OpenAI 拉上六巨头发布 MRC 协议:给万卡集群修一条新高速
OpenAI 今天在官方博客上放出一个不算高调但分量很重的消息:联合 AMD、博通、英特尔、微软、英伟达,共同发布了一个叫 MRC(Multi-Path Reliable Connection,多径可靠连接)的新协议,专门解决大型 GPU 训练集群里网络层的硬伤。协议通过 OCP(开放计算项目)对外开放,任何厂商都能采用。
这份名单本身就很有意思。AMD 和英伟达坐到同一张桌子上,英特尔也在,再加上博通这个做交换机芯片的——几乎把今天数据中心网络的主要玩家凑齐了。由 OpenAI 牵头,更像是甲方下场制定标准。
GPU 吃饱了,但网络没跟上
训练 frontier 模型这几年最头疼的事,早就不是 GPU 算力不够。H100、MI300X、B200 堆上去之后,真正卡脖子的是 GPU 之间那张网。
数字很残酷。一个万卡集群做一轮 AllReduce,理论上所有卡都在算,实际上相当比例的时间都在等通信。梯度同步、参数广播、流水线切换,每一步都要走网络。集群规模从千卡扩到万卡再到十万卡,网络利用率不是线性下降,是指数下降。
传统方案的瓶颈在哪?核心是 RDMA 的 RC(Reliable Connection)模式。InfiniBand 和 RoCE 都基于它,优点是零拷贝、低延迟、对 CPU 几乎无开销,所以集合通信库(NCCL、RCCL)都建在上面。但 RC 有一个古老的假设:一对 QP(Queue Pair)走一条路径。
这在小规模下没问题,到了万卡就是灾难:
- 链路抖动即中断。一条物理链路抖动一下,整个 QP 就进入 error 状态,要么 go-back-N 重传,要么直接断连。万卡集群里,链路故障不是"会不会"的问题,是"每小时几次"的问题。
- ECMP 哈希不均。交换机用五元组哈希做负载均衡,理论上把流量打散,实际上大流(elephant flow)一多就出现热点和 incast,某几条链路跑满、另几条闲着。
- 故障域过大。一个节点的网卡出问题,可能让整个 job 卡住几分钟甚至直接挂掉——训练 checkpoint 之间的时间就全白烧了。
业界这几年一直在打补丁:NVIDIA 搞了 Spectrum-X 做增强 RoCE,AWS 在自家 Nitro 上做了 SRD,Google 自研了 Falcon,Meta 和微软牵头的 UEC(超以太网联盟)也在推类似的方向。每家都在重新发明类似的轮子。
MRC 在干什么
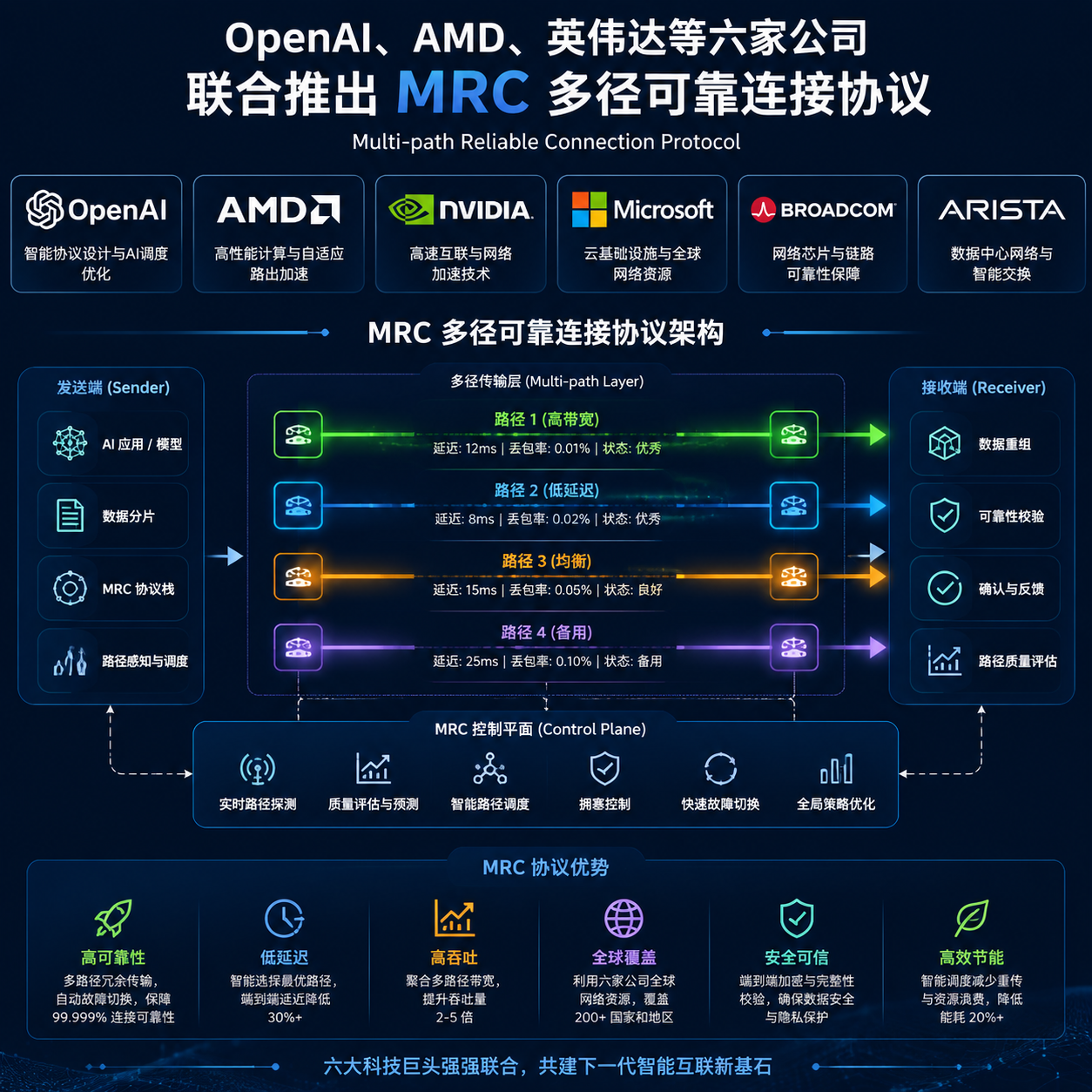
MRC 的核心思路一句话:把"可靠"和"单路径"解绑。
一个逻辑连接拆到多条物理路径上并行跑,做 packet-level 的 spraying;接收端负责处理乱序 packet,而不是像传统 RC 那样一遇到乱序就走 go-back-N;某条路径挂了,只重传这条路径上的那些包,其余路径继续跑。对上层保持 RC 语义,NCCL、RCCL 这些集合通信库不用大改就能接。
换个类比更好理解。传统 RC 像是两地之间只修了一条单行道,车祸一来全线停摆;MRC 是在两地之间开了八车道高速,某条道出事就自动切到其他道,整体吞吐不掉。
具体带来几个直接的好处:
- 带宽利用率上来了。不再依赖 ECMP 哈希撞运气,packet spraying 在硬件层面把流量摊平。
- 尾延迟(tail latency)被压下去。训练集群最怕的就是 P99 延迟抖动,一个 straggler 拖慢整个 step。多径加乱序交付,对付这个很管用。
- 故障影响局部化。单条链路挂了不再触发连接级重建,训练 job 不用动。
- 硬件友好。协议设计上照顾了网卡和交换机的实现复杂度,这也是为什么 AMD、英伟达、博通、英特尔四家芯片厂能同时签字——都得能做。
OpenAI 这次没有公布完整的性能数字,但从协议结构判断,目标就是十万卡以上规模的场景。Stargate 这种量级的基础设施上,1% 的网络利用率差距就是几百张 H200 等效算力。
这个联盟比协议本身更有信息量
看参与方名单会发现一个矛盾:英伟达有 Spectrum-X,AMD 和博通是 UEC 的核心推动者,两边原本是竞争关系。MRC 把他们拉到一起,只能说明一件事——OpenAI 作为甲方的话语权已经到了可以制定游戏规则的程度。
对英伟达来说,Spectrum-X 依然是商业产品,但 MRC 作为开放协议可以和它并行。OpenAI 是它最大的客户之一,这个协议必须支持。对 AMD 和英特尔,这是一次难得的和英伟达站在同一条起跑线上的机会——协议是开放的,谁家网卡支持得好、延迟低、成本优,客户就选谁。对博通,做交换机的它不挑队,只要标准能跑通就行。
微软的角色也关键。Azure 是 OpenAI 最大的算力提供方,MRC 最早大规模落地的地方大概率就是 Azure 的下一代 AI 集群。
至于 UEC,MRC 和它目标高度重合,但路径不同。UEC 想做一整套完整的超以太网规范,摊子铺得大、进度偏慢;MRC 切得更窄,只做"多径可靠传输"这一层,通过 OCP 直接开放,落地速度会快很多。未来两者可能融合,也可能并存一段时间。
对业界意味着什么
过去两年,"AI 工厂"这个词被喊得多,但真正看过集群日志的工程师都知道:一个训练 job 能不能跑完、跑多快,网络层比调度器、比编译器、甚至比部分算法优化都更决定性。
MRC 的出现是一个信号:超算网络这个原本被 InfiniBand 把持、再被各家私有协议切割的市场,开始往开放标准收敛。对云厂商,未来几年升级 AI 集群会有一个明确的采购依据;对芯片厂,网卡 IP 有了统一目标;对训练框架团队,底层通信抖动会少一些——虽然他们大概率还是会继续抱怨 NCCL。
另一个潜台词:OpenAI 在系统层的野心远不止模型本身。从 Stargate 到自研芯片的传闻,再到今天牵头网络协议,它在用一个 AGI 实验室的身份做基础设施公司的事。
对应用开发者来说,这些东西离日常 API 调用很远,但最终会体现在模型迭代速度上——训练一轮 GPT-6 级别的模型少花一周,发布节奏就是不一样。这边顺带一提,OpenAI Hub 仍然保持国内直连调用 GPT、Claude、Gemini、DeepSeek 等主流模型的能力,一个 Key 兼容 OpenAI 格式,适合需要把最新模型快速接入业务的团队。
还剩哪些问号
MRC 披露的是协议层设计,但真正跑起来要看几件事:第一批支持它的网卡什么时候量产,现在看英伟达下一代 ConnectX 和 AMD Pensando 都有可能;交换机侧博通 Tomahawk 系列要不要做适配;NCCL 官方什么时候合入对应 transport——这一步没做,大模型训练团队不会动。
另外,OCP 规范公开后,国内厂商(华为、阿里平头哥、燧原等)有没有跟进的空间,也值得观察。超算网络协议的开放,对追赶者永远是利好。
正式的技术规格文档已经在 OCP 仓库里,感兴趣的工程师可以直接去看报文格式、状态机和重传逻辑,这比官方博客的营销语言信息量大得多。
参考来源
- OpenAI 联合多家企业发布 MRC(多径可靠连接)协议 - linux.do:社区对 OpenAI 联合 AMD、英伟达、英特尔、微软、博通发布 MRC 协议的讨论与原文转述。