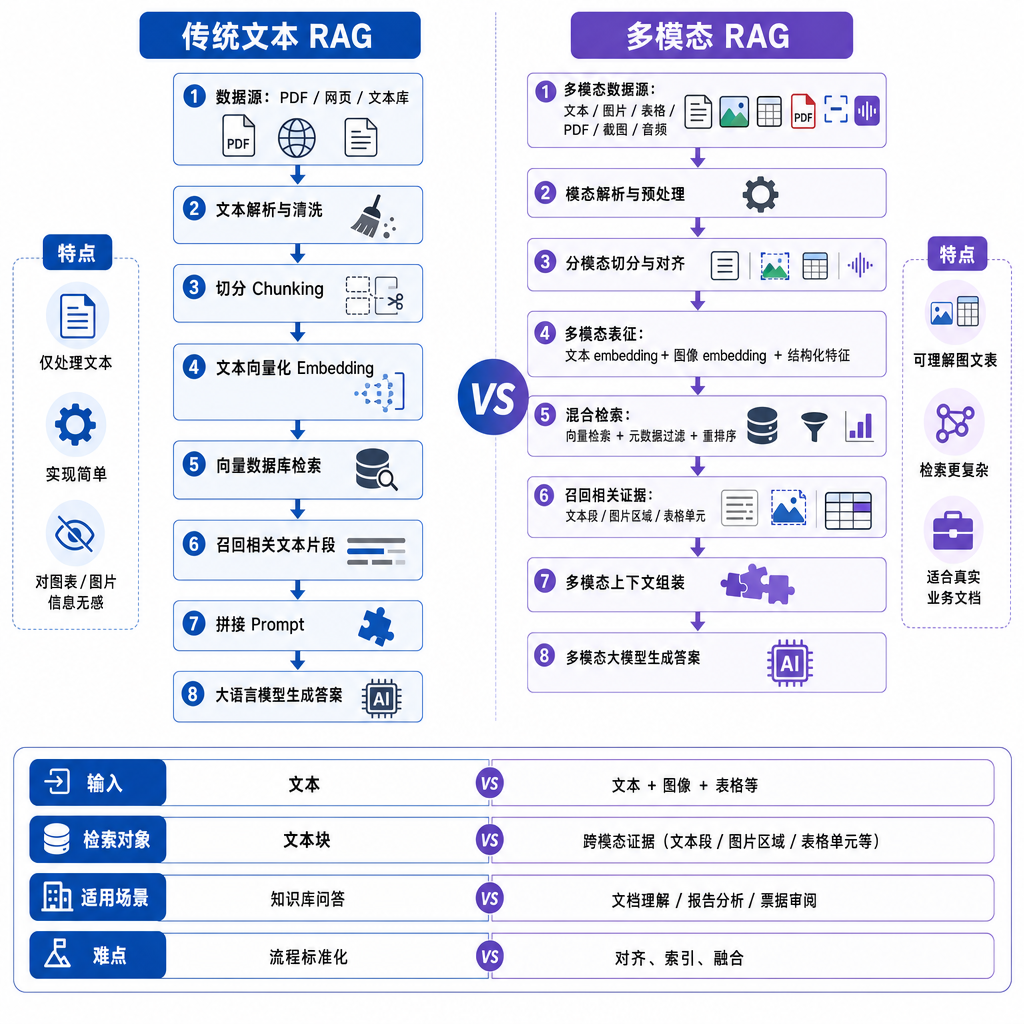
文本 RAG 已经被做烂了,但多模态 RAG 一直是半成品
五一假期刚过,linux.do 上冒出来一个开源项目 Multimodal-RAG,作者 liangdabiao——之前做过电商爆款复刻流水线和拼豆 AI,属于社区里比较高产的那一批。这次的新东西技术栈说起来不复杂:多模态 Embedding + Zilliz 向量数据库 + Qwen 视觉理解,但凑在一起解决的是一个困扰 RAG 领域两年多的老问题——怎么让检索增强生成真正"看见"图片。
过去大家做的所谓"多模态 RAG",十个里有八个是伪多模态:PDF 进来先跑 OCR,图表用 caption 模型生成一段文字描述,然后一股脑塞回文本索引。这套流程对着纯文字文档没问题,一碰到产品手册里的爆炸图、财报里的柱状图、病历里的影像资料,检索质量立刻崩盘——因为图里的信息在转文本那一步就损失了七八成。
这个项目到底做了什么
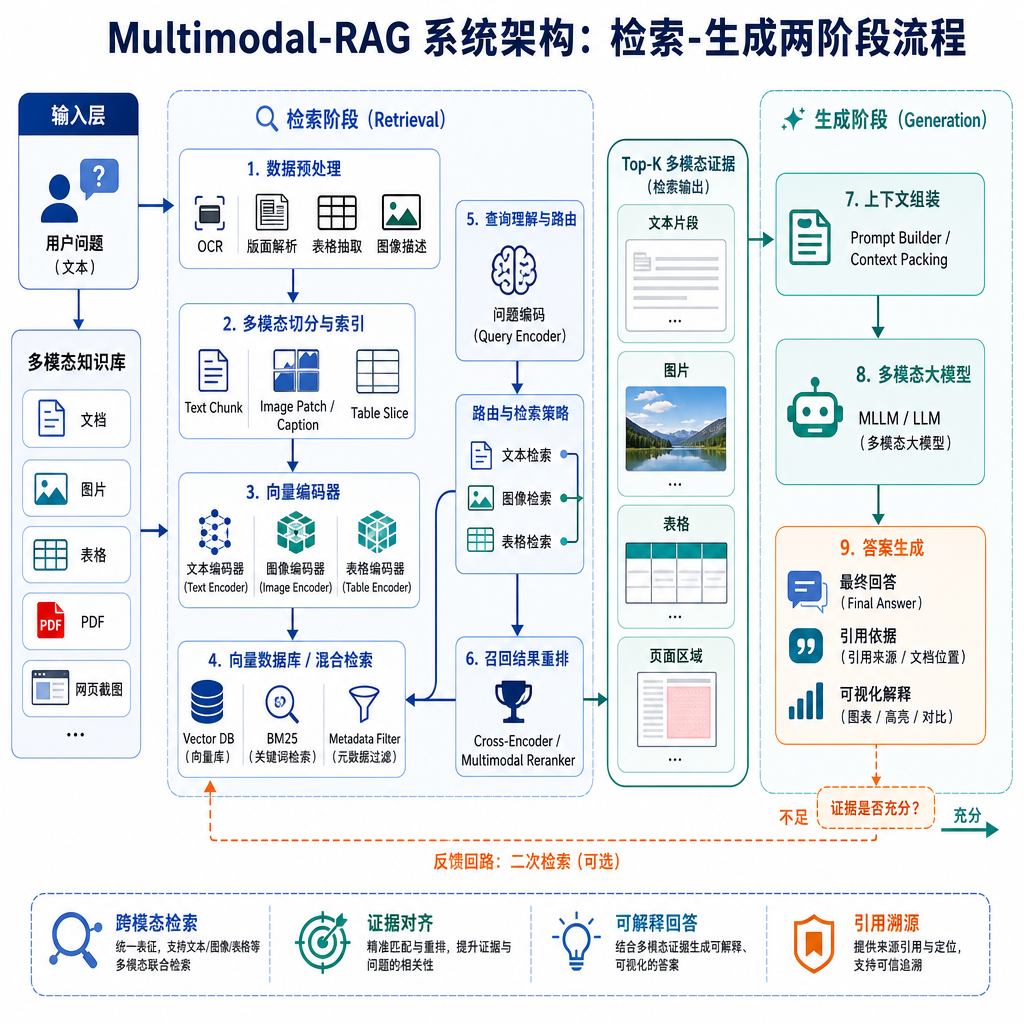
翻了下仓库,它的核心思路是把图像和文本放到同一个向量空间里去检索,而不是分两路做。作者用了 Cohere 的多模态 Embedding 模型做向量化——这个模型的特点是图片和文字编码出来的向量天然对齐,你用一段"红色连衣裙显瘦款"的文字描述去搜,能直接命中图片库里对应的商品图,反之亦然。
向量库选 Zilliz 也在意料之中。Milvus/Zilliz 这两年在多模态检索场景几乎成了默认选项,原因很现实:它对稀疏向量、稠密向量、标量过滤的混合检索支持得比较完整,HNSW 索引在千万级图文数据上的召回延迟能压到毫秒级。对比一下,Chroma 轻是轻,但真要往生产环境堆,索引切分和流式写入就开始捉襟见肘;Qdrant 性能不差,不过国内社区生态和 Zilliz 比还是弱一截。
生成侧作者挂的是 Qwen 的视觉理解模型(Qwen-VL 系列)。这一步是整条链路里最关键的设计:检索出来的不是文本片段,而是原始图片+上下文文本,直接喂给 VLM 让它看图说话。这意味着系统不用依赖预生成的 caption,对图表、界面截图、医学影像这类"一图胜千言"的场景友好得多。
技术细节里的几个聪明决定
仔细看代码和文档,有几个处理方式值得单独拎出来说:
第一,混合检索策略。系统没有走纯向量检索一条路,而是把多模态向量相似度和 BM25 文本召回做了融合排序。这个设计在 2025 年后已经算是高级 RAG 的标配——纯向量容易漏掉专有名词和精确匹配,BM25 又抓不住语义,两条腿走路鲁棒性强很多。
第二,文档切块保留版面信息。PDF 解析不是简单按页切,而是把图片、表格、正文段落作为独立的 chunk,同时保留它们在原文档的位置关系。检索时命中某张图,能把上下文的说明文字一起带出来。这比市面上很多 RAG 框架粗暴的 chunk_size=512, overlap=50 要讲究。
第三,Qwen-VL 承担了二次过滤的角色。检索阶段 Top-K 出来的结果,会让 VLM 再判断一次相关性——相当于把 Reranker 从 cross-encoder 换成了视觉语言模型。延迟是会高一点,但在图像为主的检索任务里,准确率提升明显,因为 VLM 能理解"这张图里的柱状图表达的是 Q3 而不是 Q2"这种文本 embedding 根本捕捉不到的细节。
跟现成方案比,它的位置在哪
现在市面上多模态 RAG 的方案大致分三派:
- LlamaIndex/LangChain 的多模态模块:胶水写得好,但默认配置跑不出好效果,想用起来得自己调一堆参数
- ColPali 这类端到端方案:直接把 PDF 页面当图像编码,省去了解析环节,但对算力要求高,推理成本不低
- 云厂商的托管服务(比如某些国内大模型厂商的知识库):开箱即用,但数据隐私和定制化基本没得谈
这个开源项目的定位比较务实——你想自建、想调参、想换模型,它都给你留了口子。Embedding 模型可以从 Cohere 换成 JinaCLIP 或者 BGE-M3,VLM 可以从 Qwen-VL 换成其他兼容 OpenAI 格式的视觉模型,向量库理论上也能从 Zilliz 切到 Milvus 自建实例。
这里顺带说一句,因为整套系统调用的都是标准 OpenAI 兼容接口,直接对接 OpenAI Hub 这类聚合平台也没障碍——一个 Key 把 Qwen-VL、Cohere Embedding、甚至后续想换成 Claude 3.5 Sonnet 做生成都能覆盖,省掉挨个申请额度的麻烦。对于想快速跑通原型的开发者,这条路比自己一家家注册 API 省事得多。
诚实说一下局限
项目还不算成熟,有几个坑得提前讲清楚:
评测数据偏少。作者提供的 demo 主要跑电商和产品手册场景,在医学影像、工程图纸这种专业领域表现如何没有 benchmark 数据支撑。多模态 RAG 的效果对领域数据分布特别敏感,别直接拿来就用在核心业务上。
成本不低。多模态 Embedding 每千张图的费用、VLM 推理的 token 消耗,比纯文本 RAG 贵一个数量级。真要商用,得先算清楚单次查询的成本上限。
工程化还缺东西。增量索引、版本管理、缓存层这些生产环境必备的基建,目前仓库里都没有现成实现。想拿去做商业产品,还得自己补一段工程化的路。
值得关注的信号
退一步看,这个项目出现在这个时间点本身就挺说明问题——2026 年的 RAG 已经不是"能不能用"的问题,而是"多模态、Agentic、长上下文"三条线怎么打通。Naive RAG 那套单向 retrieve-read 流程在复杂任务面前早就不够看了,智能体 RAG、多模态 RAG、迭代式检索正在成为新的基线。
对独立开发者和中小团队来说,这种打包好核心能力的开源项目是最好的学习材料。代码量不大,核心逻辑两百来行就能看完,但把业界这两年摸索出来的最佳实践都串起来了。想入门多模态 RAG 的,比啃论文效率高得多。
项目还在迭代,作者在帖子里提到后续会加入更多 Embedding 模型的适配和 Agentic 检索模块。值得盯一段时间。
参考来源
- GitHub - liangdabiao/Multimodal-RAG —— 项目主仓库,包含完整源码和部署说明
- linux.do 开源推广帖 —— 作者在社区的首发介绍和讨论
- GitHub - liangdabiao/perler-beads-ai —— 同作者之前开源的拼豆 AI 项目,可参考其工程风格
- 如何从头开始构建一个多模态 RAG 系统 - 知乎 —— JinaCLIP + Milvus 搭建多模态检索的参考实现