Claude 会做梦了:Anthropic 给 Agent 加了个后台推理模式
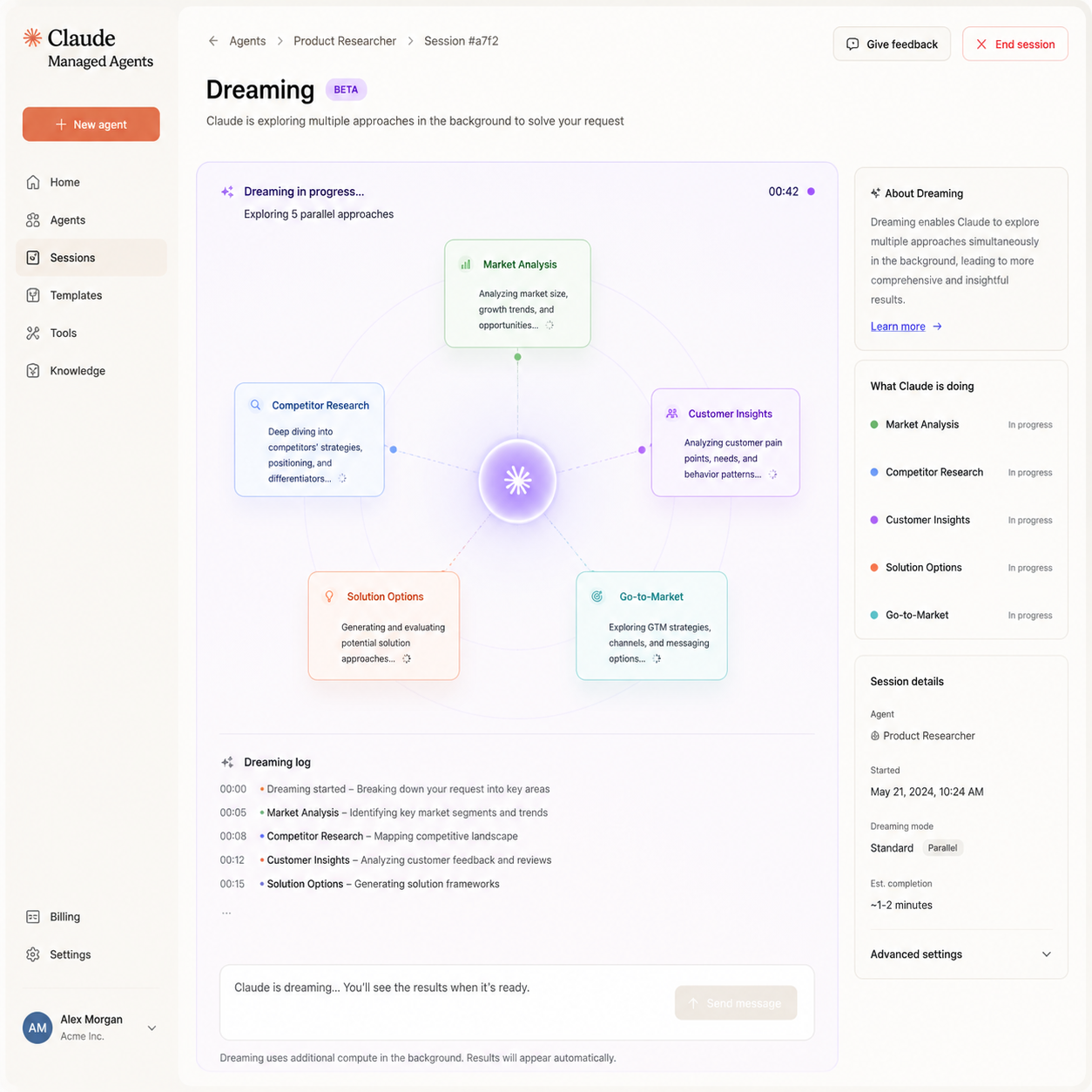
5 月 5 日,Anthropic 给 Claude Managed Agents 上了一个略带文学色彩的新能力——Dreaming(梦境)。字面上听着玄乎,实际做的事其实挺务实:让 Agent 在没有用户输入、处于空闲状态时,自主生成一系列假设场景并在内部把它们走一遍,把推理结果沉淀成可复用的记忆。
同一批更新里还有个对重度用户更直接的好消息——Claude Code 在 Pro 和 Max 套餐下的速率限制直接翻倍。前一条是产品叙事,后一条是真金白银。
先把 Dreaming 这件事讲清楚
官方博客里 Anthropic 用的措辞很克制,说这是一种 "latent rehearsal"(潜在演练)机制。翻译成人话:当一个 Managed Agent 没在处理请求的时候,它不会真的 idle 掉,而是会基于自己最近处理过的任务、访问过的工具、积累的上下文,自己给自己出题。
具体流程大致是这样:
- Agent 根据历史任务的模式,采样出若干"可能即将遇到的场景",比如一个客服 Agent 会模拟客户投诉物流、退款纠纷、产品故障这类场景;
- 对每个场景,它会在内部走一遍完整的推理链,包括调用哪些工具、如何拆解任务、可能卡在哪里;
- 走完之后,把有价值的中间结论——比如某个 API 的调用模式、某个 edge case 的处理方式——写入自己的长期记忆;
- 等真实请求来的时候,它已经"预演"过类似情况,响应更快、判断更准。
这事儿之所以被包装成 "Dreaming",是因为它和认知科学里关于睡眠巩固记忆的假说有点像。人睡着的时候大脑会重放白天的经历,把短期记忆变成长期记忆。Claude 做的事在机制上当然完全不同——它是在用自己生成推理 trace 来喂自己——但效果层面有那么点影子。
Anthropic 强调这不是简单的 "后台跑推理烧算力"。Dreaming 是有预算控制的,每个 Agent 有独立的"梦境配额",可以在管理面板里设上限。而且梦境产生的记忆条目会经过一个 self-critique 环节过滤,不会把模型自己幻想出来的假事实当成真知识沉淀下来——至少官方是这么说的。
这玩意儿到底有没有用
我对这类"仿生"叙事一向警惕,但 Dreaming 放在 Agent 这个产品线上是说得通的。
现在的 AI Agent 普遍有一个痛点:冷启动贵。一个刚部署的 Agent,前几十次对话基本都在"学"——学自己可以调哪些工具、学业务里的术语、学用户的偏好。传统做法是靠运行时积累,用多了自然就熟了。但这对 B 端客户很不友好:企业买一个 Agent 产品,希望第一天就能干活,不是养一个月才见效。
Dreaming 的产品意图,说白了就是把这个"养"的过程搬到后台去。Agent 不用等真实流量,自己就能迭代自己的策略库。这和过去几个月各家在推的 "agentic memory" 是一脉相承的,只不过 Anthropic 这次给了一个更戏剧化的包装。
但要说有没有新东西,也得实事求是。学术界做 "self-play"、"synthetic trajectory generation" 已经好几年了,DeepMind、Meta AI 的论文一堆。Anthropic 把它产品化、放进 Managed Agents,算是工程落地的一步,不算理论突破。真正有价值的在于它暴露了一个可用的商业接口——开发者可以通过 API 控制 Agent 什么时候做梦、做什么梦、做多少梦。这在闭源大模型里还是头一份。
API 层面的变化
对接入 OpenAI Hub 的开发者来说,Dreaming 作为 Claude Managed Agents 的参数暴露出来,调用方式兼容 OpenAI 格式,直接走 /v1/messages 或 Agent 相关端点即可。一个最小化的配置示例:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_OPENAI_HUB_KEY",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="claude-sonnet-4.5",
messages=[
{"role": "system", "content": "你是一个客服 Agent"},
{"role": "user", "content": "帮我查一下订单 #A1029"}
],
extra_body={
"managed_agent": {
"agent_id": "agt_customer_support_01",
"dreaming": {
"enabled": True,
"budget_tokens_per_day": 200000,
"scenarios": ["complaint", "refund", "shipping_query"],
"memory_retention_days": 30
}
}
}
)
print(response.choices[0].message.content)
几个参数值得注意:
budget_tokens_per_day:每天的梦境预算,单位是 token。给得太少梦不出什么,给得太多纯烧钱,Anthropic 给的推荐区间是 50k 到 500k,看业务复杂度。scenarios:可以显式指定你希望 Agent 重点演练的场景类型。不填的话它会基于历史流量自动采样。memory_retention_days:梦境产出的记忆保留多久。短期任务建议设短一点,否则模型会被自己的幻觉带跑。
国内直连调用的话,OpenAI Hub 这边已经把 Managed Agents 的新参数透传支持上了,不需要额外适配。
速率限制翻倍:这个更实在
相比 Dreaming 的概念叙事,Pro 和 Max 用户的 Claude Code 速率限制翻倍是立刻能感知到的变化。
过去几个月,Claude Code 的限流一直是社区吐槽的重灾区。Max 套餐 200 美元一个月,很多重度用户写着写着就被 throttle,得等几小时才能恢复,生产力直接中断。Reddit 的 r/ClaudeAI 上隔三差五就有人开帖抱怨,Anthropic 官方也在工单里承认"需求超出预期"。
这次翻倍意味着:
- Pro 用户(20 美元/月)每 5 小时的消息窗口大约从 45 条提到 90 条;
- Max 用户分两档,5x 和 20x,分别对应相当于 Pro 的 5 倍和 20 倍,现在实际可用额度再乘 2;
- Claude Code 的 agentic 调用(会触发多轮 tool use,消耗比聊天大得多)按新额度结算,这对 vibe coding 的连贯性提升明显。
顺带解释一下为什么这次能翻倍。过去半年 Anthropic 在推理层做了不少优化——包括把 Sonnet 级别的模型在自己的 TPU 集群上跑、优化 KV Cache 复用、把 Agent 场景下重复的 system prompt 做 prefix cache 命中。这些省下来的算力,一部分让给了老用户。
放到 Anthropic 这半年的节奏里看
这次更新不是孤立事件。Reddit 上有人统计过,Anthropic 在 52 天内发布了 74 个产品更新,平均每天一个多。密度比 OpenAI 同期还高。
几条值得拉出来看的主线:
- Claude Cowork 普遍开放:原来只给 Enterprise 的多人协作 Agent 能力,已经下沉到所有付费计划,带企业控制、RBAC、消费上限、OpenTelemetry 可观察性和 Zoom connector。这摆明是奔着抢 Copilot Studio 和 ChatGPT Enterprise 的地盘去的。
- Managed Agents 体系成型:从最初的 Claude Agents SDK,到现在的 Managed Agents + Dreaming + Cowork,Anthropic 正在把 Agent 做成一个一等公民产品,而不是 "在 API 上包一层"。
- Claude Code 生态化:泄漏的源码显示它是用 TypeScript + React(Ink)构建的终端 Agent 操作系统,而不是简单的 LLM 命令行包装。这个架构决定了它能很快接更多 MCP server,生态起量速度会继续拉开和竞品的差距。
把这几条连起来看,Anthropic 的打法已经很清楚——不和 OpenAI 卷通用聊天,卷开发者工具链和企业 Agent。Dreaming 这个功能,单拿出来看是锦上添花,放到整个产品矩阵里看,是在给 "Agent 比模型更重要" 这个论点加筹码。
几个还没解决的问题
最后提几点我看完文档后的疑问,可能是下一阶段要观察的:
- 梦境的幻觉污染风险:self-critique 能过滤多少假知识?如果 Agent 梦到一个不存在的 API 签名并记住了,真实请求来的时候会不会坚持错误答案?Anthropic 没公开具体的 gating 机制。
- 成本归因:梦境消耗的 token 怎么计费?按官方说法是算在用户账单里,但具体展示粒度和能不能分账到 Agent 级别,文档还比较模糊。
- 跨 Agent 记忆污染:如果一个租户下有多个 Managed Agents,梦境记忆会不会串?企业场景下这是硬需求。
这些问题没答案之前,我个人的建议是:先在非关键业务的 Agent 上打开 Dreaming,预算给小一点,观察两周再决定要不要推到生产。好东西,但别头铁。
参考来源
- Reddit r/ClaudeAI:Anthropic 52 天发布 74 个产品更新的讨论帖 — 社区对近期 Anthropic 产品节奏的梳理,包括 Cowork 普遍开放的细节