OracleProto 开源:给大模型的预测能力搭一把严苛的尺子
问大模型一句「下周英伟达财报会不会超预期」,或者「这场冲突三个月后会怎么收场」,你多半会收到一段绕来绕去的外交辞令。不是模型蠢,是没人认真教过它怎么预测,更没人认真评过它预测得好不好。
这周在 linux.do 冒头的开源项目 OracleProto,想把这件事办了。它不是又一个榜单,而是一套专门针对「预测」这个任务的可复现评测框架,核心思路只有一句话:卡死模型的知识截止时间,逼它做真正的样本外预测。

现有的预测评测,要么假,要么脏
要理解 OracleProto 的价值,得先看看评测预测能力这件事到底难在哪。
业内现在主要两种做法。一种叫实时基准,找一堆还没发生的事情让模型押注,比如下个月的 CPI 数据、某场选举的结果。优点是数据绝对干净,模型不可能提前知道答案。问题是题目有保质期,事件一落地,这道题就作废了,整个基准很快失去统计意义。你今天跑的结果没法跟三个月后新模型的结果直接比,因为题不一样了。
另一种叫历史回放,拿过去已经发生的事件当考题。这种做法最大的便利是可以反复跑、横向比,但代价是致命的:这些事件大概率已经躺在模型的训练语料里了。所谓让模型「预测」2023 年某家公司会不会破产,它其实是在回忆,不是在推演。这不叫回测,叫开卷考试。
而 prompt 里写一句「请假装你不知道 2024 年之后的事情」,对于一个把整个互联网嚼过一遍的模型来说,基本约等于没说。知识边界是刻在权重里的,提示词锁不住它。
这就是 OracleProto 作者拿出来反复讲的那个痛点:预测任务的评测,核心变量是时间,但所有现有方法都在时间这个维度上漏水。
把时间当成硬约束,而不是建议
OracleProto 给出的解法很朴素,甚至可以说有点笨,但它是目前能看到的最严格的一种。
整套框架在出题阶段做了三层时间隔离:
第一层,锚定模型的知识截止日期。每个模型有自己的 cutoff,GPT-4 系列、Claude 3.x、Gemini、DeepSeek、Qwen 各不相同,框架会针对每个模型单独筛选样本池,只保留那些发生在它知识截止之后、但已经在现实里落地的事件。这一步就把「开卷」的可能性堵了大半。
第二层,时间遮蔽(Time Masking)。在 prompt 构造时,把事件里任何可能暴露「这件事已经发生了」的时间锚点统统抹掉或改写,比如具体日期、「上周」「昨天」这种相对时间词、以及事后才会出现的结果性表述。目的是让模型从语境里也嗅不出时间线索。
第三层,工具时间锁。如果模型带搜索或浏览工具,框架会把工具能访问的时间窗口硬性卡死在知识截止日之前。换句话说,即使你让它上网查,它能查到的也只是它本来就应该知道的那个世界。这一层对评估带联网能力的 Agent 式模型特别关键。
最后还有一道内容级防泄漏检测兜底。如果模型在回答里意外流露出「我已经知道这件事结果了」的信号(比如直接说出结局、引用后验信息),会被标记并剔除。作者给出的数字是,经过这套组合拳,泄露率能压到 1% 左右。这个数字在评测领域算是很硬的。
做个类比,这跟量化交易里的严格样本外回测是一个意思。你不能拿 2020 年的数据训模型、然后用 2019 年的数据回测说自己策略有效。OracleProto 就是把这套金融工程的严谨性,搬到了 LLM 评测里。
9 个模型实测:贵的不等于准的
作者用 80 道题跑了 9 个主流 LLM,覆盖了 GPT、Claude、Gemini、DeepSeek、Qwen 等头部玩家。两个发现挺刺眼。
第一,准确率的差距其实没那么大。 最好和最差之间相差 10.1 个百分点。这说明在真正的样本外预测任务上,头部模型之间并没有拉开代差,大家都在一个比较接近的水位上挣扎。这其实印证了一个判断:预测不是某个模型的专属能力,而是所有 LLM 都没被专项训练过的弱项。
第二,成本差距大到离谱。 做出一次正确预测的调用成本,最贵的模型是最便宜模型的 82 倍。这个倍数不是 token 单价差距那么简单,而是「准确率 × 单价 × 调用次数」综合下来的结果。有些模型虽然 token 便宜,但需要更长的推理链才能答对;有些模型虽然贵,但一次就给出靠谱答案。OracleProto 把这个维度单独拎出来做了个「成本效益」指标,对工程落地非常友好。
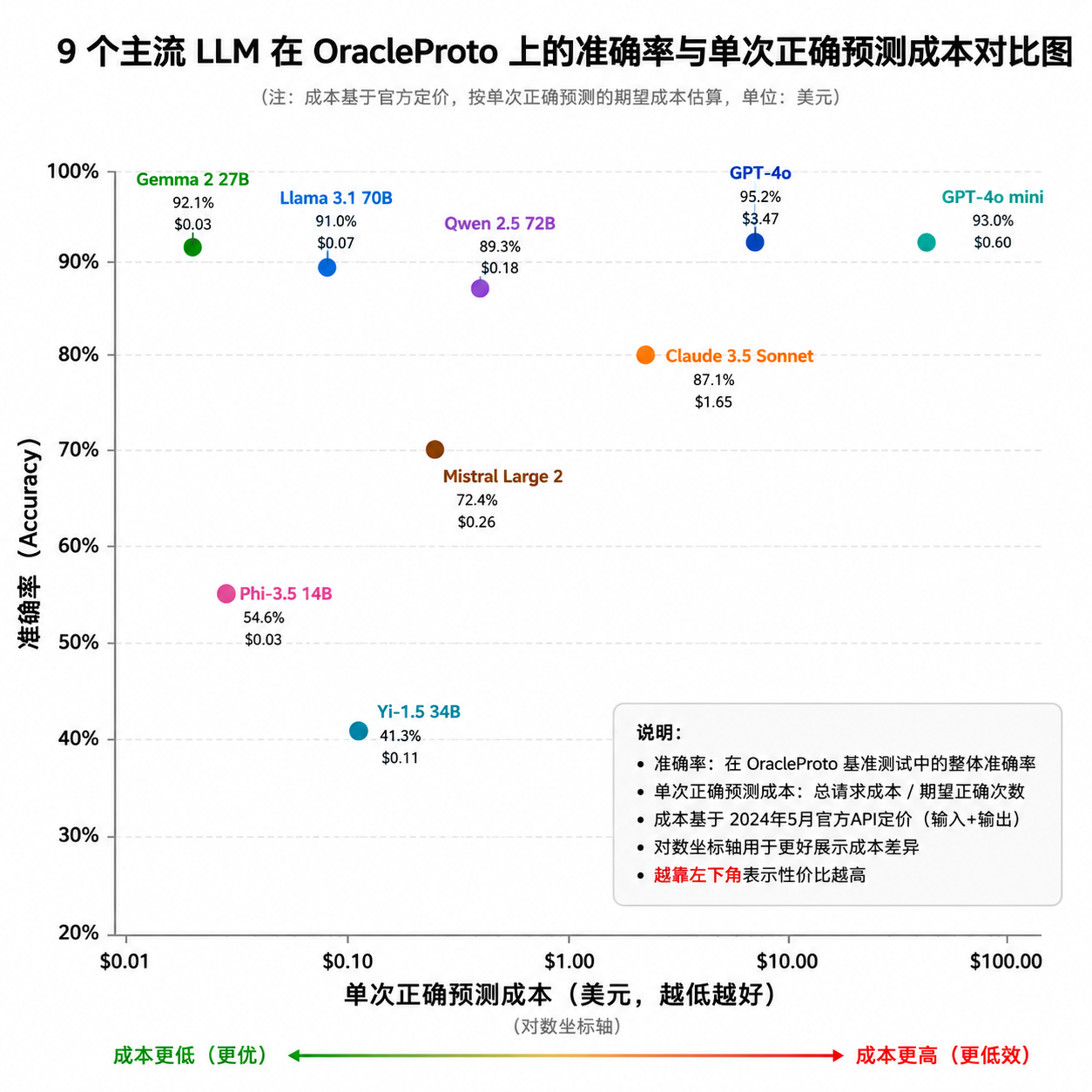
对开发者的启示是,选模型做预测类任务时,别只看榜单排名,算算单位成本的正确率。尤其是那种需要跑批量预测的业务场景,比如舆情预警、金融信号、供应链风险评估,82 倍的成本差距直接决定了产品能不能规模化。
如果你想自己复现这套测试,通过 OpenAI Hub 这类聚合平台用一个 Key 同时调 GPT、Claude、Gemini、DeepSeek 会方便不少,省得在各家 SDK 之间切来切去,跑对比实验的时候尤其顺手。
真正值钱的是「过期预测」能被回收
准确率和成本那些数字其实是表层的,OracleProto 框架里最让人眼前一亮的是另一件事:它让那些已经「过期」的预测数据集重新变得有价值。
这事儿得掰开讲。过去十几年,学术界和业界其实积累了大量预测类数据集:Good Judgment Project 的地缘政治预测、各种经济预测竞赛的题目、Metaculus 上成千上万道已解锁的题目。这些数据在它们发生的当下是黄金,但一旦答案揭晓,对新模型来说就变成了「训练集里可能已经存在的答案」,评测价值归零。
OracleProto 的出题逻辑反过来把这些「废料」盘活了。只要一个历史事件发生的时间晚于目标模型的知识截止日,它就可以被重新包装成一道合法的预测题。这意味着:
- 每出一代新模型,就有一大批「过期」数据集因为知识截止日期的推进而重新可用
- 评测集可以按模型动态生成,不存在「一套题目用到废」的问题
- 这些样本不仅能用来评测,还能作为**监督微调(SFT)或强化学习(RLHF/GRPO)**的训练信号,专门提升模型的预测能力
第三点是作者野心最大的地方。现在的大模型在预测任务上表现普遍一般,很大程度是因为训练数据里根本没有「带时间戳、带结果、带推理链」的结构化预测样本。OracleProto 给出了一条把历史数据批量转化为这类训练语料的工业化路径。换句话说,预测能力可以从偶然涌现变成可以专项训练的能力,这才是这套框架长期的想象空间。
框架本身:工程化程度超预期
翻了下仓库,工程质量比想象的扎实。核心模块清晰地分成几块:
- 样本采集与清洗:从公开事件数据源抓取,按时间、领域、可验证性打标
- 时间掩码器:NER + 规则 + LLM 校验三层过滤,处理显性和隐性时间信号
- 评测调度:支持主流闭源模型 API 和本地开源模型(通过 vLLM 等推理框架)
- 泄漏检测:独立的后处理模块,可插拔
- 排行榜:项目方还搭了一个在线 leaderboard 网站,方便社区提交新模型结果
Hugging Face 上同步放了数据集,arXiv 上挂了论文,整套东西是奔着「可复现、可扩展、可协作」去的,不是一次性的 demo。
对想做 LLM 评测或者预测类应用的团队来说,这套东西有几种用法:
- 选型评估:直接跑自己关心的模型,看它在预测任务上的真实水位和成本结构
- 领域适配:替换自己行业的事件数据(金融、医疗、供应链、地缘),按同样的时间隔离逻辑生成专属评测集
- 训练语料生成:用框架的出题和标注能力,批量产出 SFT/RL 样本
- 防泄漏校验:把它的泄漏检测模块嫁接到自己已有的评测流程里
一些不那么乐观的观察
当然这事儿也有局限。
知识截止日期本身是个模糊概念。各家模型官方声明的 cutoff 不一定是权重里真实的 cutoff,有些模型通过持续的 RLHF 和数据混入,其实知道得比自己承认的更多。OracleProto 的第一道防线是建立在官方声明之上的,这层假设如果被突破,后续的评测就会被污染。作者在论文里也承认了这点,并用内容级泄漏检测做兜底,但这不是万能的。
另外,80 道题的样本规模,对于稳定区分头部模型来说偏小。10.1 个百分点的准确率差距,在这个样本量下的置信区间还不够窄。希望后续能看到扩展到几百上千题的版本,以及更细的领域切分(经济、政治、科技、体育分别看)。
还有一个更哲学的问题:预测能力到底该不该成为 LLM 的核心指标之一。这个行业已经有 MMLU、GSM8K、HumanEval、GPQA 一大堆榜了,多一个预测 benchmark 是让评测体系更完整,还是让社区的打榜内耗进一步加剧,目前还不好说。但至少 OracleProto 指出了一个现有评测完全没覆盖的盲区,这个贡献是实打实的。
写在最后
大模型行业这两年在推理、代码、长上下文这些方向上卷得飞起,但「面对未来的不确定性给出有依据的判断」这件事一直被模糊处理。原因之一是没人知道怎么严肃地评它。OracleProto 不是终极答案,但它把问题的定义说清楚了:预测评测的核心是时间纪律,而时间纪律必须靠工程手段强制执行,不能指望提示词。
把一件长期被当成玄学的事情拖进可复现的科学范式里,这本身就值一个 star。
参考来源
- OracleProto 开源自荐原帖(linux.do) - 作者在社区发布的项目介绍与设计思路,包含框架核心理念、实验结果与对现有评测方法的批判