智谱把 GLM-5V-Turbo 的底牌摊开了。4 月 30 日前后流出的那篇 arXiv 论文《GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents》,基本把外界对这款模型的好奇心堵上了一半——剩下那一半要留给跑分和真实场景。
这不是一次常规的多模态升级。智谱这次的切入点很明确:别再把 VLM 当成在文本模型外面套一层视觉插件,而是从预训练阶段就让视觉、代码、动作执行共用一套推理骨架。说得更直白一点,过去我们见过的大多数多模态模型,是在一个擅长写字的大脑上接了副眼镜;GLM-5V-Turbo 想做的,是让这个大脑从出生那天起就带着眼睛。
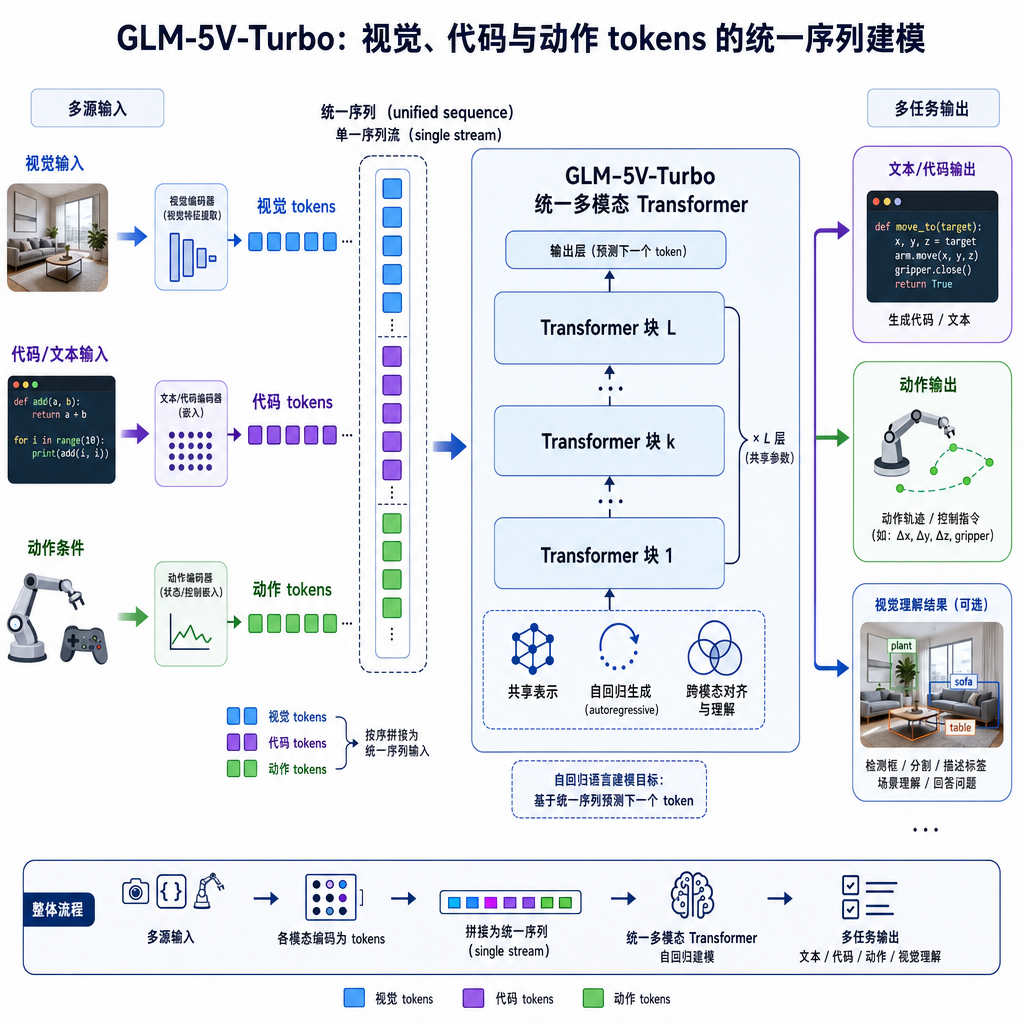
为什么要做「原生」
现在行业里主流的多模态 Coding 思路,大体分两派。
一派是外挂派:文本模型训好之后,再通过视觉适配器把图像特征映射进文本空间。好处是改造成本低,坏处是视觉信息到了推理层已经被压缩过一轮,面对「看着这张设计稿写出能跑的代码」「盯着 K 线图输出一段回测脚本」这种细活,细节经常掉链子。
另一派是端到端派:从预训练就把图像、视频、文本、代码混在一起喂,让模型在 token 层面就习惯跨模态。智谱走的是这条更贵的路。论文里反复强调的 native 一词,翻译过来就是——视觉 token 不是客人,是家里人。
这种选择的代价不小。多模态预训练的数据配比、训练稳定性、跨模态干扰,每一个都是深坑。好处是上层应用能拿到一个真正懂「看」的 Coding 大脑,而不是一个会复读图像描述的文本模型。
技术路线:一锅端训多模态
外界给这篇论文起了个很贴切的外号——「一锅端训多模态」。从现有披露信息来看,GLM-5V-Turbo 的做法有几个关键点值得说道。
统一的多模态 tokenization。图片、视频帧、代码、文本在输入层就被拉平成同一种序列,交给同一个 Transformer 去消化。这让模型在生成代码时可以直接「指着」图里的某个按钮、某根 K 线说事,而不是先把图描述一遍再写代码——后者是 GPT-4V 早期版本经常翻车的地方。
Agent 能力前置到预训练。以往 Agent 能力基本靠后训练阶段的 SFT 和 RL 来补,GLM-5V-Turbo 把工具调用、长程规划、动作执行这些范式放进了预训练语料。这意味着模型不是「被教会」调工具的,它在预训练里就见过大量调用链和规划轨迹。这对长任务的稳定性影响非常大——做过 Agent 的人都知道,靠后训练强行拗出来的规划能力,链路一长就散架。
视觉不以牺牲文本为代价。这是论文里一个挺值得称道的点。多模态训练最容易翻车的就是文本能力被拖下水,尤其是代码和数学推理。GLM-5V-Turbo 声称纯文本编程与推理能力和同代纯文本模型保持同等水准。如果这个结论经得起社区复现,那它基本解决了多模态模型落地 Coding 场景的一个老大难问题——过去你很难说服一个重度 Claude Code 用户切换到一个多模态模型,因为代价通常是纯文本任务退步一截。
尺寸与性能:小模型打大模型
从透露的口径看,GLM-5V-Turbo 在多模态 Coding、Agent 等核心基准上「以更小尺寸取得领先表现」。具体参数量论文没细说,但 Turbo 这个后缀本身就在暗示这不是一个旗舰级别的庞然大物,而是走性价比路线的中等尺寸模型。
这个定位挺聪明。旗舰模型的多模态能力现在基本是 GPT-5、Claude 4.5、Gemini 3 三家在卷,开源或半开源阵营硬刚参数量没太大胜算。但中等尺寸的原生多模态 Coding 模型,目前空位明显——DeepSeek-VL 偏通用,Qwen2.5-VL 更像是视觉理解型,真正把 Coding 和 Agent 当作一等公民的不多。
更现实的一面是,中等尺寸模型才适合塞进 IDE、塞进浏览器插件、塞进桌面 Agent 这种延迟敏感的场景。旗舰模型再强,让它每隔几秒看一次屏幕,成本和延迟都是灾难。
OpenClaw 龙虾与 Claude Code 适配
论文之外,一个很值得关注的落地信号是——GLM-5V-Turbo 深度适配了 Claude Code 以及智谱自家的 OpenClaw 龙虾场景。
OpenClaw 是智谱这两个月在推的桌面 Agent 产品,这次接上 GLM-5V-Turbo 之后,它第一次具备了「真正的视觉能力」——不是读 DOM 不是读无障碍树,是真的在看屏幕上显示的像素。对普通用户来说区别不大,但对开发者来说这是两种完全不同的技术范式:读 DOM 依赖网页结构,屏幕不规整就崩;看像素理论上可以操作任何应用,包括那些根本没开放接口的桌面软件。
适配 Claude Code 的操作也很直接——承认 Anthropic 定义的那套 Coding Agent 交互范式已经事实上成了标准,与其另起炉灶不如兼容。对开发者的信号是:你可以用 Claude Code 的使用习惯,把后端模型换成 GLM-5V-Turbo,然后获得处理截图、设计稿、图表的原生能力。
对开发者意味着什么
抛开宣传话术,GLM-5V-Turbo 如果真能兑现论文里的指标,对几类开发者是实打实的利好:
- 前端和全栈:把 Figma 设计稿或者竞品截图扔进去直接出代码,这个需求呼吁了很多年,GPT-4V 和 Claude 做得都还不够稳。一个把视觉当母语的模型,理论上能把「所见即所得」往前推一大步。
- 做量化和数据分析的:K 线图、看板截图直接生成回测或分析脚本,省掉一轮人肉描述。
- 做桌面 / 浏览器 Agent 的:过去这条路线一直被视觉模型的精度和延迟卡着,中等尺寸的原生多模态模型是比较现实的解。
- 做 RPA 和测试自动化的:看屏幕写脚本,比读 DOM 鲁棒性高一个量级。
当然,话不能说满。论文披露的基准成绩和真实场景之间永远有一段距离,尤其是 Agent 这种长链路任务,benchmark 跑得漂亮不等于生产环境不翻车。社区接下来几周的复现和实测,才是真正的考场。
目前 GLM-5V-Turbo 已经通过智谱 MaaS 平台开放接入。习惯了 OpenAI 格式的开发者也不用折腾适配,OpenAI Hub 这类聚合平台一般会在新模型上线后很快跟进,一个 Key 就能在 GLM、Claude、Gemini 之间横跳对比,做模型选型的时候省事不少。
一点判断
智谱这两年的节奏越来越清晰——不在参数量上和头部硬碰硬,而是在「原生多模态 + Coding + Agent」这个交叉点上下重注。GLM-5V-Turbo 是这个策略的一次明确表达:与其做一个什么都会一点的通用 VLM,不如做一个把视觉、代码、动作焊死在一起的基座。
这条路线对不对,要看一年之后 AI 原生应用长成什么样。但如果你相信未来的 Agent 必须能看屏幕、会写代码、能按长程计划一步步执行,那 GLM-5V-Turbo 至少是国内团队给出的一个严肃答案。
参考来源
- GLM-5V-Turbo 发布:多模态 Coding 基座模型 - 知乎专栏:智谱官方对 GLM-5V-Turbo 定位与能力的一手说明,关于「原生多模态 Coding 基座」的表述出自这里。