-------------------|----------------| | 迷宫导航 | 66.9% | <51% | <51% | <51% | | 路径追踪 | 56.7% | <51% | <51% | <51% |
其余所有前沿模型在这两项任务上均未超过 51%——基本等于随机猜。而视觉原语思考模型分别达到了 66.9% 和 56.7%。
这个差距说明了什么?
拓扑推理要求模型理解图像中元素之间的连接关系和路径结构。这类任务对空间信息的依赖极高,纯文本推理链几乎无法胜任。你试试闭上眼睛走迷宫就知道了——不盯着图看,光靠"左转右转"的文字描述,根本走不出去。
视觉原语思考让模型在推理每一步时都能"指"回迷宫的具体位置,追踪当前在哪、下一步往哪走。这是其他模型做不到的。
这也暴露了一个行业现实:当前主流多模态模型在拓扑推理方面几乎是空白。 不是差一点,是基本不会。
为什么这个方向重要
视觉原语思考解决的不是一个学术玩具问题,而是多模态 AI 落地中的真实痛点。
工业质检与医学影像
在工业质检场景中,模型需要在一张复杂的电路板图像上找到缺陷位置,并解释为什么这是缺陷。传统多模态模型可能能说"图中有一处焊接不良",但说不清在哪。视觉原语思考可以在推理过程中精确标记缺陷坐标,输出类似"位置 (345, 678) 处的焊点面积不足,与相邻焊点 (350, 690) 相比偏小 40%"这样的结果。
医学影像分析同理。放射科医生看片子时,是边看边指边分析的。一个能"指"的 AI 辅助系统,比一个只能给出文字结论的系统有用得多。
自动驾驶与机器人
自动驾驶的感知模块需要精确的空间推理能力。"前方有行人"不够,需要知道行人在画面中的精确位置、运动方向、与车辆的相对距离。视觉原语思考的框架天然适合这类需要持续追踪空间位置的推理任务。
机器人操作也是类似的场景——"把红色杯子放到桌子左边"这个指令,需要模型在推理过程中持续锚定杯子和桌子的空间位置。
文档理解与数据提取
复杂文档(如建筑图纸、流程图、信息图表)的理解,本质上也是空间推理问题。元素之间的连接关系、层级关系、流向关系,都编码在空间布局中。能"指"的模型在处理这类任务时有天然优势。
局限性:诚实比漂亮的数字更重要
论文对自身局限的讨论相当坦诚,这在当前"刷榜至上"的氛围中值得肯定。
分辨率瓶颈。 受限于输入图像的分辨率,模型在细粒度场景中的坐标输出偶有偏差。简单说,如果图像中的目标太小或太密集,模型"指"的位置可能不够准。这是当前所有视觉模型的通病,但对于一个以精确空间标记为核心能力的框架来说,这个问题更加突出。
需要显式触发。 前面提到了,视觉原语思考能力目前需要通过特定的 prompt 触发词来激活。模型不能自主判断"这个问题需要我边想边指"。这意味着在实际应用中,用户或上层系统需要预先判断任务类型,增加了使用门槛。
泛化能力有限。 以坐标点解决复杂拓扑推理的能力,在跨场景泛化上还有待增强。在迷宫和路径追踪上效果好,不代表在所有需要拓扑推理的场景中都能保持同样的表现。
这三个局限指向同一个方向:这是一个 v1 版本,思路对了,但离开箱即用还有距离。
与竞品的对比:不同的技术路线
当前多模态推理领域,各家走的路线不太一样。
OpenAI 的 GPT 系列和 Google 的 Gemini 系列,主要靠堆模型规模和训练数据来提升多模态能力,空间推理更多依赖模型的隐式学习。Anthropic 的 Claude 系列在文本推理上很强,但多模态能力一直不是其主打方向。
DeepSeek 这次走了一条不同的路:不是让模型"更聪明地猜",而是给模型一个新的思考工具。坐标和边界框就像是给模型的思维链装上了"手指",让它能指着图说话。
这个思路的优势在于,它是一种可组合的能力增强。视觉原语思考不需要替换现有模型,而是可以作为一个能力模块叠加上去。论文的实验也表明,在不需要空间推理的任务上,模型的表现不会因为引入视觉原语而下降。
劣势也很明显:它目前只解决了空间推理这一个维度的问题。多模态理解还涉及时序理解、因果推理、常识推理等多个维度,视觉原语思考在这些方面没有特别的加成。
开源生态:代码已可用
论文对应的代码仓库已在 GitHub 上开源:deepseek-ai/Thinking-with-Visual-Primitives。
从仓库结构来看,包含了模型权重、训练代码、评测脚本和基准数据集。对于想要复现论文结果或在此基础上做进一步研究的团队来说,这是一个完整的起点。
DeepSeek 在开源策略上一直比较激进,从 DeepSeek-V2 到 R1 再到现在的视觉原语思考,基本都是论文和代码同步放出。这种做法对学术社区和开发者社区都很友好,也是 DeepSeek 能在短时间内积累大量社区关注的重要原因。
对于想要在自己的多模态应用中集成空间推理能力的开发者,这个仓库值得关注。尤其是做工业视觉、文档理解、地图导航等方向的团队,视觉原语思考可能是一个值得尝试的技术方案。通过 OpenAI Hub 等 API 聚合平台,开发者也可以方便地对比 DeepSeek 与其他主流模型在具体任务上的表现差异,找到最适合自己场景的方案。
一句话总结
视觉原语思考的核心贡献,是证明了"让模型在推理过程中保持对图像空间的显式引用"这条路是走得通的,而且在特定任务上效果显著。它不是一个全面超越所有模型的万能方案,但它指出了一个被忽视的方向:多模态推理不应该丢掉空间信息。
接下来要看的是,这个框架能不能从"需要手动触发"进化到"自主启用",能不能从迷宫和路径追踪泛化到更多拓扑推理场景,以及分辨率瓶颈能不能随着视觉编码器的进步而缓解。
这些问题的答案,可能决定了视觉原语思考是停留在一篇漂亮的论文,还是真正改变多模态 AI 的工作方式。
参考来源
- DeepSeek发布「视觉原语思考」框架讨论帖 — Linux.do 社区对论文的技术讨论
- deepseek-ai/Thinking-with-Visual-Primitives — 论文配套开源代码仓库
