Gemma 4 补上 MTP:推理速度直接翻倍

Google 为 4 月发布的 Gemma 4 开源模型家族补发了多 Token 预测(MTP)草稿模型,推理吞吐最高提升 2 倍以上。这也解答了一个月前社区的疑问:为什么 Gemma 4 的架构里藏着 MTP 却没启用。
Google 昨天(5 月 4 日)在开发者博客上放出了 Gemma 4 的配套更新:一组专门用于**多 Token 预测(Multi-Token Prediction, MTP)**的草稿模型(drafter),配合主模型做推测解码(speculative decoding),实测在长上下文和代码生成场景下,推理吞吐能拉到原来的 2 倍甚至更高。
这件事的有趣之处不在于 MTP 本身——DeepSeek-V3 早在 2024 年底就把 MTP 玩明白了,Meta 也在 Llama 4 里用过类似思路。真正值得说的是时间线:Gemma 4 在 4 月 2 日发布时,Hugging Face 上眼尖的开发者就发现,模型权重里其实留着 MTP 相关的张量,只是被禁用了。Reddit 上那条讨论帖最后逼出了一位 Google 员工的回应,原话大意是「MTP 确实在,但为了兼容性和广泛可用性被故意移除了」。
一个月后,Google 把拆掉的零件又装了回来——只不过这次是以独立 drafter 的形式,不动主模型权重。这个选择其实比「直接开启原生 MTP」更聪明,后面会讲为什么。
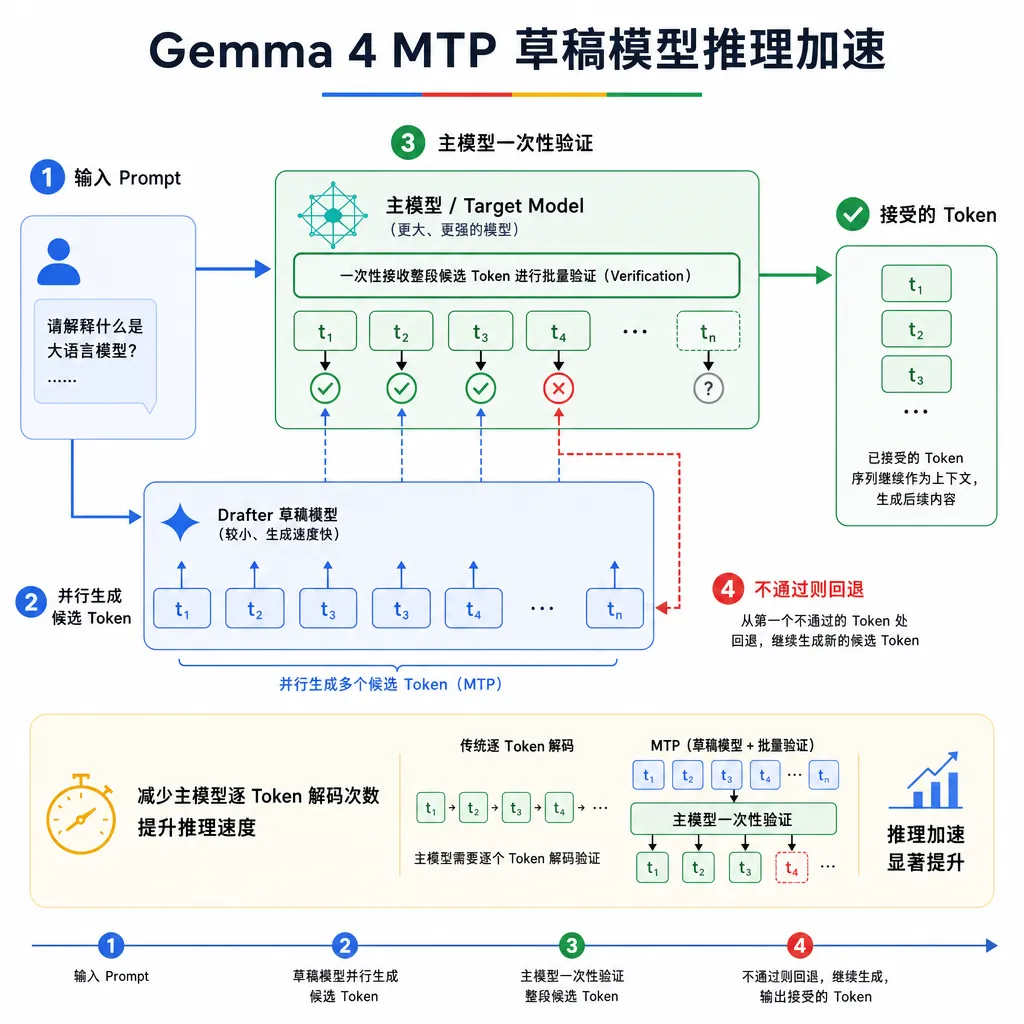
MTP 到底在加速什么
先把原理讲清楚,不然后面的数字没有坐标系。
标准的自回归生成是一个 token 一个 token 蹦,每次前向传播只吐一个字。瓶颈不在算力,在内存带宽——每生成一个 token,都要把几十 GB 的权重从 HBM 搬一遍到 SRAM。31B 模型哪怕你塞满 H100,大部分时间 GPU 也在等数据。
推测解码的思路是:让一个小而快的「草稿模型」先连猜 N 个 token,再让大模型一次性并行验证这 N 个猜测。如果猜对了 k 个,相当于一次前向传播产出 k+1 个 token。验证是并行的,对大模型来说成本几乎等于生成 1 个 token。
传统做法是拿一个独立的小模型(比如 Gemma 2B)当 drafter,问题是小模型和大模型的分布对不齐,命中率经常只有 50% 左右,加速比打折严重。
MTP 的玩法不一样:它让主模型在训练时就同时预测接下来 2~4 个位置的 token,每个未来位置共享主干表示,只加一个轻量的预测头。这种 drafter 和主模型共享了几乎所有语义理解能力,猜测命中率能到 80% 以上,且 drafter 本身极轻(通常只有几百 M 参数的开销)。
Google 这次发布的 drafter 就是这类结构。根据博客里给出的数据,在 Gemma 4 31B 主模型上挂载 drafter 后:
- 代码补全场景:端到端延迟降低约 2.1x
- 长文档摘要:吞吐提升约 1.8x
- 对话类任务:加速在 1.5~1.7x 之间
- 数学推理(链式思维):加速最明显,接近 2.3x
最后一条值得注意。CoT 推理里大量存在「格式化 token」(比如 Step 1:、Therefore、数字、公式符号),这些结构化内容预测命中率极高,MTP 的收益被放大。这也解释了为什么 Gemma 4 主打推理和 Agent 工作流——MTP 和这两个场景是天作之合。
为什么 4 月发布时要先拆掉
回到那个悬案。Google 当时拆掉 MTP 的理由是「兼容性和广泛可用性」,这话听着像公关辞令,但技术上其实说得通。
原生 MTP 架构的主模型,权重里带着多个预测头和相应的训练目标。这意味着:
- 推理框架得改。vLLM、SGLang、llama.cpp、MLX、Ollama 这些主流推理引擎,默认按单 token 预测组织 KV cache 和采样循环,原生 MTP 要求改调度逻辑。Gemma 主打「笔记本、手机都能跑」,如果发布就带 MTP,意味着一半的目标用户当天就用不起来。
- 量化工具链会炸。GGUF、AWQ、GPTQ 这些社区量化方案对标准 Transformer 结构做了大量优化,突然冒出多个预测头会踩各种边界情况。
- 微调生态不知道怎么处理。LoRA、全参微调的 recipe 都是针对单 token loss 设计的。
所以 Google 的节奏是:先发一个标准结构的 Gemma 4,让生态跑起来;一个月后再发独立 drafter,谁想要加速谁自己挂。drafter 和主模型解耦,推理框架只需要支持通用的推测解码接口(vLLM 早就支持),不需要为 Gemma 4 做特殊适配。
这个拆分其实是有代价的——独立 drafter 的命中率比真正的原生 MTP 要低一截(Google 内部数据据说能到 90%+,公开 drafter 大约 78%)。但换来了零迁移成本的部署体验。对开源生态来说,这是个更负责任的选择。
drafter 的规格和使用方式
Google 这次一共放出了两个 drafter:
- Gemma 4 Drafter-S:约 300M 参数,配 Gemma 4 E2B / E4B 使用
- Gemma 4 Drafter-L:约 1.2B 参数,配 Gemma 4 31B / 26B A4B 使用
drafter 在训练时用主模型的隐状态蒸馏(hidden-state distillation)而非单纯的 logits 蒸馏,这也是命中率能压到接近原生 MTP 的关键。Google 在博客里提到,他们用主模型的倒数第二层 hidden state 作为 drafter 的额外监督信号,让 drafter 不仅学会「下一个词是什么」,还学会「主模型现在在想什么」。
部署层面,vLLM 0.7+ 和 SGLang 最新版都已经原生支持,启动参数里加上 --speculative-model google/gemma-4-drafter-l --num-speculative-tokens 4 就行,不需要改业务代码。
llama.cpp 的支持还在合并中,社区 PR 已经有人提交,预计一周内能用。
放到行业坐标系里看
把 Gemma 4 + MTP drafter 和其他开源模型并排放:
| 模型 | 参数量 | MTP 支持 | 典型加速比 | | --- | --- | --- | --- | | DeepSeek-V3 | 671B (37B 激活) | 原生 MTP | ~1.8x | | Llama 4 70B | 70B | 独立 drafter | ~1.6x | | Qwen3 32B | 32B | 独立 drafter | ~1.5x | | Gemma 4 31B | 31B | 独立 drafter | ~2.0x |
Gemma 4 的加速比在同规模开源模型里确实能排到前列,这得益于 drafter 用了 hidden-state 蒸馏,以及 Gemma 4 本身在推理类任务上的结构化输出特性。
但也别神化。MTP 的加速效果高度依赖任务类型和批大小。batch size 上去之后(比如服务端并发请求多),GPU 已经被算力打满,内存带宽不再是瓶颈,MTP 的加速比会快速衰减到 1.2x 左右。这是推测解码的数学宿命,和具体实现无关。
所以 MTP 的真正受益者是:
- 端侧/边缘部署:batch size=1,带宽瓶颈最严重,加速最明显
- 低并发的企业内部应用:同理
- 需要低首 token 延迟的交互式场景:比如代码补全、对话
对高并发 API 服务来说,MTP 更多是「延迟优化」而非「吞吐优化」,部署时得想清楚自己要的是哪个。
一个被忽略的信号
往后退一步看,Google 这次发 drafter 而不是重新发一版带原生 MTP 的 Gemma 4,传递了一个信号:开源模型的发布策略正在和闭源分化。
闭源模型(GPT-5、Claude、Gemini)不需要考虑社区工具链,想用什么架构就用什么架构,推理基础设施自己端到端掌控。开源模型则必须向下兼容一整套社区生态,任何「先进特性」都得先评估生态渗透成本。DeepSeek 敢直接上原生 MTP,是因为它主要面向服务器部署,而 Gemma 的用户画像里有大量笔记本和手机玩家,包袱更重。
Google 用「先标准版本,再补 drafter」的节奏解决这个矛盾,是一种挺成熟的产品思路。后面估计会成为开源模型发布的新范式——主模型先走量,高级特性做成可插拔组件。
对国内开发者来说,如果你需要在应用里用 Gemma 4 又嫌本地部署麻烦,OpenAI Hub 已经接入了 Gemma 4 全系列,用 OpenAI 兼容格式直接调就行,推测解码的加速在服务端默认开启,不需要自己折腾 drafter 部署。
下一个值得关注的时间点是 Google I/O(本月中旬),据说还会有 Gemma 4 的视觉版本发布。如果视觉版本也带 MTP drafter,那多模态端侧推理的性价比曲线会被彻底重画一次。
参考来源
- Reddit r/LocalLLaMA:关于 Gemma 4 藏着 MTP 的社区讨论帖 — Google 员工确认 MTP 被「故意移除」的原始出处
- Hugging Face:Gemma 4 模型权重与 drafter 仓库 — 主模型和新发布的 Drafter-S / Drafter-L 下载入口
