Sub2API 加了审计功能,但开发者被 OpenAI 的绑卡门槛挡在外面
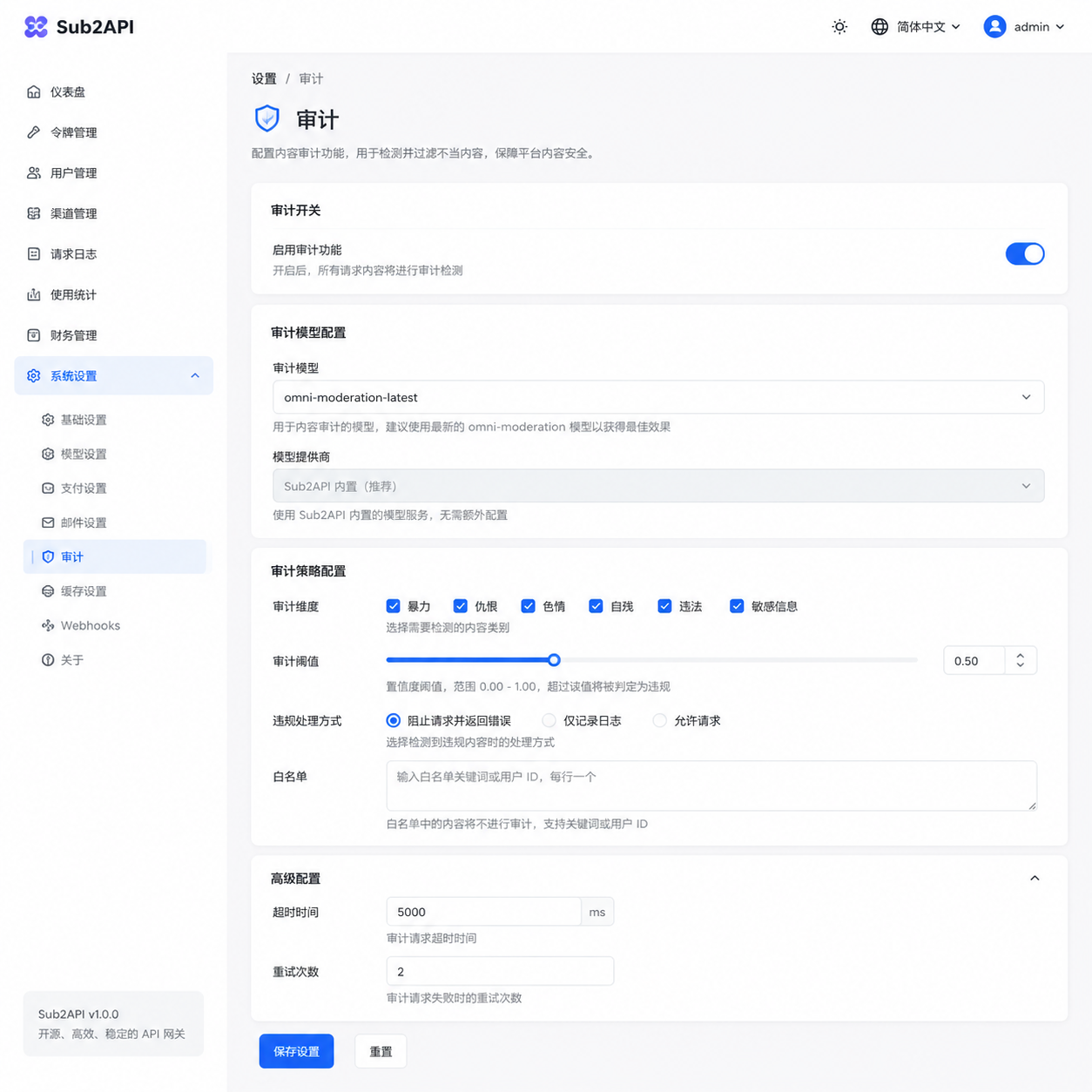
Sub2API 今天的更新里悄悄加了一项审计功能,设置面板默认挂着 OpenAI 的 omni-moderation-latest。价格一栏写着免费,听起来没什么门槛,但实际上得有 OpenAI API Platform 的账号并完成绑卡——这两步放在国内开发者面前就变成了拦路石。linux.do 上很快有人发帖,问"有没有佬有这个模型的渠道"。问题很短,背后折射的是整个国内 AI 工具链生态里一个长期的小毛病:中间件越来越完善,但底层依赖的关键模型反而越来越难拿到。
这次更新到底改了什么
Sub2API 是典型的 API 代理/订阅管理工具,做的事情是把一堆散落的上游 API 聚合起来,对外暴露统一的 OpenAI 兼容接口。之前它主要在模型路由、鉴权、速率限制、用量统计这些层面做文章。这次加入审计(moderation)是往合规这块延伸了一步,属于意料之中的动作——任何做 API 分发的平台,只要用户体量起来,合规审查就绕不过去。不加审计,上游模型厂商一旦发现违规流量,整个 Key 都可能被封。
审计功能的位置放在请求链路的中间:用户请求进来,先过一遍审核模型,命中敏感类别的直接拒绝或打标签,再转发给下游 LLM。这个模式不是 Sub2API 原创,Cloudflare AI Gateway、LiteLLM、one-api 的一些分支都有类似设计。区别在于审计模型本身选什么。
Sub2API 选了 omni-moderation-latest 做默认值。这是 OpenAI 在 2024 年底推出、之后持续迭代的多模态审核模型,最大的卖点是两个:
- 多模态:文本 + 图片都能过,这对现在动不动就要处理 vision 输入的应用来说是刚需
- 免费:OpenAI 对 moderation endpoint 不计费,调多少次都是 0
这组合放在中间件默认值的位置上非常合适。免费意味着平台方不用替用户兜底成本,多模态意味着覆盖面广。换作任何一个做 API 网关的作者,默认值大概率也会这么选。
omni-moderation-latest 到底是个什么东西
简单说,它是 OpenAI 把原来纯文本的 text-moderation 升级成了多模态版本。能识别的类别大致涵盖暴力、自残、性相关、仇恨、骚扰、非法行为这几大块,每一类还分细粒度子类(比如暴力里再分出涉及未成年人的部分),每一项返回一个 0 到 1 的置信度分数,同时给一个布尔标签。
技术架构层面,OpenAI 没有公开细节,但从行为推测应该是一个共享视觉编码器的多任务分类器。响应速度很快,典型 P95 在 300ms 以内,比走一轮 GPT-4o 要便宜得多(时间上和 token 上都是)。
它的定位也很清楚:不是用来做内容生成的,也不是给业务端直接做决策的"道德法官"。OpenAI 官方文档反复强调,moderation API 的输出应该作为信号,最终 policy 还是由应用方自己定——阈值怎么设、命中后怎么处理、要不要人工复核,这些平台自己决定。
放在 Sub2API 的场景里,这种模型刚好对口:平台不需要精准判定内容好坏,只需要在上游模型厂商追责时有一层"我已经过审"的挡板。omni-moderation-latest 足够便宜(免费)、足够快、覆盖类别足够全,正好满足这个需求。
免费为什么反而成了问题
帖子里那句"免费的,但是需要 OpenAI API Platform 绑卡才能用",是整个话题的痛点。
国内开发者想拿到 OpenAI API 的直接使用权,要跨过的不只是技术门槛:
- 账号注册要非中国大陆、非港澳的手机号
- 付款绑卡需要境外银行卡或支持的虚拟卡,且 OpenAI 对某些虚拟卡供应商做了黑名单
- IP 风控整个调用链要稳定走非受限地区 IP,否则账号随时可能被标记
- 封号风险就算前面都过了,也有人用了几个月突然被封,Key 一起失效
对一个只是想在中间件里跑审计的开发者来说,这条链路的维护成本远远超过了"模型本身免费"带来的收益。结果就是:越是基础设施级别的免费工具,越要付费聚合平台帮忙拿。这是一个有点反直觉但非常现实的局面。
linux.do 那个帖子底下,搜"omni-moderation 渠道"的不只一个人。这说明 Sub2API 这次更新后,一批之前没碰过 moderation 的用户突然开始需要这个模型——但他们并不是要直接和 OpenAI 打交道的那拨人。对他们来说,模型是不是 OpenAI 出的其实不重要,重要的是"Sub2API 设置里那个下拉框能选中的值能跑通"。
几种实际可行的替代路径
既然直连 OpenAI 困难,社区里绕路的方式其实不少,各自有取舍。
走 API 聚合平台。这是最省事的办法。像 OpenAI Hub 这类聚合服务,一个 Key 可以同时调 GPT、Claude、Gemini、DeepSeek 等主流模型,兼容 OpenAI 格式,国内直连。moderation 这种辅助 endpoint 通常也会一起支持,改一下 Sub2API 里的 base_url 指向聚合平台就能跑通,不用自己折腾账号绑卡。对于大部分只是想让 Sub2API 审计功能动起来的用户,这条路摩擦最小。
用其他审核模型替代。这块选项比一年前丰富多了:
- Azure Content Safety:微软的内容审核服务,支持文本和图像,分类维度和 OpenAI 接近,在国内有可用的渠道,按调用量计费
- Perspective API:Google Jigsaw 的,主要针对"毒性"(toxicity)维度,免费额度宽松但分类不如 omni-moderation 细
- Llama Guard 3 / Llama Guard 4:Meta 开源的审核模型,可自部署,4 版本加了多模态支持,本地跑的话成本完全可控
- Qwen / GLM 系列的审核特化版本:国内厂商自己出的审核模型,中文语境下表现往往比 OpenAI 的更好,合规性也更稳
如果业务是中文为主,其实 Llama Guard 或国产审核模型在效果上未必比 omni-moderation-latest 差。OpenAI 的模型在英文以外语境里精度会掉,这是老问题。它的 harassment 分类器对中文谐音、拼音、拆字这些规避手段识别率相当一般,拿去做中文社区审核会漏掉一大半。
自建小模型。用 BERT、DeBERTa 之类的轻量架构自己训一个分类器,针对业务里最容易翻车的几个类别做定向拦截。成本是数据标注和训练时间,收益是完全可控、延迟最低、没有任何外部依赖。适合调用量大、对审核延迟敏感的场景——比如实时聊天、直播弹幕这类每秒几百上千次调用的地方,走外部 API 根本扛不住。
一个更值得思考的问题
Sub2API 默认挂 omni-moderation-latest,某种程度上反映了一种惯性——OpenAI 的免费 endpoint 仍然是很多中间件工具的"默认选项",哪怕国内拿到它并不容易。这不是 Sub2API 的问题,是整个开源 API 工具链的生态位问题:作者往往生活在一个可以直连 OpenAI 的环境里,默认值按自己方便设定,用户侧的摩擦要到 issue 区才会浮现。
从趋势上看,有两件事值得关注:
一是 OpenAI 的 moderation endpoint 今年会不会被拆分成付费 tier。官方免费政策从 GPT-3 时代一路延续到现在,但随着 omni-moderation 加入图片审核,成本结构已经和纯文本时代不一样了。图片推理的 GPU 开销不低,继续完全免费对 OpenAI 来说是一笔不小的补贴。如果某天改成按调用量计费,Sub2API 这类工具的默认选择就得重新洗牌。
二是国产审核模型会不会出现一个真正的 "omni-moderation 替代品"。现在的候选都偏专用——要么只做中文毒性,要么只做版权,要么只做儿童安全。缺一个统一接口、覆盖多模态、免费或极低成本的选择。一旦出现,社区工具链的默认值会很快迁移。这个位置其实挺适合某个大模型厂商顺手补一下的——从商业角度看,审核接口是获取用户、培养生态依赖的好入口。
开发者现在能做什么
短期内最务实的做法:
- 如果只是想让 Sub2API 的审计功能先跑起来,选一个能调通 moderation endpoint 的聚合平台换掉 base_url,几分钟搞定
- 如果业务是生产环境、调用量大,花时间调研一下 Azure Content Safety 或自建 Llama Guard,长期成本和可控性都更好
- 如果主要做中文业务,不要默认相信 omni-moderation 的分数,自己拿业务语料跑一批测试集对比国产模型,很可能会得到相反的结论
- 阈值不要用 OpenAI 官方文档里那个 0.5 默认值,根据你业务的召回/精准率需求重新调一遍,大部分场景真正合适的值会低得多
Sub2API 这次更新本身是好事,审计该有的能力终于补上了。只是默认模型背后的门槛,让这次"顺手补功能"的改动,在国内社区里变成了一个略带尴尬的讨论话题——而这样的讨论,其实每一次 OpenAI 生态有新动向的时候都会重演一遍。问题不会自己消失,但绕路的方式会越来越成熟。
参考来源
- 有没有佬有 omni-moderation-latest 这个审计模型的渠道 - linux.do — 社区原帖,Sub2API 更新后用户对获取审计模型渠道的讨论