Gemma 4:谷歌开源模型的真正成人礼

谷歌发布 Gemma 4 系列四款开源模型,首次采用 Apache 2.0 协议,从树莓派到工作站全覆盖,31B Dense 杀入开源前三,26B MoE 以极低激活参数逼近千亿级模型表现。
谷歌终于把「开源」两个字写实了
北京时间 4 月 3 日凌晨,谷歌正式发布 Gemma 4 系列模型。四款规格,Apache 2.0 协议,全面开源。
这句话值得拆开说。Gemma 系列已经迭代两年,下载量超过 4 亿次,衍生模型变体超 10 万个——数字很好看,但圈内一直有个心照不宣的共识:之前的 Gemma 只能算「开放」,不算「开源」。你能下载,能本地跑,但再分发受限,修改后也不能随便传播。对于想基于它做商业产品的开发者来说,这些限制是实打实的绊脚石。
这次 Apache 2.0 一步到位,意味着你可以随便改、随便用、随便卖。谷歌在开源协议上的态度转变,与其说是慷慨,不如说是被 Llama 和 DeepSeek 逼到了墙角——Meta 的 Llama 系列早就在开源社区建立了深厚的开发者心智,DeepSeek 更是以极致性价比在国内市场攻城略地。谷歌如果继续在协议上扭扭捏捏,Gemma 的生态位只会越来越尴尬。
所以这次不是谷歌变大方了,是市场不给它犹豫的空间了。
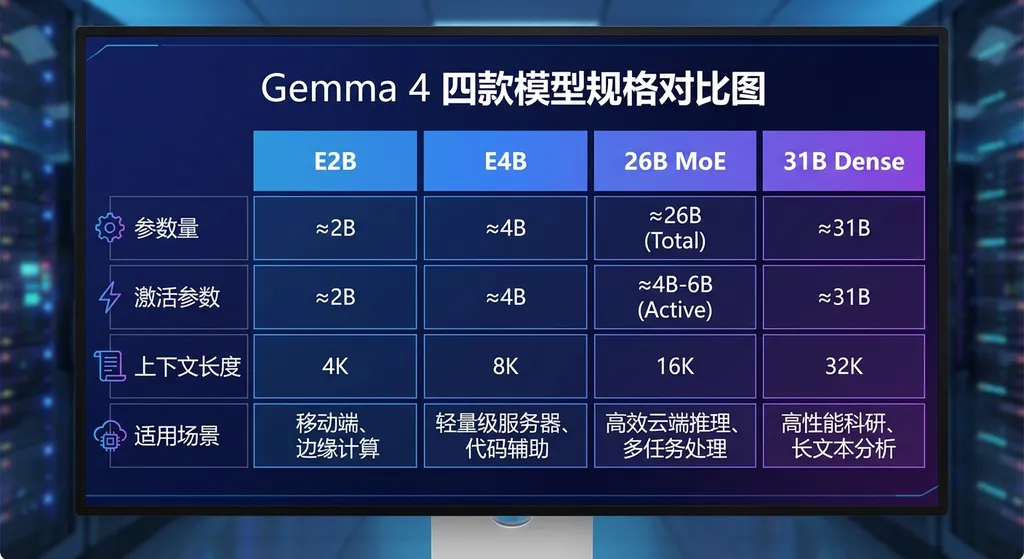
四款模型,四个定位
Gemma 4 这次一口气放出四个规格,覆盖从 IoT 设备到开发工作站的完整硬件光谱。逐个看:
E2B / E4B:手机和边缘设备的「本地大脑」
这两款是专门为端侧场景设计的。E2B 是高效 20 亿参数版,E4B 是高效 40 亿参数版。谷歌和 Pixel 团队、高通、联发科做了深度联合优化。
关键参数:
- 128K 上下文窗口
- 支持图片、视频和原生音频输入
- 可在 Pixel 手机、树莓派、Jetson Orin Nano 上完全离线运行
- 延迟接近于零
「树莓派上跑大模型」这个说法听起来像噱头,但如果你做过 IoT 项目就知道,边缘设备上能跑一个支持多模态输入、128K 上下文的模型,意味着很多之前必须联网回传云端的场景可以完全本地化了。工厂质检、智能家居、车载语音——这些场景对延迟和隐私的要求极高,E2B/E4B 正好切中这个需求。
而且别忽略「原生音频输入」这个能力。不是先 ASR 转文字再喂给模型,而是模型直接理解音频。这在端侧场景里省掉了一整个 pipeline 的延迟和算力开销。
26B MoE:精算师型选手
26B 混合专家模型(MoE),总参数 260 亿,但推理时只激活 3.8B。
这个架构的好处很直观:你拥有 26B 模型的知识容量,但只付 3.8B 的推理账单。对于日调用量在十万次以上的生产场景,这个差距是真金白银。
性能方面,Arena AI 文本评分 1441,开源模型排名第六。更值得注意的是,这个分数接近 Qwen3.5-397B-A17B——后者的总参数量是它的 15 倍。用不到二十分之一的参数量逼近对手的效果,MoE 架构的效率优势在这里体现得淋漓尽致。
上下文窗口拉到了 256K,支持 140+ 语言,原生支持函数调用(function calling)和结构化输出。函数调用让模型能直接对接外部工具——查数据库、调 API、执行代码;结构化输出则确保返回的 JSON 格式严格可控,方便下游系统解析。这两个能力组合在一起,基本就是为 Agent 工作流量身定做的。
31B Dense:暴力美学
310 亿参数,全部激活,不玩花活。
Arena AI 文本评分 1452,开源模型排名第三。这个分数和体量在 600B 以上的 GLM-5 处于同一梯队。Google DeepMind CEO Demis Hassabis 在 X 上只发了一条简短消息,但 31B Dense 的榜单表现替他把话说完了。
同样是 256K 上下文、140+ 语言、函数调用和结构化输出。和 26B MoE 的区别在于:Dense 架构每次推理都全量激活所有参数,推理成本更高,但上限也更高。如果你的场景对质量要求极致——比如复杂的多步推理、长文档分析、高难度代码生成——31B Dense 是更稳的选择。
26B MoE vs 31B Dense:选错了,账单或延迟总有一个让你难受
这两个模型参数量差距不到 20%,但跑起来完全是两回事。
简单算一笔账:
- 26B MoE 推理时激活 3.8B 参数,31B Dense 激活 31B 参数
- 同样的 GPU,MoE 的吞吐量大约是 Dense 的 5-8 倍
- MoE 的单次推理延迟大约是 Dense 的 1/4 到 1/3
但 MoE 不是万能的。混合专家架构的特点是「术业有专攻」——不同的 token 会被路由到不同的专家网络处理。对于标准化任务(摘要、分类、简单代码生成、信息提取),MoE 的路由机制能高效匹配合适的专家,性价比极高。但对于需要全局深度推理的复杂任务,Dense 架构的「所有参数一起想」反而更有优势。
给个简单的决策框架:
- 日调用量 > 10 万次,任务相对标准化,延迟敏感 → 26B MoE
- 任务复杂度高,对输出质量要求极致,调用量可控 → 31B Dense
- 预算有限但想要最好的质量 → 先用 MoE 跑通 pipeline,把省下来的钱投到 Dense 处理关键任务
实际上,很多团队最终会两个都用:MoE 做初筛和批量处理,Dense 做精细任务和兜底。这也是为什么兼容 OpenAI 格式的 API 聚合服务越来越重要——你需要在不同模型之间灵活切换,甚至配置「主模型挂了自动降级」的策略,而不是为每个模型维护一套独立的调用逻辑。
技术细节:Gemini 3 的技术下放
谷歌明确表示,Gemma 4 基于与 Gemini 3 相同的研究和技术体系构建。这不是客套话——从实际表现看,Gemma 4 确实继承了 Gemini 3 的几个核心能力:
多步规划与复杂逻辑推理:这是 Agent 场景的基础能力。模型需要理解目标、拆解步骤、在执行过程中根据反馈调整计划。Gemma 4 在这方面的表现,从 Arena AI 的评分来看,已经达到了和闭源模型竞争的水平。
原生多模态:不是后期拼接的多模态,而是训练阶段就融合了文本、图像、视频、音频的理解能力。E2B/E4B 支持音频直接输入,26B 和 31B 支持文本和图像输入。
140+ 语言支持:对于做国际化产品的团队来说,这意味着一个模型就能覆盖绝大多数语言市场,不需要为每种语言单独微调。
函数调用与结构化输出:这两个能力是 2025 年以来开源模型竞争的关键战场。函数调用让模型从「只能聊天」进化到「能干活」,结构化输出让模型的输出可以被程序可靠地解析和使用。Gemma 4 在这两项上的原生支持,大幅降低了开发者构建 Agent 应用的门槛。
开源生态的格局变化
Gemma 4 的发布,让开源模型的竞争格局又热闹了一层。
目前开源模型的第一梯队大致是这样的:
- Meta Llama 系列:社区最大,生态最成熟,但最新版本在推理能力上开始被追赶
- DeepSeek 系列:性价比之王,在国内开发者中渗透率极高
- Qwen 系列:阿里出品,中文场景表现突出,参数规格覆盖广
- Mistral 系列:欧洲代表,MoE 架构的先行者
- Gemma 系列:之前因为协议限制一直在「开放」和「开源」之间暧昧,现在终于站到了开源阵营
Gemma 4 的加入,最直接的冲击对象是 Qwen 和 Mistral。在 30B 左右的参数量级,31B Dense 的 Arena AI 评分已经是开源第三,这个位置之前属于 Qwen 系列。而 26B MoE 的架构和定位,则和 Mistral 的 Mixtral 系列形成正面竞争。
但更深层的变化在于:谷歌终于愿意把自己最好的技术(Gemini 3 同源)以真正开源的方式释放出来。这对整个开源 AI 生态是利好——竞争越激烈,开发者的选择越多,模型的质量提升越快。
对开发者意味着什么
如果你正在做 AI 应用开发,Gemma 4 值得认真评估的场景包括:
边缘部署:E2B/E4B 是目前开源模型里端侧能力最强的选项之一。如果你的产品需要在手机、IoT 设备上离线运行 AI 能力,这两个模型应该进入你的候选列表。
Agent 工作流:原生函数调用 + 结构化输出 + 256K 上下文 + 多步推理,这套组合对于构建 Agent 应用来说几乎是标配。26B MoE 和 31B Dense 都能胜任。
多模型架构:在生产环境中,越来越多的团队采用多模型混合架构——不同任务路由到不同模型,主模型故障时自动降级到备选模型。Gemma 4 兼容 OpenAI 格式的 API 接口,可以无缝接入现有的调用链路。通过 OpenAI Hub 这类 API 聚合平台,一个 Key 就能调用 Gemma 4 和其他主流模型,在模型之间切换的成本几乎为零。
成本优化:如果你目前在用闭源模型(GPT-4o、Claude Sonnet 等)处理大量标准化任务,26B MoE 的性价比值得测试。激活参数只有 3.8B,但效果逼近百亿级模型,迁移过来可能省下一大笔推理费用。
冷静看几个问题
说了这么多好的,也得泼点冷水。
第一,Arena AI 的评分不是万能指标。它主要反映模型在对话场景下的综合表现,但你的实际任务可能是代码生成、数据提取、长文档分析——这些细分场景的表现需要自己跑 benchmark 验证。
第二,MoE 架构虽然推理便宜,但微调成本不低。如果你需要在 Gemma 4 26B MoE 上做全量微调,实际需要加载的参数量还是 26B,显存需求并不比 31B Dense 少多少。LoRA 微调倒是可以只动部分参数,但效果能不能达到预期,取决于你的具体任务。
第三,E2B/E4B 在端侧的实际表现,还需要等更多开发者的真实反馈。「树莓派上能跑」和「树莓派上跑得好用」是两回事。128K 上下文在端侧设备上的实际推理速度、内存占用、发热情况,这些都需要实测数据。
第四,谷歌的开源模型生态建设一直是短板。Llama 有 Meta 持续投入的社区运营,DeepSeek 有国内开发者的自发传播,Gemma 之前虽然下载量大,但社区活跃度和二次开发的深度都不算突出。Apache 2.0 协议是个好的开始,但生态的繁荣需要的不只是一个协议。
写在最后
Gemma 4 是谷歌在开源模型赛道上迟来但有诚意的一步。Apache 2.0 协议解决了最大的合规顾虑,四款规格覆盖了从树莓派到工作站的完整场景,31B Dense 的性能直接杀入开源前三。
但开源模型的竞争从来不只是跑分。生态、社区、工具链、微调便利性——这些「软实力」才是决定一个开源模型能不能真正被用起来的关键。谷歌有技术,有资源,现在也有了正确的协议。接下来就看它愿不愿意像 Meta 经营 Llama 那样,真正投入精力去建设 Gemma 的开发者社区。
对开发者来说,多一个强力选手入场永远是好事。建议先在自己的实际任务上跑一轮对比测试,用数据说话,别被榜单牵着走。
参考来源
- 以小小小小胜大!Google 最强小模型刚刚发布 — 详细解读 Gemma 4 四款模型的定位与性能对比
- Google 开源模型参数差 8 倍,开发者选哪个栽了 — 26B MoE vs 31B Dense 的选型分析
- 谷歌推出最强手机端开源模型 Gemma4 E2B/E4B — 端侧模型能力解读
- 新华社:谷歌发布开源模型 Gemma 4 — 官方发布信息
- Gemma 4 现已发布:同等规模下性能最强的开放模型 — 谷歌官方博客中文翻译
- 谷歌发布 Gemma 4 开源大模型(新浪财经) — 四种规格概览
